
Indice dei contenuti dell'articolo:
Ogni webserver pubblicamente esposto su Internet è, per definizione, una superficie d’attacco. Non importa che si tratti di un grande e-commerce, di una piccola API REST, di un pannello amministrativo, di un endpoint usato da un’app mobile o di un semplice sito vetrina: dal momento in cui un servizio risponde su una porta pubblica, qualcuno proverà a interrogarlo, enumerarlo, stressarlo o attaccarlo.
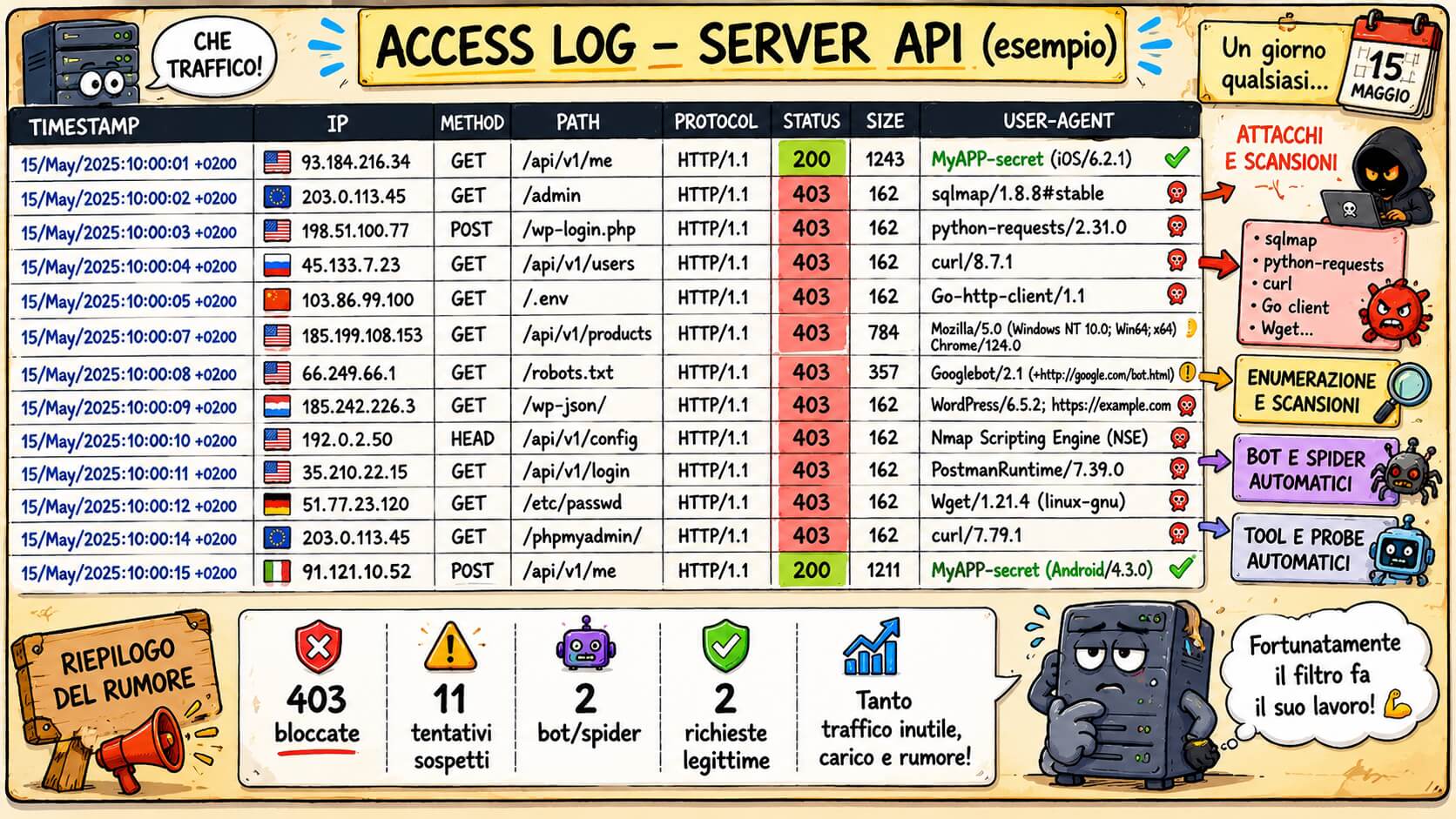
Questa non è una possibilità teorica, ma una condizione ordinaria dell’esposizione su Internet. I log di qualunque server HTTP pubblico raccontano sempre la stessa storia: richieste verso percorsi inesistenti, tentativi di accesso a file di configurazione, scansioni automatiche alla ricerca di CMS vulnerabili, chiamate a endpoint noti di WordPress, Joomla, Drupal, Magento, Laravel, phpMyAdmin, pannelli di amministrazione, vecchie CGI, script PHP dimenticati, directory .git, file .env, backup compressi, dump SQL e molto altro.
Nella migliore delle ipotesi, se il sistema è ben configurato e non vulnerabile, tutte queste richieste si concludono con un 404, un 403 o un semplice rifiuto. Ma anche quando l’attacco fallisce, qualcosa è comunque accaduto: il server ha ricevuto traffico, ha aperto connessioni, ha consumato CPU, memoria, banda, I/O, capacità di logging e attenzione operativa. In altre parole, anche il rumore ha un costo.
Il problema del traffico ostile, inutile o non desiderato
La sicurezza non riguarda solo il blocco dell’exploit riuscito. Riguarda anche la riduzione dell’esposizione, del rumore operativo e del carico generato da tutto ciò che non ha alcuna ragione legittima di interrogare un determinato servizio.
Un endpoint API progettato per essere usato esclusivamente da una specifica applicazione mobile, da un’estensione Chrome o da un client proprietario non ha necessariamente bisogno di rispondere allo stesso modo a qualunque bot, scanner, script Python, programma Go, curl, spider AI non autorizzato o crawler generico che lo incontra durante una scansione casuale della rete.
Il punto non è illudersi che si possa rendere invisibile un servizio pubblico. Se un server è raggiungibile su Internet, può essere scoperto. Tuttavia, tra “pubblico e completamente aperto a qualunque richiesta” e “privato dietro VPN o rete interna” esistono molte sfumature intermedie. Una di queste, in contesti molto selezionati, è l’uso dello User-Agent come filtro applicativo aggiuntivo.
Che cos’è lo User-Agent
Lo User-Agent è un header HTTP inviato dal client al server per identificare, almeno formalmente, il software che sta effettuando la richiesta. Un browser può presentarsi come Chrome, Firefox, Safari o Edge. Un bot può presentarsi come crawler. Uno script può dichiararsi come curl, Python-requests, Go-http-client, Java, axios, PostmanRuntime o qualsiasi altra stringa.
È importante sottolineare subito un aspetto: lo User-Agent non è un’identità sicura. È un’informazione dichiarata dal client e, in quanto tale, può essere falsificata con estrema facilità. Chiunque può inviare una richiesta HTTP impostando arbitrariamente lo User-Agent desiderato.
Questo però non significa che lo User-Agent sia completamente inutile. Significa semplicemente che non deve essere trattato come una prova crittografica di autenticità. Non è una password, non è un token, non è un certificato client, non è una firma digitale. È però un segnale, e come tutti i segnali può essere usato in modo intelligente all’interno di una strategia di difesa a più livelli.
L’idea: accettare solo client conosciuti
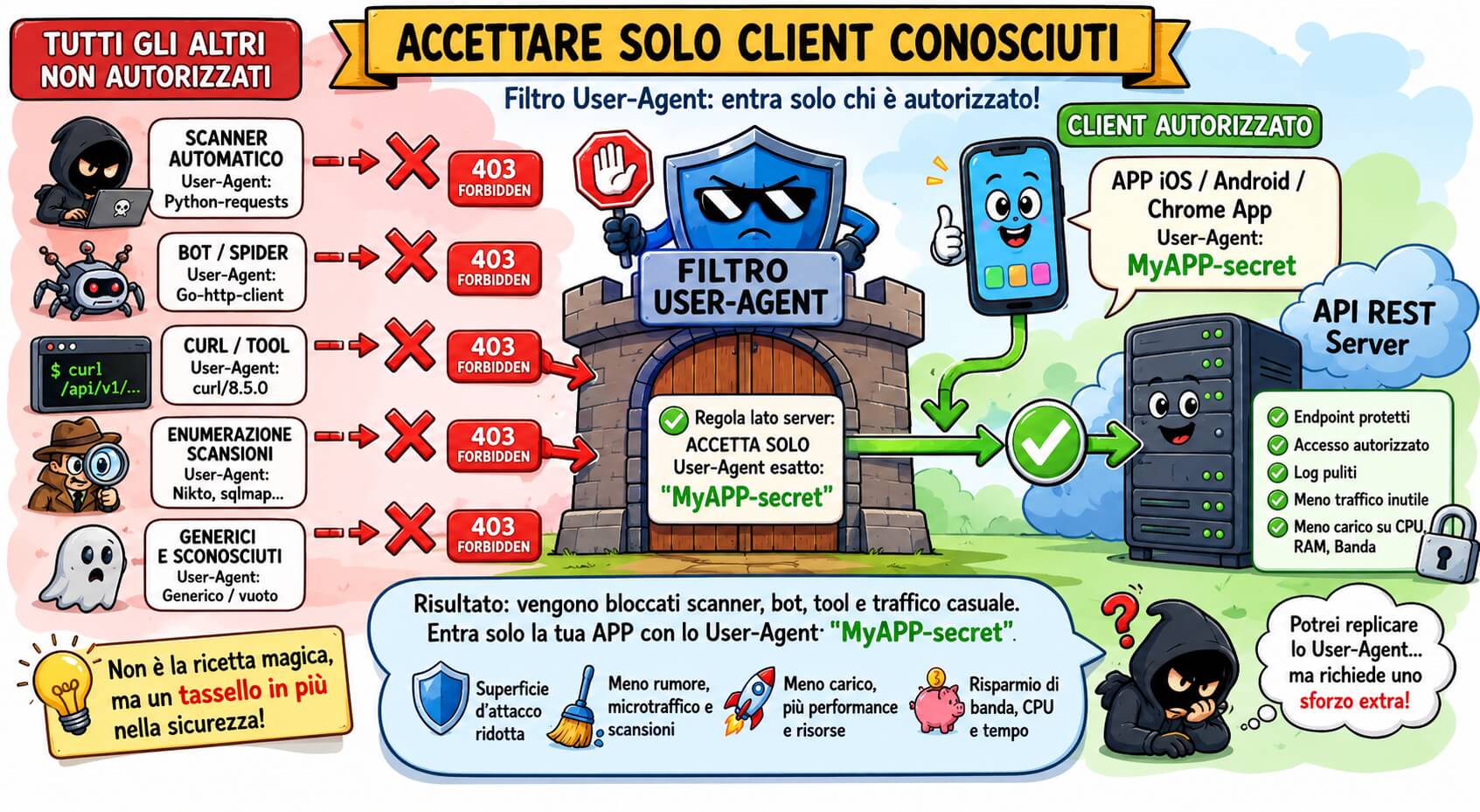
Immaginiamo un caso concreto. Una determinata app iOS, Android o una Chrome App comunica con un server remoto tramite API REST. Non si tratta di API pensate per essere consumate liberamente da sviluppatori terzi o da utenti generici. Sono endpoint dedicati a quella specifica applicazione.
In questo scenario, l’app potrebbe inviare uno User-Agent personalizzato, ad esempio:
MyAPP-secret
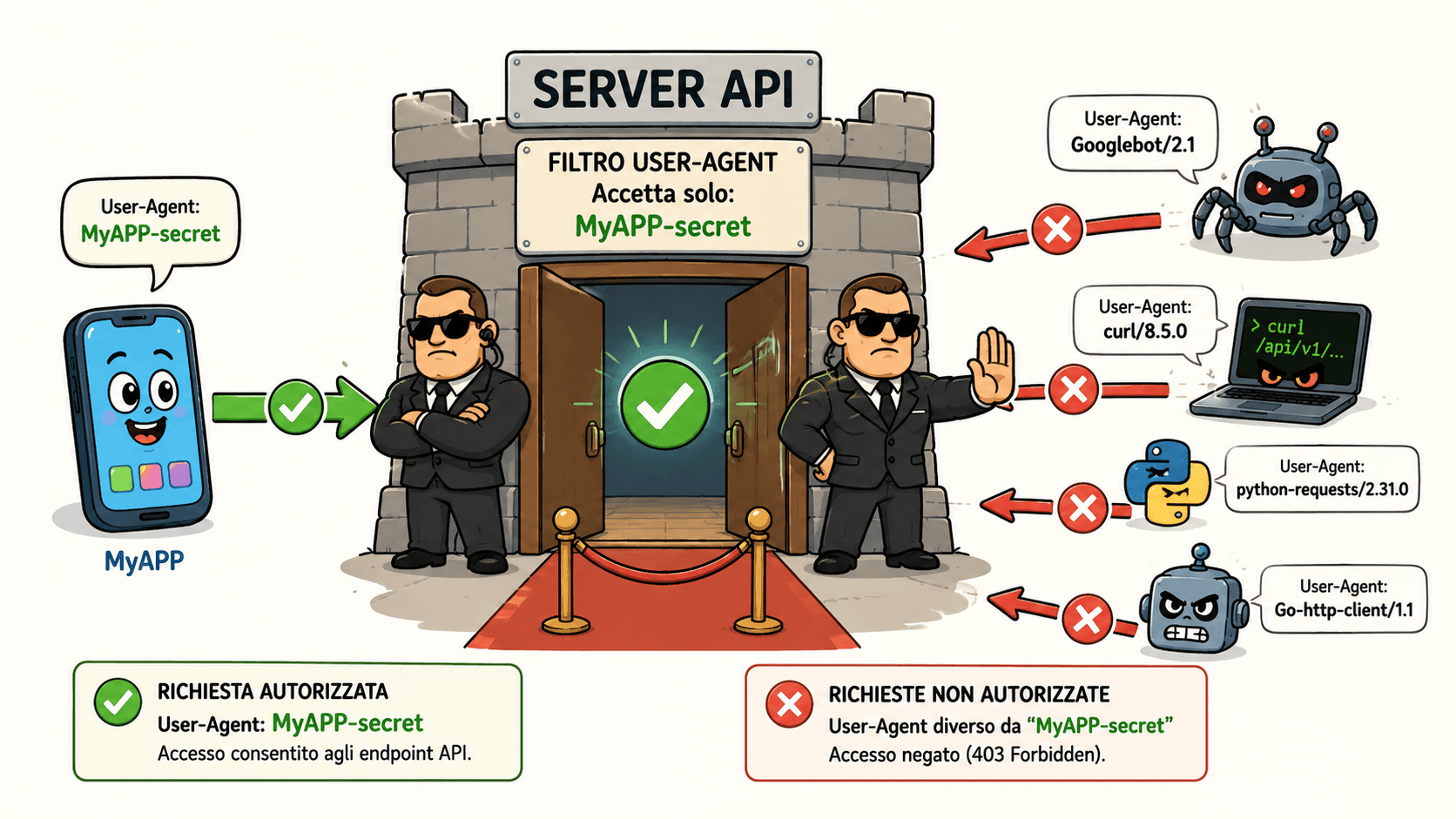
Lato server, gli endpoint API potrebbero essere configurati per accettare solo richieste che presentano esattamente quello User-Agent, rifiutando tutte le altre con un brutale e immediato codice HTTP 403 Forbidden.
Il risultato è semplice: chi arriva con curl, con Python-requests, con Go-http-client, con uno scanner automatico o con uno User-Agent generico viene tagliato fuori prima ancora di raggiungere la logica applicativa più costosa o sensibile.
Naturalmente, un attaccante determinato potrebbe analizzare il traffico dell’app, effettuare reverse engineering, intercettare le richieste, osservare lo User-Agent usato e replicarlo. Questo è vero. Ma la sicurezza non è sempre un gioco binario tra impossibile e triviale. Spesso è una questione di aumento del costo dell’attacco.
Molti attacchi su Internet non sono mirati, manuali e sofisticati. Sono automatismi su larga scala. Scanner che provano milioni di IP. Bot che cercano pattern noti. Script che tentano percorsi comuni. Tool che enumerano applicazioni vulnerabili sulla base della legge dei grandi numeri: prima o poi, da qualche parte, qualcosa risponderà male.
Contro questo tipo di rumore massivo, un filtro basato su User-Agent può avere un effetto pratico significativo.
Non è “la” sicurezza, ma può essere un tassello
Il punto fondamentale è evitare equivoci: il controllo dello User-Agent non deve mai essere venduto, progettato o percepito come una misura di sicurezza principale.
Non sostituisce l’autenticazione.
Non sostituisce l’autorizzazione.
Non sostituisce HTTPS.
Non sostituisce API key, token, HMAC, OAuth, JWT o mTLS.
Non sostituisce un WAF.
Non sostituisce il rate limiting.
Non sostituisce una corretta validazione dell’input.
Non sostituisce il logging, il monitoraggio e l’hardening del sistema.
Ma può aggiungere un livello di selezione preliminare. Può essere una sorta di “porta esterna” estremamente economica, pensata non per fermare il ladro professionista con gli strumenti giusti, ma per impedire che ogni passante, bot o scanner casuale entri nel cortile e inizi a bussare a tutte le porte interne.
In sicurezza informatica, i livelli contano. Una singola misura raramente è sufficiente. Ma più barriere semplici, coerenti e ben progettate possono ridurre in modo sensibile la superficie esposta, il rumore di fondo e la probabilità che un errore applicativo venga raggiunto facilmente.
Riduzione della superficie d’attacco percepita
Tecnicamente, il server rimane pubblico. Quindi non si riduce la superficie d’attacco nel senso più rigoroso del termine, perché l’endpoint è ancora raggiungibile via rete. Tuttavia si riduce la superficie applicativa accessibile ai client non autorizzati.
La differenza è importante. Un bot che invia una richiesta casuale verso /api/v1/users, /login, /admin, /wp-json/, /vendor/phpunit/, /debug, /config, /actuator/env o altri percorsi tipici di enumerazione può essere bloccato a monte, senza passare attraverso tutta la catena applicativa.
Se il controllo dello User-Agent viene implementato a livello di webserver, reverse proxy o middleware molto leggero, la richiesta può essere respinta prima di coinvolgere PHP-FPM, Node.js, Python, Java, il database o altri componenti più costosi.
Questo significa meno carico CPU, meno memoria occupata, meno query inutili, meno log applicativi sporchi, meno alert falsi, meno rumore nei sistemi SIEM e una maggiore pulizia complessiva dell’ambiente.
Un esempio pratico con API REST dedicate
Nel caso di una API REST usata esclusivamente da un’app proprietaria, il comportamento desiderato può essere molto rigido:
- lo User-Agent deve essere esattamente quello previsto;
- qualunque altro User-Agent riceve 403;
- gli endpoint non devono fornire messaggi di errore dettagliati;
- il controllo deve avvenire prima possibile;
- i log devono registrare i rifiuti in modo utile ma non eccessivamente verboso.
Ad esempio, lato Nginx si potrebbe introdurre una regola che verifica lo User-Agent e blocca tutto ciò che non corrisponde a una stringa attesa. Lo stesso si può fare in Apache, in Varnish, in HAProxy, in un CDN, in un WAF o direttamente nel backend applicativo.
La scelta del livello dipende dall’architettura. Se l’obiettivo è risparmiare risorse, ha senso bloccare il traffico il più a monte possibile. Se si dispone di un reverse proxy davanti all’applicazione, quello è spesso il punto ideale. Se si usa una CDN o un sistema edge programmabile, ancora meglio: il traffico indesiderato può essere scartato prima ancora di raggiungere l’infrastruttura origin.
Perché funziona contro molta scansione automatica
Una grande quantità di traffico malevolo o indesiderato si basa su tool generici. Questi strumenti spesso inviano User-Agent riconoscibili oppure non si preoccupano affatto di camuffarsi. Alcuni usano stringhe standard come curl, Wget, Python-requests, Go-http-client, Java, libwww-perl, masscan, sqlmap, nikto, oppure User-Agent completamente vuoti o palesemente anomali.
Bloccare tutto tranne un set ristretto di User-Agent conosciuti può quindi eliminare una grossa porzione di richieste inutili. Non perché il sistema sia diventato invulnerabile, ma perché molti attori opportunistici non hanno alcun motivo di adattarsi specificamente a quel singolo servizio.
È lo stesso principio per cui alcune misure molto semplici, pur non essendo definitive, riducono drasticamente il rumore: disabilitare endpoint inutili, chiudere porte non usate, limitare metodi HTTP non necessari, impedire directory listing, bloccare accessi a file nascosti, applicare rate limiting, usare allowlist IP quando possibile.
Lo User-Agent filtering, in questo quadro, è una misura ulteriore.
I limiti: falsificabilità e manutenzione
Il limite principale è evidente: lo User-Agent può essere falsificato. Basta conoscere la stringa corretta e riprodurla nella richiesta. Per questo non bisogna mai basare la sicurezza reale di un’API solo su questo controllo.
Un altro limite è la manutenzione. Se l’app cambia User-Agent, se esistono più versioni del client, se ci sono ambienti di staging, beta, test interni, client legacy o integrazioni differenti, bisogna gestire correttamente la lista degli User-Agent ammessi.
Inoltre, alcune librerie, proxy o componenti intermedi potrebbero modificare o normalizzare gli header HTTP. È quindi necessario testare bene il comportamento reale dell’applicazione in produzione, non solo quello teorico.
C’è poi un aspetto operativo: un filtro troppo rigido può bloccare client legittimi in caso di bug, aggiornamenti o differenze tra piattaforme. Per questo è consigliabile introdurre queste regole in modo controllato, partendo dai log, osservando gli User-Agent effettivamente usati dai client reali e solo dopo applicando il blocco.
User-Agent segreto o identificativo pubblico?
Nel nostro esempio abbiamo usato una stringa come MyAPP-secret. Qui conviene fare una distinzione importante. Se quella stringa viene trattata come un vero segreto, allora bisogna ricordare che un’app distribuita agli utenti non è un luogo sicuro in cui custodire segreti statici. Un attaccante può analizzare il binario, osservare il traffico, usare un proxy locale, fare reverse engineering e recuperare la stringa.
Quindi, più che “segreto” in senso forte, lo User-Agent personalizzato va considerato un identificatore non pubblicizzato. Può essere poco noto, non documentato, non standard, utile per distinguere il client legittimo dal traffico generico. Ma non deve essere l’unica chiave d’accesso.
Se serve autenticazione forte, bisogna usare meccanismi appropriati: token firmati, API key rotabili, HMAC con timestamp, certificati client, sessioni sicure, firma delle richieste, controllo del dispositivo, attestation dove applicabile e altre soluzioni pensate realmente per provare l’identità del client.
Una misura utile soprattutto in contesti chiusi
Il controllo dello User-Agent ha senso soprattutto quando il numero di client legittimi è limitato e prevedibile. È il caso di:
- app mobile proprietarie;
- estensioni browser controllate;
- agent software installati su sistemi gestiti;
- integrazioni private tra servizi;
- API interne esposte pubblicamente per necessità architetturali;
- endpoint tecnici usati solo da un frontend specifico;
- servizi non destinati a essere esplorati da browser generici.
Ha invece meno senso su siti web pubblici tradizionali, dove gli utenti possono arrivare con browser, versioni, dispositivi, bot legittimi, sistemi di accessibilità, crawler dei motori di ricerca e strumenti diversi. In quel caso un filtro troppo restrittivo rischia di fare più danni che benefici.
La regola pratica è semplice: se l’insieme dei client legittimi è noto e ristretto, lo User-Agent può essere un buon segnale di preselezione. Se invece il servizio è pensato per essere usato da chiunque, lo User-Agent filtering va usato con molta cautela.
Benefici concreti: meno banda, meno CPU, meno rumore
Uno dei vantaggi più sottovalutati è la riduzione del rumore. In ambienti reali, il traffico indesiderato non è solo un problema di sicurezza, ma anche di qualità operativa.
Meno richieste inutili significano:
- meno consumo di banda;
- meno connessioni aperte;
- meno lavoro per il backend;
- meno pressione su PHP-FPM, Node.js, Java o altri runtime;
- meno log da processare;
- meno alert falsi;
- meno pattern sospetti da analizzare;
- più chiarezza nel distinguere il traffico legittimo da quello anomalo.
In alcuni casi, soprattutto su endpoint costosi o infrastrutture molto sollecitate, bloccare precocemente il traffico indesiderato può avere un effetto percepibile sulle performance e sulla stabilità.
Non bisogna immaginare questa misura come una protezione miracolosa, ma come un filtro economico. Una richiesta respinta con un 403 a livello di proxy costa molto meno di una richiesta che attraversa l’intero stack applicativo, inizializza framework, apre connessioni al database e produce log applicativi complessi.
Difesa a più livelli
La sicurezza efficace nasce dalla stratificazione. Lo User-Agent filtering può essere combinato con altre misure:
- HTTPS obbligatorio;
- autenticazione forte;
- token temporanei;
- firma delle richieste;
- rate limiting per IP, subnet o fingerprint;
- geofencing dove sensato;
- allowlist IP per ambienti controllati;
- WAF con regole specifiche;
- blocco dei metodi HTTP inutili;
- validazione rigorosa degli input;
- logging strutturato;
- monitoraggio delle anomalie;
- alert su pattern sospetti;
- separazione tra endpoint pubblici e privati.
In questo contesto, il controllo dello User-Agent diventa un piccolo cancello iniziale. Non decide da solo chi è autorizzato ad accedere ai dati, ma scarta rapidamente chi non assomiglia nemmeno a un client previsto.
Conclusione
Usare lo User-Agent come misura di sicurezza non significa credere che una stringa HTTP possa fermare un attaccante determinato. Sarebbe ingenuo. Significa invece riconoscere che non tutto il traffico ostile è sofisticato, non tutti gli attacchi sono mirati e non tutte le richieste meritano di raggiungere il cuore dell’applicazione.
In scenari selezionati, dove un server espone API destinate a client conosciuti, filtrare in base allo User-Agent può ridurre in modo concreto scansioni, enumerazioni, traffico opportunistico e rumore operativo. Può far risparmiare banda, CPU, risorse applicative e tempo di analisi. Può rendere meno accessibile la superficie applicativa ai bot generici e agli scanner che si limitano a bussare ovunque, sperando che prima o poi qualcuno lasci una porta aperta.
Non è la ricetta definitiva per la sicurezza. Non deve mai sostituire autenticazione, autorizzazione, cifratura, hardening, rate limiting e controllo applicativo. Ma può essere un tassello sensato in una strategia più ampia di riduzione dell’esposizione.
La sicurezza moderna non è fatta solo di grandi soluzioni complesse. È fatta anche di scelte pragmatiche, di piccoli filtri, di barriere successive e di buon senso architetturale. In questo senso, lo User-Agent, pur con tutti i suoi limiti, può ancora avere un ruolo utile: non come serratura principale, ma come primo cancello per tenere fuori chi non aveva alcun motivo legittimo di entrare.