
Indice dei contenuti dell'articolo:
Quando si parla di sicurezza web, identificazione del traffico e mitigazione dei bot, si tende spesso a concentrare l’attenzione su elementi molto visibili: indirizzo IP, User-Agent, header HTTP, cookie, reputazione dell’ASN, geolocalizzazione, frequenza delle richieste o comportamento dell’utente all’interno del sito. Tutti questi segnali sono importanti, ma hanno un limite evidente: molti possono essere falsificati con estrema facilità. Un bot può dichiararsi Chrome, può copiare gli header di Firefox, può usare proxy residenziali e può simulare parte del comportamento di un browser reale. Tuttavia, sotto il livello HTTP esiste un altro strato molto più interessante da osservare: la negoziazione TLS.
Il TLS Fingerprinting nasce proprio da questa osservazione. Prima che il client invii una richiesta HTTP cifrata, deve stabilire una sessione sicura con il server attraverso il protocollo TLS. Durante questa fase iniziale, il client comunica una serie di caratteristiche tecniche: versioni supportate, cipher suite, estensioni TLS, curve ellittiche, algoritmi di firma, ordine dei parametri e altre informazioni utili alla negoziazione crittografica. Questi dettagli, presi nel loro insieme, formano una sorta di impronta digitale del client.
Questa impronta non identifica necessariamente una persona, ma può identificare una classe di software: un browser specifico, una versione di una libreria TLS, un client HTTP da riga di comando, uno scraper, un malware, un proxy, un bot o un’applicazione mobile. In molti casi, il TLS Fingerprinting permette di capire che un client che dichiara di essere Chrome tramite User-Agent non si comporta affatto come Chrome durante l’handshake TLS. Ed è proprio questa discrepanza a rendere la tecnica così preziosa.
Perché il TLS rivela informazioni sul client
TLS, Transport Layer Security, è il protocollo che permette di cifrare le comunicazioni tra client e server. Quando un browser visita un sito HTTPS, prima di inviare la richiesta vera e propria deve negoziare una connessione sicura. Questa negoziazione inizia tipicamente con un messaggio chiamato ClientHello. Il ClientHello contiene molte informazioni sulle capacità crittografiche del client.
Tra queste informazioni troviamo, ad esempio, le versioni TLS supportate, l’elenco delle cipher suite proposte, le estensioni abilitate, i gruppi supportati per lo scambio di chiavi, i formati dei punti ellittici, gli algoritmi di firma e altre opzioni. Questi elementi non sono scelti casualmente. Dipendono dal browser, dal sistema operativo, dalla libreria TLS utilizzata, dalla versione del software e talvolta anche dalla configurazione di rete.
Un Chrome moderno su Windows, un Firefox su Linux, Safari su macOS, curl compilato con OpenSSL, un’applicazione Go che usa la libreria standard, un client Python basato su requests, un bot scritto in Node.js e uno scraper headless non producono necessariamente lo stesso ClientHello. Anche quando inviano la stessa richiesta HTTP, possono presentare un’impronta TLS differente.
Questo è il punto centrale: mentre gli header HTTP sono facili da copiare, replicare perfettamente il comportamento TLS di un browser reale è più complesso. Non basta scrivere User-Agent: Mozilla/5.0. Bisogna emulare l’intero stack di negoziazione TLS, rispettando ordine, parametri, estensioni e comportamento del client originale.
Che cos’è concretamente un fingerprint TLS
Un fingerprint TLS è una rappresentazione sintetica delle caratteristiche osservate durante l’handshake. Invece di analizzare ogni volta tutti i dettagli grezzi del ClientHello, questi vengono normalizzati e trasformati in una stringa o in un hash confrontabile. In questo modo è possibile dire: questo client ha la stessa impronta di un determinato browser, oppure appartiene a una famiglia di client già nota.
Uno degli approcci più conosciuti è JA3, una tecnica che calcola un fingerprint a partire da alcuni campi del ClientHello: versione TLS, cipher suite, estensioni, curve ellittiche e formati dei punti ellittici. Questi valori vengono concatenati in una stringa e poi solitamente convertiti in hash MD5 per ottenere un identificatore compatto.
Un esempio concettuale, semplificato, può essere rappresentato così:
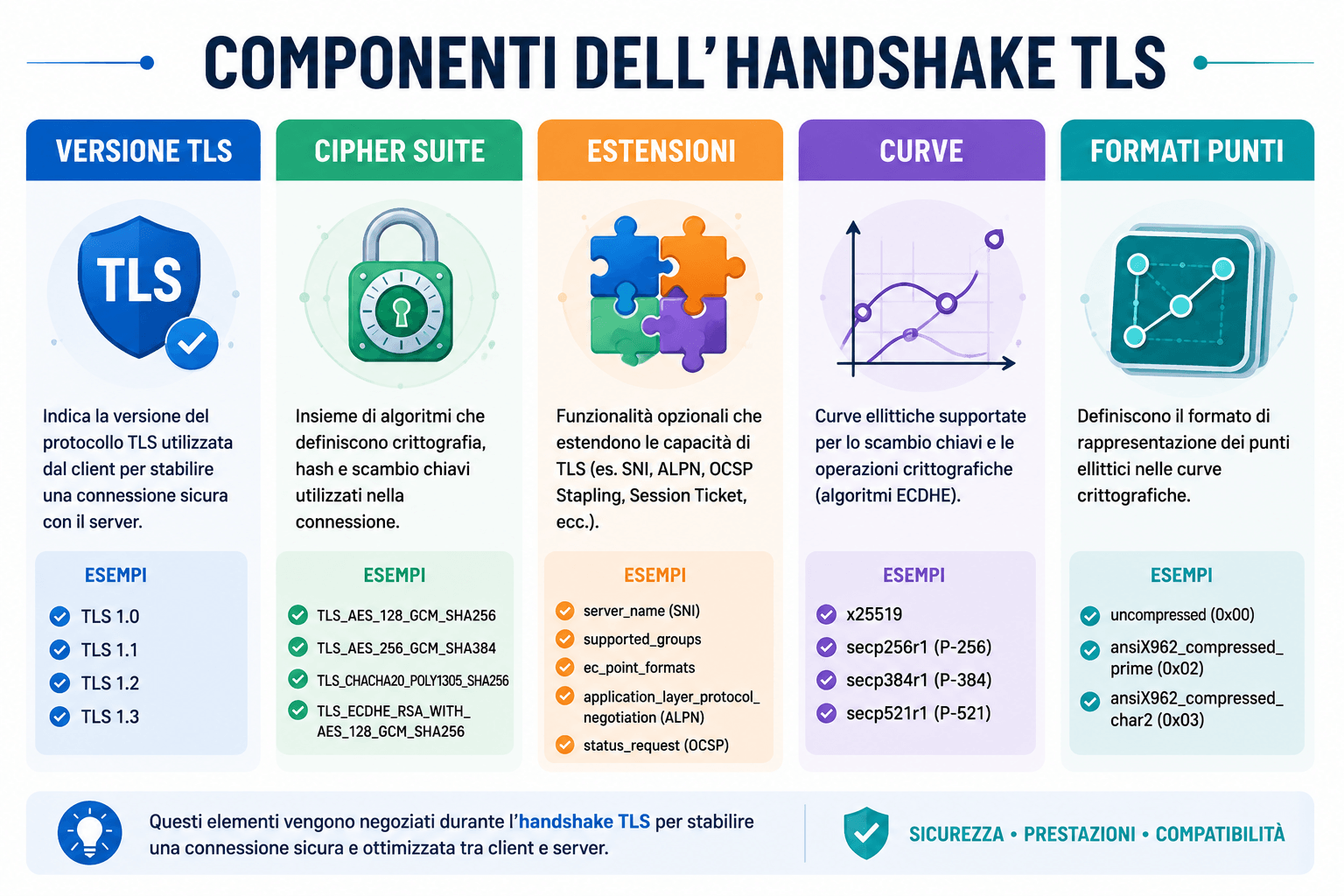
La stringa risultante viene poi trasformata in un’impronta. Client con la stessa configurazione TLS tenderanno a produrre lo stesso fingerprint. Questo consente di raggruppare il traffico per famiglie di client, individuare anomalie e confrontare ciò che il client dichiara a livello HTTP con ciò che mostra a livello TLS.
Esiste anche il fingerprinting lato server, spesso associato a JA3S, che analizza il messaggio ServerHello. Mentre JA3 descrive il comportamento del client, JA3S descrive quello del server. La combinazione dei due può essere utile in ambito threat intelligence, malware analysis e analisi del traffico cifrato, perché alcuni malware comunicano con infrastrutture TLS molto specifiche e riconoscibili.
TLS Fingerprinting e identificazione dei bot
Uno degli utilizzi più diffusi del TLS Fingerprinting è la distinzione tra browser reali e client automatizzati. Molti bot cercano di apparire come browser legittimi modificando lo User-Agent e copiando gli header più comuni. Tuttavia, se il loro stack TLS è quello di una libreria generica, l’incoerenza diventa evidente.
Immaginiamo una richiesta HTTP che dichiara di arrivare da una versione recente di Chrome. A livello applicativo può presentare header apparentemente corretti: User-Agent, Accept, Accept-Language, Accept-Encoding e così via. Ma se il ClientHello TLS assomiglia a quello prodotto da una vecchia versione di OpenSSL, da una libreria Go standard o da un client Python, il sistema di analisi può rilevare una discrepanza.
Questa tecnica è particolarmente utile perché molti bot meno sofisticati si limitano a falsificare il livello HTTP. Gli scraper più evoluti possono usare browser headless reali, librerie specializzate o stack TLS più curati, ma il TLS Fingerprinting resta comunque un segnale prezioso da combinare con altri indicatori.
È importante sottolineare che il TLS Fingerprinting non dovrebbe essere usato come unico criterio decisionale. Un fingerprint insolito non significa automaticamente traffico malevolo. Può trattarsi di un’applicazione legittima, di un client mobile, di un sistema embedded, di un monitoraggio esterno, di un proxy aziendale o di un software con una libreria TLS particolare. Il valore del fingerprint sta soprattutto nella correlazione con altri segnali.
Perché è più difficile da falsificare rispetto agli header HTTP
Gli header HTTP sono semplici stringhe inviate dal client. Modificarli è banale: quasi ogni libreria HTTP consente di impostare manualmente User-Agent, Accept-Language o altri campi. Per questo motivo, basare l’identificazione solo sugli header è sempre più debole.
Il fingerprint TLS, invece, deriva dal comportamento della libreria TLS sottostante. Modificarlo richiede un controllo più profondo dello stack di rete. Bisogna cambiare l’elenco e l’ordine delle cipher suite, le estensioni, i gruppi supportati, gli algoritmi di firma e altri parametri. In alcuni linguaggi o librerie questo è possibile solo parzialmente; in altri richiede patch, librerie alternative o strumenti specifici.
Inoltre, il fingerprint non riguarda solo la presenza di certi parametri, ma anche il loro ordine. Browser diversi possono proporre suite crittografiche simili ma in ordine differente. Possono usare estensioni simili ma non identiche. Possono comportarsi diversamente con TLS 1.2, TLS 1.3, ALPN, SNI, session resumption o GREASE. Questi dettagli rendono l’impronta più difficile da imitare con precisione.
Il ruolo di ALPN, HTTP/2 e HTTP/3
Nel mondo web moderno, la negoziazione TLS non serve solo a stabilire la cifratura. Attraverso l’estensione ALPN, Application-Layer Protocol Negotiation, il client e il server concordano anche quale protocollo applicativo usare sopra TLS, ad esempio HTTP/1.1 o HTTP/2. Anche questa informazione può contribuire al fingerprint.
Un browser moderno tende a proporre HTTP/2 quando disponibile. Alcuni client automatizzati, invece, usano ancora solo HTTP/1.1 oppure presentano combinazioni insolite. L’ordine dei protocolli ALPN, la presenza o assenza di HTTP/2 e il comportamento successivo della connessione possono fornire ulteriori segnali.
Con HTTP/3 e QUIC lo scenario diventa ancora più interessante, perché QUIC integra TLS 1.3 in un contesto diverso, basato su UDP. Anche qui esistono impronte osservabili, ma la logica non è identica al TLS tradizionale su TCP. Le tecniche di fingerprinting si stanno evolvendo per tenere conto di questi cambiamenti, perché il traffico moderno non passa più soltanto attraverso il classico handshake TLS su porta 443 TCP.
JA3, JA4 e l’evoluzione del fingerprinting
JA3 ha avuto un ruolo importante nel rendere popolare il TLS Fingerprinting, soprattutto in ambito sicurezza e threat intelligence. La sua semplicità lo ha reso facile da implementare e da integrare in sistemi di monitoraggio, IDS, SIEM e piattaforme di analisi del traffico. Tuttavia, come ogni tecnica, ha dei limiti.
Uno dei problemi è che piccole variazioni possono produrre fingerprint diversi, mentre client differenti possono occasionalmente convergere su impronte simili. Inoltre, l’introduzione di meccanismi come GREASE, usati dai browser moderni per rendere più robusto l’ecosistema TLS contro implementazioni rigide, può complicare la normalizzazione.
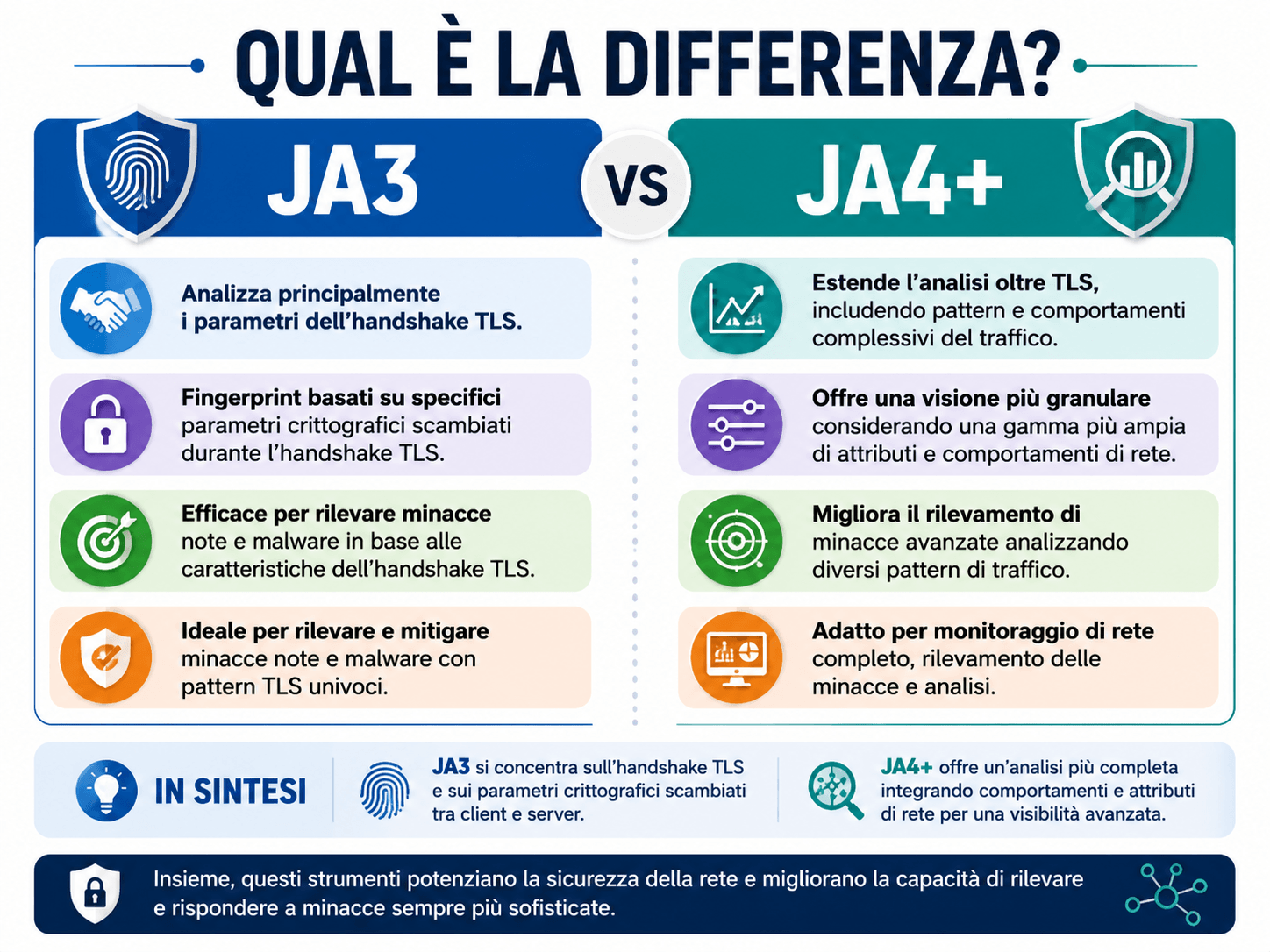
Per superare alcuni di questi limiti sono nati approcci più recenti, tra cui JA4 e varianti collegate. L’obiettivo è produrre fingerprint più stabili, interpretabili e resistenti ad alcune forme di rumore. In generale, l’evoluzione del fingerprinting va nella direzione di segnali più ricchi, meno fragili e più adatti a distinguere famiglie di client senza affidarsi a un singolo hash opaco.
Per un amministratore di sistemi o un’azienda che gestisce infrastrutture web, il punto non è necessariamente implementare manualmente JA3 o JA4, ma capire il principio: il modo in cui un client negozia TLS contiene informazioni preziose e spesso più affidabili di quelle dichiarate a livello HTTP.
Uso difensivo del TLS Fingerprinting
Dal punto di vista difensivo, il TLS Fingerprinting può essere usato in diversi modi. Il primo è la classificazione del traffico. Sapere quali fingerprint accedono normalmente a un sito permette di costruire una baseline. Se un sito riceve principalmente traffico da browser comuni, la comparsa improvvisa di fingerprint associati a librerie automatizzate può indicare scraping, scansioni, credential stuffing o attività anomala.
Un secondo uso è la correlazione con eventi di sicurezza. Se un certo fingerprint appare frequentemente in tentativi di login falliti, scansioni di endpoint, richieste a URL inesistenti o pattern aggressivi, può diventare un indicatore utile per mitigazioni successive. Non necessariamente per bloccare in modo cieco, ma per aumentare il punteggio di rischio associato alla richiesta.
Un terzo uso riguarda il rilevamento di incoerenze. Se un client dichiara di essere Chrome su Windows ma presenta un fingerprint TLS tipico di una libreria server-side, il sistema può trattare la richiesta con maggiore sospetto. Lo stesso vale per client che cambiano User-Agent continuamente ma mantengono lo stesso fingerprint TLS: il livello HTTP cambia, ma lo stack sottostante resta riconoscibile.
Queste informazioni sono particolarmente utili in sistemi anti-bot, WAF, reverse proxy evoluti, CDN, piattaforme di threat intelligence e soluzioni di monitoraggio del traffico. Il fingerprint TLS non sostituisce le regole tradizionali, ma le arricchisce con un segnale difficilmente disponibile a livello applicativo.
Limiti e falsi positivi
Come ogni tecnica di classificazione, anche il TLS Fingerprinting ha limiti importanti. Il primo è che non identifica univocamente un utente. Più client possono condividere lo stesso fingerprint, specialmente se usano lo stesso browser o la stessa libreria. Al contrario, lo stesso utente può presentare fingerprint diversi cambiando browser, sistema operativo, versione software, rete, proxy o impostazioni.
Il secondo limite è la possibilità di spoofing. Anche se falsificare un fingerprint TLS è più difficile che cambiare uno User-Agent, non è impossibile. Strumenti avanzati possono imitare fingerprint di browser reali o utilizzare direttamente browser automatizzati per produrre handshake più credibili. Di conseguenza, il fingerprint non deve essere considerato una prova assoluta.
Il terzo limite riguarda i contesti legittimi non standard. Monitoraggi esterni, API client, app mobile, integrazioni B2B, sistemi legacy, software embedded e proxy aziendali possono generare fingerprint insoliti senza essere malevoli. Bloccare automaticamente tutto ciò che non assomiglia a un browser mainstream può causare problemi operativi.
Per questo motivo, il TLS Fingerprinting funziona meglio come segnale all’interno di un modello più ampio. Va combinato con reputazione IP, comportamento, frequenza delle richieste, coerenza degli header, cookie, JavaScript challenge, pattern applicativi, geografia, ASN, cronologia degli accessi e sensibilità dell’endpoint richiesto.
Privacy e implicazioni etiche
Il fingerprinting, in generale, solleva sempre questioni legate alla privacy. Anche se il TLS Fingerprinting non legge il contenuto cifrato della comunicazione, osserva metadati tecnici della connessione. Questi metadati possono essere usati per classificare client, riconoscere software e correlare sessioni. È quindi importante usare questa tecnica in modo proporzionato, trasparente e coerente con le finalità di sicurezza.
Dal punto di vista di un gestore di infrastruttura, l’obiettivo dovrebbe essere la protezione del servizio: mitigare bot, abuso, scraping aggressivo, attacchi automatizzati e traffico anomalo. Non dovrebbe diventare uno strumento invasivo di profilazione non necessaria. Come sempre, la differenza la fa il contesto: raccogliere segnali tecnici per difendere un’applicazione è diverso dal costruire profili persistenti senza una motivazione chiara.
In ambito aziendale è opportuno valutare anche gli aspetti normativi, soprattutto quando i fingerprint vengono conservati, correlati con account utente o usati per decisioni automatizzate. La minimizzazione dei dati, la conservazione limitata e l’uso proporzionato sono principi importanti anche quando si lavora con segnali tecnici apparentemente anonimi.
TLS Fingerprinting e infrastrutture hosting
Per chi gestisce infrastrutture hosting, reverse proxy, bilanciatori o WAF, il TLS Fingerprinting può diventare uno strumento molto utile. Un provider che ospita molti siti può osservare pattern ricorrenti di traffico automatizzato: scanner che cercano vulnerabilità WordPress, bot che colpiscono endpoint di login, scraper che attraversano cataloghi WooCommerce o Magento, client che provano path comuni di CMS compromessi.
In questi scenari, il fingerprint TLS può aiutare a distinguere il traffico umano da quello automatizzato, ma soprattutto può aiutare a costruire correlazioni. Lo stesso fingerprint che colpisce centinaia di virtual host con richieste simili è un segnale molto più interessante del singolo IP, soprattutto quando gli IP cambiano continuamente. Molte campagne automatizzate usano infrastrutture distribuite, proxy e indirizzi temporanei, ma mantengono lo stesso stack software.
Naturalmente, l’integrazione deve essere fatta con attenzione. Bloccare in modo aggressivo può generare falsi positivi, mentre limitarsi a osservare senza agire può non essere sufficiente. Una buona strategia può prevedere scoring progressivo: fingerprint sospetto, endpoint sensibile, alta frequenza, assenza di cookie validi, incoerenza tra TLS e User-Agent, ASN a bassa reputazione. Più segnali convergono, più la richiesta può essere limitata, sfidata o bloccata.
Conclusione
Il TLS Fingerprinting è una tecnica potente perché sposta l’osservazione sotto il livello HTTP, analizzando il comportamento del client durante la negoziazione TLS. In un web in cui User-Agent e header sono facilmente falsificabili, l’impronta TLS offre un segnale più profondo e spesso più difficile da manipolare. Non identifica magicamente una persona e non deve essere usato come unico criterio di blocco, ma permette di riconoscere famiglie di client, individuare incoerenze e arricchire i sistemi di sicurezza con informazioni preziose.
Per amministratori di sistema, provider hosting, gestori di WAF e responsabili della sicurezza applicativa, comprendere il TLS Fingerprinting significa avere uno strumento in più per leggere il traffico moderno. Significa capire che due richieste HTTP apparentemente identiche possono provenire da stack TLS completamente diversi. Significa anche riconoscere che la sicurezza efficace non nasce da un singolo indicatore, ma dalla correlazione intelligente di molti segnali.
Usato correttamente, il TLS Fingerprinting può aiutare a contrastare bot, scraping aggressivo, scansioni automatizzate, malware e traffico anomalo. Usato male, può produrre falsi positivi o sollevare problemi di privacy. Come sempre, la differenza sta nella progettazione: osservare, correlare, contestualizzare e intervenire con gradualità. In questo equilibrio, il fingerprint TLS rappresenta una delle tecniche più interessanti per comprendere cosa si nasconde davvero dietro una connessione HTTPS.