
Indice dei contenuti dell'articolo:
Non è solo una sequenza di bug: è un cambio di paradigma
Il punto vero non è che esistano vulnerabilità. Le vulnerabilità sono sempre esistite. Esisteranno sempre. Il software complesso è imperfetto per definizione, soprattutto quando vive per anni, accumula funzionalità, compatibilità, moduli, layer, retrocompatibilità e casi limite.
La differenza, oggi, è la velocità.
Fino a pochi anni fa, trasformare una patch in un exploit richiedeva competenze molto specifiche. Serviva saper leggere C e C++ con attenzione, capire l’assembler, conoscere lo stack, l’heap, le tecniche di memory corruption, GDB, return-to-libc, ROP chain, ASLR bypass, shellcode, NOP sled, primitive di lettura e scrittura, condizioni di race, use-after-free, double-free, integer overflow, path traversal, deserializzazione, e tutta quella materia grigia che per decenni ha separato il semplice “lettore di advisory” dal vero exploit developer.
Oggi questo confine non è scomparso, ma si è assottigliato in modo pericoloso.
Gli LLM non rendono automaticamente chiunque un ricercatore di sicurezza di alto livello. Questo sarebbe un racconto superficiale e falso. Ma riducono enormemente il costo dell’analisi preliminare, della comprensione del diff, della classificazione del bug, della generazione di ipotesi e della costruzione di proof-of-concept. Secondo l’articolo di Tom’s Hardware da cui prendiamo spunto, i modelli linguistici possono ridurre drasticamente il tempo necessario per trasformare una patch in un exploit funzionante, mettendo in discussione anche la classica finestra di disclosure di 90 giorni. Tom’s Hardware Italia: Patch, exploit e AI.
Il punto è proprio questo: non serve più necessariamente analizzare un’intera codebase da milioni di righe. Il metodo più efficace e pragmatico è spesso molto più banale: si prende la versione precedente, si prende la versione successiva, si fa un diff, si osservano le modifiche, si isola il codice corretto, e da lì si prova a capire quale vulnerabilità sia stata chiusa.
In un mondo pre-AI questo processo richiedeva tempo, competenza e intuito. In un mondo post-AI, quel lavoro può essere accelerato, parallelizzato, automatizzato, raffinato e ripetuto su centinaia di progetti, release e patch.
Non serve immaginare modelli segreti, mitologici, tenuti nascosti nei laboratori delle grandi aziende o delle agenzie governative. Bastano modelli oggi comunemente disponibili, strumenti di coding assistito, agenti automatici, pipeline di analisi e budget adeguati. La differenza tra attaccante e difensore diventa così ancora più brutale: il difensore deve inventariare, valutare, testare, patchare, riavviare, comunicare, mitigare, verificare; l’attaccante deve trovare un varco prima che tutto questo processo sia completato.
La cronologia di un maggio ad alta tensione
Per capire il grado di concentrazione del problema, è utile mettere in fila gli eventi.
Il 28 aprile 2026 arriva la vulnerabilità cPanel/WHM CVE-2026-41940. Una falla nel layer di gestione delle sessioni, particolarmente grave perché riguarda un pannello di controllo utilizzatissimo nel mondo hosting. cPanel ha dichiarato di aver rilasciato aggiornamenti il 28 aprile e di aver reso disponibili correzioni in circa 28 ore dopo la conferma della segnalazione, coprendo versioni supportate e alcune versioni legacy selezionate. cPanel Security Update: CVE-2026-41940.

Il 29 aprile entra in scena Copy Fail, CVE-2026-31431, una vulnerabilità nel kernel Linux che consente privilege escalation locale. Il problema risiede nel sottosistema crittografico algif_aead e coinvolge l’interazione con splice(), page cache e binari privilegiati. Il dato più preoccupante non è soltanto l’impatto tecnico, ma la portabilità dell’exploit: Tom’s Hardware ha riportato che il codice di exploit era pubblico e funzionante su più distribuzioni principali, abbassando la barriera d’ingresso per eventuali attaccanti. https://xint.io/blog/copy-fail-linux-distributions

Il 5 maggio viene pubblicata la correzione Apache HTTP Server 2.4.67, che include CVE-2026-23918: double-free e possibile RCE nella gestione HTTP/2. Apache indica esplicitamente che il problema riguarda Apache HTTP Server 2.4.66 e raccomanda l’upgrade alla 2.4.67. Apache HTTP Server 2.4 vulnerabilities.

Il 7 maggio viene divulgata Dirty Frag, con CVE-2026-43284 e CVE-2026-43500, due vulnerabilità LPE nel kernel Linux. Ubuntu descrive CVE-2026-43284 come un problema legato alla gestione di frammenti condivisi negli skb e alla decrittazione in-place in ambito ESP/IPsec, con impatto di privilege escalation locale. Ubuntu Security: CVE-2026-43284.
Il 12 maggio si aggiunge il caso NGINX URL Rewrite Validation Bypass, una vulnerabilità logica che impatta scenari di rewrite, normalizzazione e disallineamento tra controllo di accesso e risorsa effettivamente raggiunta. Per chi amministra reverse proxy, application gateway e stack con backend multipli, è una classe di problema da non sottovalutare: spesso non basta aggiornare un pacchetto, bisogna anche rivedere assunzioni architetturali, regole di location, proxy pass, rewrite e validazione. Ne parla dettagliatamente https://www.redhotcyber.com/post/un-bug-critico-per-18-anni-e-rimasto-nascosto-nelle-codice-di-nginx/
Questa non è una sequenza casuale di piccoli incidenti. È una raffica. Ed è una raffica su componenti essenziali in uso da almeno il 90% delle macchine esposte in rete con servizio di Web Server. Almeno il 90% !
Apache, Linux, NGINX, cPanel: perché questi nomi pesano
Quando una vulnerabilità colpisce un software di nicchia, il problema può essere circoscritto. Quando colpisce Apache HTTP Server, NGINX, il kernel Linux o cPanel/WHM, la scala cambia completamente.
Apache è ancora oggi un pilastro del web. Anche quando non è esposto direttamente come frontend, può essere presente dietro reverse proxy, in ambienti legacy, in applicazioni enterprise, in hosting condivisi, in CMS e stack LAMP. Una possibile RCE in HTTP/2 non è un dettaglio. HTTP/2 è ampiamente usato, e la gestione dei frame, degli stream e dei reset anticipati è un’area complessa in cui un errore di memoria può avere conseguenze importanti.
Il kernel Linux è il terreno comune. È sotto i container, sotto i server fisici, sotto le VPS, sotto le istanze cloud, sotto gli hypervisor in molti scenari, sotto appliance e distribuzioni. Una privilege escalation locale non è “meno grave” solo perché richiede accesso locale. Nel mondo reale, l’accesso locale può arrivare da un account compromesso, da una web shell, da un container bucato, da un utente hosting, da un job CI/CD, da un plugin vulnerabile, da un CMS compromesso. Una volta dentro, ottenere root significa cambiare completamente il perimetro dell’incidente.
NGINX è il Web Server e reverse proxy per eccellenza in moltissime infrastrutture moderne. Il Golden Standard, spesso la prima linea di difesa davanti ad applicazioni PHP, Node.js, Python, Java, microservizi, API e pannelli amministrativi. Un bypass di access control o una path traversal logica su rewrite e normalizzazione può trasformare una configurazione apparentemente sicura in un percorso alternativo verso risorse interne.
cPanel/WHM, infine, è uno dei pannelli più diffusi nel settore hosting. Una vulnerabilità di authentication bypass in questo contesto è particolarmente delicata perché non riguarda un singolo sito, ma potenzialmente l’amministrazione di interi server, account, DNS, posta, database e servizi collegati.
La combinazione di questi quattro mondi racconta una cosa molto semplice: il mese di maggio 2026 ha toccato quasi tutto ciò che un sistemista Linux e hosting deve presidiare ed una combo di eventi di tale portata non si era mai vista dal 1994 ad oggi.
Il sistemista tra incudine e martello
Nel racconto semplificato della sicurezza informatica ci sono gli hacker da una parte e gli sviluppatori dall’altra. Gli hacker cercano i bug, gli sviluppatori li correggono. Ma in mezzo, spesso dimenticato, c’è il sistemista.
Il sistemista è quello che riceve la patch quando la vulnerabilità è già pubblica. È quello che deve capire se il parco macchine è impattato. È quello che deve distinguere tra sistemi vulnerabili, sistemi non vulnerabili, sistemi mitigabili, sistemi da riavviare subito, sistemi da riavviare con finestra concordata, sistemi legacy, sistemi con dipendenze applicative, server con uptime critico, ambienti di produzione, ambienti staging e ambienti dimenticati da anni che però “non si possono spegnere”.
Il sistemista è quello che deve spiegare al cliente perché il riavvio è necessario. È quello che deve scegliere tra il rischio di downtime e il rischio di compromissione. È quello che deve leggere advisory, changelog, CVE, mailing list, issue tracker, pacchetti della distribuzione, backport, patch vendor-specifiche, note di compatibilità, falsi positivi degli scanner e report incompleti.
E oggi lo deve fare mentre dall’altra parte gli attaccanti, o anche semplicemente i ricercatori più aggressivi, possono usare l’AI per comprimere enormemente i tempi di analisi.
Questa è la parte che spesso non viene compresa da chi guarda la sicurezza da fuori. Il problema non è “aggiornare”. Il problema è aggiornare bene, in fretta, senza rompere la produzione, senza perdere dati, senza causare regressioni, senza lasciare fuori sistemi secondari, senza generare panico e senza trasformare un patch day in un disastro operativo.
Perché abbiamo declinato preventivi e onboarding
In questi giorni, in Managed Server S.r.l., abbiamo fatto una scelta che non è stata piacevole, ma che riteniamo corretta: abbiamo diligentemente declinato l’invio di preventivi urgenti e l’onboarding di nuovi clienti, dando massima priorità alla risoluzione dei problemi, al patching, alle verifiche e allo sviluppo di strumenti interni per velocizzare le attività future.
Alcuni potenziali clienti hanno preso molto, molto, MOLTO MALE questa scelta. Lo comprendiamo. Lo comprendiamo e ci scusiamo. Chi chiede un preventivo urgente, spesso, ha a sua volta una necessità urgente. Può avere un progetto fermo, un sito lento, un’infrastruttura instabile, un e-commerce da migrare, una scadenza commerciale o un problema tecnico da risolvere.
Altre volte è solo un capriccio, e voler semplicemente avere un preventivo entro 24 – 48 perchè in fondo è il cliente e il cliente come si sa “ha sempre ragione”. Nel settore sistemistica tuttavia non siamo un negozio di elettrodomestici, o un salumiere che vende tanto al chilo quello che ha esposto, ma siamo più un pronto soccorso, con un triage, dove il cliente con problemi gravi ha la priorità assoluta su chi ha solo un capriccio e vuole passare avanti ai casi gravi solo perchè “Cliente pagante”. Purtroppo ci sono dietro le quinte, retroscena, che spiegheremo in questo post che vuol essere non tanto una giustificazione ma un resoconto di quello che è successo, e che probabilmente succederà di nuovo.
Da parte nostra dispiace certamente. Dispiace per il nuovo potenziale cliente, perché non ricevere una risposta commerciale nei tempi desiderati può essere frustrante. Dispiace anche per il mancato guadagno, perché ogni preventivo non gestito può significare un’opportunità persa.
Ma la sicurezza e la continuità operativa dei clienti già acquisiti vengono prima.
Un’azienda di hosting e sistemistica non vende semplicemente spazio disco, CPU, RAM o traffico. Vende presidio tecnico, responsabilità, attenzione, competenza e capacità di intervento. Quando il contesto globale presenta vulnerabilità gravi su componenti fondamentali, la priorità non può essere aprire nuove trattative commerciali mentre i clienti esistenti attendono patch, analisi, mitigazioni e verifiche.
Siamo convinti di aver operato diligentemente, a tutela del nostro business e soprattutto del business dei nostri clienti attuali. Un cliente nuovo può attendere un preventivo. Un server vulnerabile esposto in produzione, no.
Tool interni, automazione e patching veloce
Uno degli effetti collaterali di questa ondata è stato l’accelerazione dello sviluppo di tool interni per il patching veloce, l’inventario e la verifica.
Questo è un punto fondamentale. In un mondo in cui gli exploit possono emergere poche ore dopo una patch, la risposta non può essere affidata soltanto alla memoria del singolo sistemista o a procedure manuali ripetute server per server.
Servono strumenti che permettano di sapere rapidamente dove è installata una determinata versione di Apache, dove HTTP/2 è abilitato, quali server usano NGINX con regole di rewrite complesse, quali kernel sono in esecuzione, quali macchine richiedono reboot effettivo dopo aggiornamento, quali versioni di cPanel sono ancora vulnerabili, quali nodi sono coperti da patch vendor e quali richiedono mitigazioni temporanee.
Serve una mappa. Serve automazione. Serve capacità di eseguire controlli massivi senza perdere qualità. Serve anche la capacità di produrre report, perché la sicurezza non è soltanto “abbiamo aggiornato”, ma “abbiamo aggiornato, verificato, documentato e sappiamo cosa resta da fare”.
Ad esempio abbiamo esteso il nostro Tool di gestione Firewall, monitoring ed inventario con un sistema di esecuzione SSH multipla per poter fare nell’immediato il fingerprinting dei sistemi e procedere all’applicazione della patch in massa.
Il concetto di base è stato quello di fare uno sforzo iniziale maggiore per avere ciò che volevamo su misura per poi risparmiare tempo tutte le volte successive che si potessero verificare situazioni simili in cui il patching deve avvenire non in giorni ma in un paio d’ore sull’intero parco macchine che siano centinaia, migliaia o decine di migliaia di sistemi e nodi.
L’AI insomma può essere usata dagli attaccanti, ma deve essere usata anche dai difensori. Non per sostituire il giudizio tecnico, ma per accelerare analisi, correlazione, lettura dei changelog, sintesi delle advisory, generazione di checklist, controllo delle configurazioni e supporto alle attività ripetitive. Il punto è non delegare ciecamente, ma usare l’automazione come esoscheletro operativo.
Il problema dei cicli di rilascio open source
Arriviamo così al tema più scomodo: il modello tradizionale di rilascio open source è ancora adeguato in un mondo in cui l’AI può trasformare rapidamente una patch in un exploit?
La domanda è provocatoria, ma non può più essere ignorata.
L’open source si basa sulla trasparenza. Il codice è pubblico, le patch sono pubbliche, i diff sono pubblici. Questo ha enormi vantaggi: auditabilità, fiducia, collaborazione, verifica indipendente, possibilità di backport, controllo comunitario, assenza di black box. Ma nel momento in cui una patch di sicurezza viene pubblicata, anche l’attaccante vede esattamente cosa è cambiato.
Prima questa trasparenza richiedeva comunque competenza elevata per essere trasformata in arma. Oggi l’AI abbassa la soglia. Un diff ristretto è un contesto perfetto per un LLM: poche righe cambiate, funzioni correlate, commit message, test aggiunti, fix introdotto. È molto più facile analizzare un delta di cento righe che una codebase da milioni di righe.
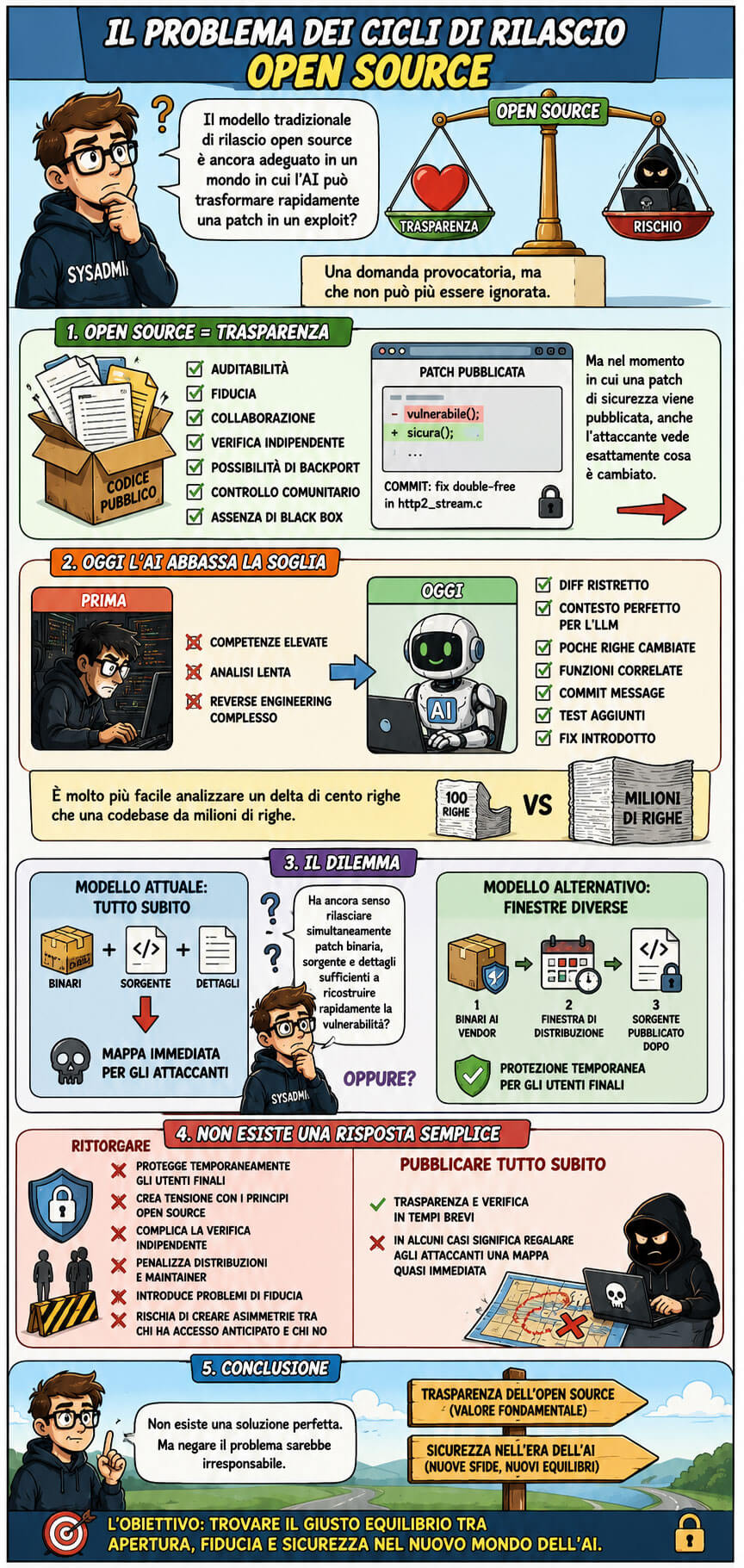
Da qui nasce il dilemma: ha ancora senso rilasciare simultaneamente patch binaria, sorgente e dettagli sufficienti a ricostruire rapidamente la vulnerabilità? Oppure, per alcune classi di bug critici, servirebbero finestre diverse, distribuzione coordinata ai vendor, rilascio prima dei binari e pubblicazione differita del sorgente?
La risposta non è semplice.
Ritardare il sorgente può proteggere temporaneamente gli utenti finali, ma crea tensione con i principi open source, complica la verifica indipendente, penalizza distribuzioni e maintainer, introduce problemi di fiducia e rischia di creare asimmetrie tra chi ha accesso anticipato e chi non lo ha.
Pubblicare tutto subito, però, in alcuni casi significa regalare agli attaccanti una mappa quasi immediata.
Non esiste una soluzione perfetta. Ma negare il problema sarebbe irresponsabile.
La disclosure dei 90 giorni è ancora sensata?
Per anni la finestra di disclosure di 90 giorni è stata considerata un compromesso ragionevole: abbastanza lunga da permettere ai vendor di correggere, abbastanza corta da evitare che le vulnerabilità restassero segrete indefinitamente.
Ma se l’AI consente di trasformare patch e advisory in exploit funzionanti in tempi molto ridotti, il problema si sposta. Non basta più chiedersi “quanto tempo ha avuto il vendor per correggere?”. Bisogna chiedersi “quanto tempo ha il difensore per distribuire la correzione prima che l’exploit diventi operativo su larga scala?”.
Questa seconda finestra è molto più stretta.
In ambienti reali, soprattutto hosting e infrastrutture gestite, applicare patch non significa premere un pulsante. Bisogna considerare compatibilità, carico, finestre di manutenzione, reboot, cluster, HA, rollback, backup, test applicativi, comunicazione ai clienti e monitoraggio post-intervento.
Se la finestra tra patch pubblica ed exploit funzionante si riduce a poche ore, il modello operativo deve cambiare. Non è più sufficiente essere “abbastanza veloci”. Bisogna essere preparati prima.
La sicurezza non è più un reparto: è una postura permanente
La lezione di questo maggio è chiara: la sicurezza non può essere trattata come un evento. Non può essere il ticket aperto quando esce la CVE. Non può essere il panico del venerdì sera o del giorno festivo. Deve essere una postura permanente.
Questo significa inventario aggiornato, procedure di patching testate, automazione, monitoring, backup verificati, capacità di rollback, segmentazione, riduzione della superficie d’attacco, hardening, principio del minimo privilegio, controllo degli accessi, logging centralizzato, EDR dove opportuno, kernel live patching quando sostenibile, ambienti staging realistici, documentazione interna e personale formato.
Significa anche avere il coraggio di dire no. No a nuovi onboarding quando il team deve presidiare una crisi. No a preventivi urgenti se la priorità tecnica è proteggere chi ha già affidato a noi la propria infrastruttura. No alla crescita commerciale quando rischia di compromettere la qualità operativa.
In un settore maturo, questa non dovrebbe essere vista come una mancanza di attenzione commerciale, ma come un segnale di serietà.
Ovviamente questo impegno aggiuntivo, rischi maggiori anche a fronte delle nuove direttive NIS2 si tradurranno necessariamente in molto lavoro in più e inevitabilmente a costi di gestione maggiori di almeno il 10 – 15% sugli attuali costi che già subiscono rincari per via della corsa all’hardware sempre dettata dalla rivoluzione AI.
AI contro sviluppatori, hacker contro difensori: il nuovo equilibrio
L’immagine simbolica di questo momento è un braccio di ferro: da una parte gli attaccanti, dall’altra gli sviluppatori e i maintainer, in mezzo l’intelligenza artificiale come arbitro ambiguo, acceleratore neutrale che non distingue tra chi difende e chi attacca.
Ma forse l’immagine è ancora incompleta. Perché accanto al tavolo, sotto pressione, c’è il sistemista. È lui che deve trasformare il risultato di quel braccio di ferro in azione concreta sui server. È lui che deve assorbire l’urto finale.

L’AI non è “buona” o “cattiva”. È uno strumento. Ma come ogni strumento potente, cambia gli equilibri. E in sicurezza informatica gli equilibri contano più delle intenzioni.
Se un attaccante può analizzare cento patch al giorno e un difensore può patchare correttamente dieci sistemi critici al giorno, il problema non è morale: è matematico.
Il vantaggio va a chi automatizza meglio, inventaria meglio, decide più velocemente, riduce la complessità e non si fa trovare impreparato.
Conclusione: maggio 2026 come campanello d’allarme
Il maggio 2026 rischia di essere ricordato come un campanello d’allarme. Apache, NGINX, kernel Linux, cPanel/WHM: nomi enormi, software diffusissimi, vulnerabilità ravvicinate, impatti importanti, patch urgenti, exploit e analisi sempre più veloci.
Non è la fine dell’Open Source. Non è la prova che Linux sia insicuro. Non è il momento di fare allarmismo sterile.
È però il momento di ammettere che il modello operativo della sicurezza sta cambiando. L’intelligenza artificiale ha ridotto il tempo tra patch e comprensione della vulnerabilità. Ha abbassato la barriera tecnica per l’analisi dei diff. Ha reso più facile automatizzare il lavoro sporco che prima richiedeva ore o giorni di reverse engineering manuale.
Di conseguenza, chi gestisce infrastrutture non può più permettersi lentezza, improvvisazione o processi artigianali.
In Managed Server S.r.l. abbiamo passato il primo maggio lavorando e, diciassette giorni dopo, continuiamo a lavorare su ciò che questo mese ci ha imposto: patch, verifiche, mitigazioni, automazioni, strumenti interni, procedure più rapide e maggiore capacità di risposta.
Avremmo preferito una scampagnata, una merenda, una gita fuori porta. Avremmo preferito anche inviare più preventivi, acquisire nuovi clienti, seguire nuove opportunità commerciali.
Ma quando la sicurezza chiama, il dovere viene prima del fatturato.
E questo, in fondo, è forse il modo più serio di onorare davvero la Festa dei Lavoratori: lavorare quando serve, proteggere chi si è affidato a noi, e prepararsi al prossimo attacco prima che arrivi.
E siamo solo a metà mese … giorno più, giorno meno.
AGGIORNAMENTO al 21 /05/2026, ovvero appena 4 giorni dopo.
Come già anticipato nel pezzo sopra scritto di domenica, c’era da aspettarsi nuove sorprese, ed infatti non sono tardate ad arrivare.
Per la serie Local Exploit, lunedì 18 maggio, giusto per cominciare bene la giornata e la settimana, ci siamo trovati davanti a un nuovo bug battezzato DirtyDecrypt. Si tratta di una vulnerabilità di Local Privilege Escalation nel kernel Linux, identificata come CVE-2026-31635, che può permettere a un utente locale non privilegiato di ottenere permessi di root su sistemi vulnerabili. Il problema riguarda la gestione della decrittazione di buffer di rete nel kernel e si inserisce nella famiglia di vulnerabilità affini a DirtyFrag / CopyFail, con PoC pubblici già disponibili e quindi con un livello di attenzione decisamente alto per chi amministra server Linux in produzione.
Invece oggi, 21 maggio 2026, la giornata ha pensato bene di deliziarci con qualcosa di ancora più serio: una presunta nuova vulnerabilità RCE su NGINX, battezzata NGINX Poolslip. Parliamo di un possibile Remote Code Execution, quindi non più di un semplice local exploit o di una vulnerabilità sfruttabile solo da un utente già presente sulla macchina, ma di una classe di bug potenzialmente molto più pericolosa, perché teoricamente attivabile da remoto contro un servizio esposto su Internet. NGINX, insieme ad Apache, è uno dei web server più diffusi al mondo ed è spesso scelto proprio per le sue prestazioni, la sua efficienza nella gestione delle connessioni concorrenti e il suo utilizzo massiccio come reverse proxy, load balancer e frontend HTTP per applicazioni PHP, Node.js, Python, container e ambienti Kubernetes. Il problema, secondo le prime segnalazioni pubbliche, riguarderebbe anche NGINX 1.31.0, cioè la release mainline più recente pubblicata con le correzioni per la precedente ondata di vulnerabilità NGINX Rift / CVE-2026-42945.
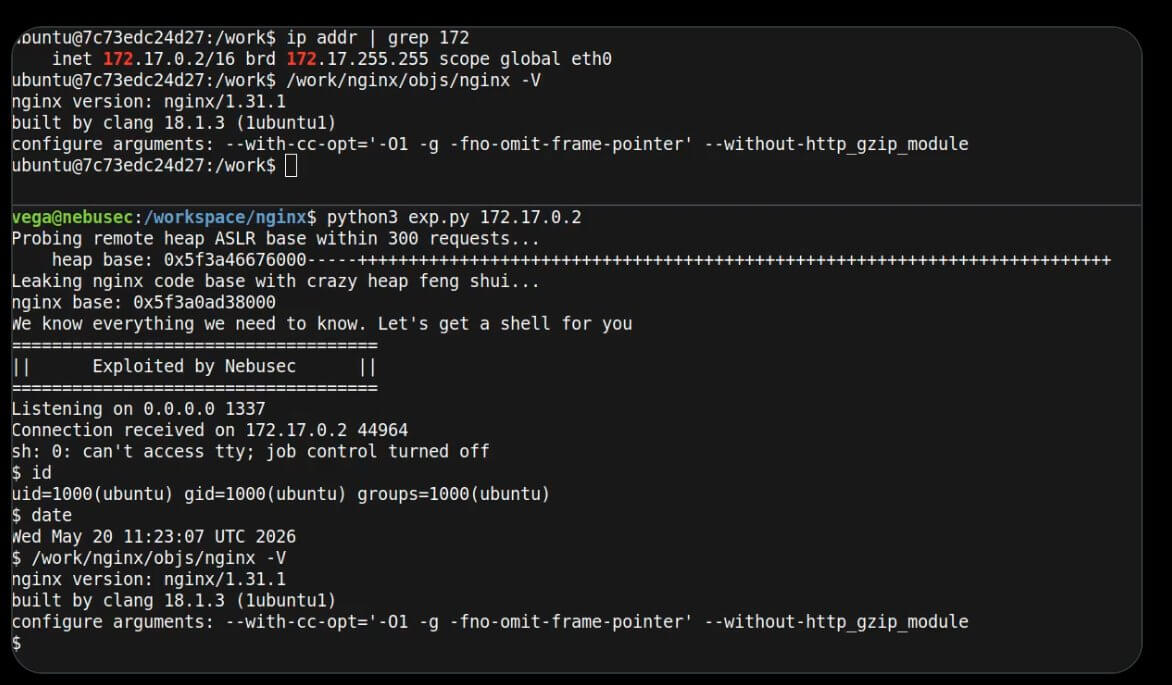
ngx_http_rewrite_module, classificato come potenzialmente sfruttabile per DoS o, in determinate condizioni, per code execution. Ora, a distanza di pochissimo, arriva la notizia di Poolslip, che secondo le prime ricostruzioni colpirebbe proprio la versione 1.31.0, andando quindi a riaprire il fronte su sistemi che molti amministratori consideravano già aggiornati e messi in sicurezza. Alle 23:04 italiane del 21 maggio 2026, dalle fonti disponibili non risulta ancora una patch ufficiale pubblicata nella pagina degli advisory NGINX per “nginx-poolslip”; per questo motivo la situazione va trattata con la massima prudenza, monitorando costantemente gli advisory ufficiali F5/NGINX e valutando nel frattempo misure conservative di hardening, riduzione della superficie esposta e controllo dei log sui frontend pubblici.
ptrace, legata alla gestione della cosiddetta dumpability dei processi Linux. Il problema, presente nel kernel da anni, può consentire a un utente locale non privilegiato di sfruttare una finestra di race condition durante la terminazione di processi privilegiati, arrivando a leggere informazioni sensibili normalmente riservate a root, come chiavi private SSH host o contenuti collegati a /etc/shadow.Pur non trattandosi di una vulnerabilità remota sfruttabile direttamente via rete, l’impatto è comunque rilevante in scenari multiutente, hosting condiviso, ambienti containerizzati o server in cui un attaccante disponga già di un accesso locale anche minimale. La vulnerabilità è stata associata pubblicamente al nome ssh-keysign-pwn e riguarda in particolare il comportamento di binari SUID come ssh-keysign e chage, che durante la loro normale esecuzione possono aprire file sensibili con privilegi elevati. Le principali distribuzioni Linux hanno iniziato a rilasciare aggiornamenti correttivi del kernel; AlmaLinux segnala ad esempio l’impatto su AlmaLinux 9 e 10, con patch previste anche per AlmaLinux 8 nonostante i PoC pubblici non risultino immediatamente efficaci su quella linea.