
Indice dei contenuti dell'articolo:
Il web non è più frequentato solo dagli utenti
Per anni abbiamo immaginato il traffico web come il risultato dell’interazione tra persone e siti: utenti che leggono articoli, clienti che acquistano prodotti, visitatori che navigano tra pagine, amministratori che accedono a pannelli di controllo, crawler dei motori di ricerca che indicizzano contenuti.
Questa rappresentazione oggi è incompleta.
Una parte sempre più consistente delle richieste HTTP che arrivano a un sito non proviene da persone reali, ma da software automatizzati. Alcuni sono legittimi, come i crawler dei motori di ricerca, gli strumenti di monitoraggio uptime, i sistemi di validazione SEO o i bot utilizzati da servizi esterni autorizzati. Molti altri, invece, sono opachi, indesiderati o apertamente dannosi.
Il dato più significativo è che il traffico bot si sta avvicinando sempre di più al traffico umano, fino a rappresentare, in molti scenari, una quota enorme delle richieste complessive. Il punto critico, però, non è solo la quantità. Il problema reale è la qualità di questo traffico: una parte rilevante dei bot non genera valore, non converte, non acquista, non legge realmente i contenuti e non contribuisce alla crescita del progetto digitale.
Al contrario, consuma risorse.
Consuma banda, CPU, RAM, query database, worker applicativi, capacità di cache, spazio nei log, tempo di analisi e, nei casi peggiori, apre la strada ad attività abusive o fraudolente.
Non tutti i bot sono uguali
Il termine “bot” viene spesso usato in modo generico, ma comprende categorie molto diverse tra loro. Mettere tutto nello stesso contenitore è un errore tecnico e strategico.
Esistono bot utili, come quelli dei motori di ricerca, che permettono l’indicizzazione delle pagine. Esistono bot funzionali, come strumenti di monitoraggio, validatori, sistemi di controllo della disponibilità del sito, servizi di preview social, integrazioni di terze parti e sistemi di automazione legittimi.
Poi esiste una vasta area grigia, molto più problematica. Qui troviamo scraper che raccolgono contenuti, bot che estraggono prezzi e cataloghi, sistemi automatizzati che copiano testi e immagini, crawler non dichiarati usati per addestramento o arricchimento dati, strumenti che simulano browser reali, bot che ruotano IP, user-agent e fingerprint per eludere i controlli.
Infine ci sono i bot apertamente malevoli: scanner di vulnerabilità, credential stuffing, tentativi di brute force, attacchi di account takeover, spam bot, comment spam, form abuse, scraping aggressivo, enumeration di endpoint API, ricerca automatizzata di plugin vulnerabili, probing su path noti come /wp-admin, /xmlrpc.php, /wp-json/, /administrator, /vendor/, /phpmyadmin e così via.
Per un’infrastruttura moderna, la distinzione fondamentale non è più semplicemente tra traffico umano e traffico bot. La distinzione reale è tra traffico utile, traffico tollerabile, traffico sospetto e traffico dannoso.
Il problema dell’identità dichiarata
Uno degli errori più comuni nella gestione dei bot è fidarsi ciecamente dello user-agent.
Lo user-agent è una stringa dichiarata dal client. Può dire di essere un browser, un crawler noto, un sistema di anteprima, un bot AI o qualsiasi altra cosa. Ma dichiarare un’identità non significa dimostrarla.
Un bot malevolo può presentarsi come un crawler legittimo. Può usare un nome rassicurante, imitare un browser diffuso, ruotare intestazioni HTTP, cambiare IP, rispettare parzialmente alcuni pattern di navigazione e cercare di sembrare umano. Può anche alternare comportamenti lenti e aggressivi per evitare soglie semplicistiche di rate limiting.
Per questo motivo, una strategia basata solo su user-agent, robots.txt o liste statiche è debole. È utile come primo livello, ma non può essere considerata una difesa sufficiente.
Servono controlli più profondi: reverse DNS coerente per i bot noti, verifica dell’ASN, analisi comportamentale, reputazione IP, coerenza degli header, fingerprint TLS, frequenza delle richieste, distribuzione geografica, pattern di navigazione, accesso a risorse dinamiche, ripetitività, profondità di crawling e impatto sull’origine.
Cache, CDN e contenuti statici: il falso senso di sicurezza
Molte aziende considerano i contenuti serviti da cache come meno sensibili. Se una pagina è pubblica e cacheable, si tende a pensare che non ci sia un vero problema se viene richiesta da bot. In fondo, non sta colpendo direttamente il backend, non genera query al database e non consuma PHP, Node.js, Java o altri processi applicativi.
Questa visione è parziale.
Anche quando la cache riduce il costo computazionale, il problema rimane: chi sta accedendo ai contenuti? Con quale frequenza? Con quale finalità? Sta creando valore o sta solo estraendo dati?
Per un sito editoriale, uno scraper può copiare articoli e ripubblicarli altrove. Per un e-commerce, può monitorare prezzi, disponibilità, variazioni di catalogo, strategie commerciali e promozioni. Per una piattaforma SaaS, può enumerare documentazione, changelog, endpoint pubblici e informazioni utili per successive attività offensive.
La cache protegge le performance, ma non protegge necessariamente il valore informativo del contenuto.
In altre parole, una pagina servita velocemente non è automaticamente una pagina servita al soggetto giusto. La cache è uno strumento di efficienza, non una politica di controllo dell’accesso.
Quando i bot arrivano all’origine, il costo diventa concreto
Il problema diventa ancora più evidente quando i bot non si fermano ai contenuti statici o cacheable, ma raggiungono l’origine: backend applicativo, database, motore di ricerca interno, API, checkout, login, carrello, endpoint amministrativi o pagine personalizzate.
In quel caso il traffico automatizzato non è più solo una questione di visibilità o controllo dei contenuti. Diventa un costo diretto.
Ogni richiesta dinamica può attivare PHP-FPM, query MySQL o MariaDB, chiamate Redis, logica applicativa, sistemi di sessione, plugin, moduli, hook, chiamate verso terze parti, generazione HTML, controlli ACL, funzioni di ricerca, calcolo prezzi, disponibilità magazzino, coupon, spedizioni e così via.
Questo aspetto è particolarmente rilevante per siti WordPress, WooCommerce, Magento, PrestaShop, portali editoriali e applicazioni con API pubbliche.
Un bot che interroga pagine cacheable può essere fastidioso. Un bot che forza costantemente MISS di cache, query dinamiche, ricerche interne, filtri prodotto, carrelli, login e API può diventare un problema di performance, costo infrastrutturale e sicurezza.
Il caso degli e-commerce
Gli e-commerce sono tra i bersagli più interessanti per il traffico automatizzato. Non solo per attacchi classici come credential stuffing o carding, ma anche per attività economicamente motivate.
Un bot può monitorare prezzi e disponibilità dei prodotti, copiare schede prodotto, raccogliere immagini, identificare promozioni, verificare coupon, simulare carrelli, controllare endpoint di checkout, testare credenziali rubate, creare account falsi, saturare funzioni di ricerca o tentare scraping massivo del catalogo.
In piattaforme come WooCommerce, Magento o PrestaShop, il problema è amplificato dal fatto che molte richieste apparentemente innocue possono diventare dinamiche. Filtri, ricerche, ordinamenti, paginazioni, combinazioni di attributi, variazioni prodotto, carrelli e sessioni possono bypassare la cache o ridurne drasticamente l’efficacia.
Il risultato è un’infrastruttura che sembra sottodimensionata non perché gli utenti reali siano troppi, ma perché una parte significativa della capacità viene consumata da automazioni che non generano ricavi.
A questo si aggiunge un ulteriore problema, spesso meno visibile: l’impatto sui servizi esterni a consumo collegati al sito. Molti e-commerce integrano piattaforme di marketing automation, CRM, sistemi di live chat, notifiche push, email marketing, analytics avanzati, recommendation engine o strumenti di customer engagement. Servizi come Motive, ad esempio, vengono spesso utilizzati per attività di automazione marketing, recupero carrelli, messaggistica, segmentazione utenti o interazioni commerciali basate sul comportamento dei visitatori.
Se il traffico bot viene interpretato come traffico reale, questi strumenti possono ricevere un numero anomalo di eventi, sessioni, visite, carrelli simulati o interazioni. Il rischio è duplice: da un lato si sporcano i dati analitici e le segmentazioni; dall’altro, nei servizi con piani basati su volumi, contatti, eventi o visite mensili, il traffico artificiale può contribuire a far superare le soglie previste dal piano attivo, portando a upgrade forzati, costi aggiuntivi o necessità di passare a un abbonamento superiore.
Questo è un punto spesso sottovalutato: non tutto il traffico è business. Un sito può avere numeri apparentemente elevati, molte richieste al secondo, log pieni e grafici in crescita, ma se una parte rilevante di quel traffico è composta da bot indesiderati, quei numeri non rappresentano successo. Rappresentano consumo.
Il caso WordPress: XML-RPC, REST API, login e commenti
Nel mondo WordPress il traffico bot è una costante quotidiana. Anche siti piccoli o medi ricevono continuamente richieste automatiche verso path noti.
Tra i bersagli più frequenti ci sono /wp-login.php, /xmlrpc.php, /wp-json/, endpoint REST, feed, sitemap, pagine autore, query parameter usati per enumerare contenuti, file di plugin vulnerabili, vecchi path di backup, archivi, upload e risorse statiche.
Molti attacchi non sono sofisticati. Sono semplicemente massivi, distribuiti e persistenti. Il singolo tentativo può sembrare irrilevante, ma migliaia o milioni di richieste nel tempo generano rumore, log, carico, falsi positivi, consumo di banda, saturazione dei worker e peggioramento del TTFB.
In WordPress, inoltre, il problema non è solo “bloccare i cattivi”. È evitare che traffico inutile faccia partire l’intero stack applicativo. Una richiesta gestita a livello Nginx, WAF o reverse proxy costa molto meno di una richiesta che arriva fino a PHP e al database.
Per questo motivo, in ambienti WordPress ben gestiti, la protezione dai bot dovrebbe partire prima dell’applicazione: a livello di web server, reverse proxy, firewall applicativo, cache e regole di accesso.
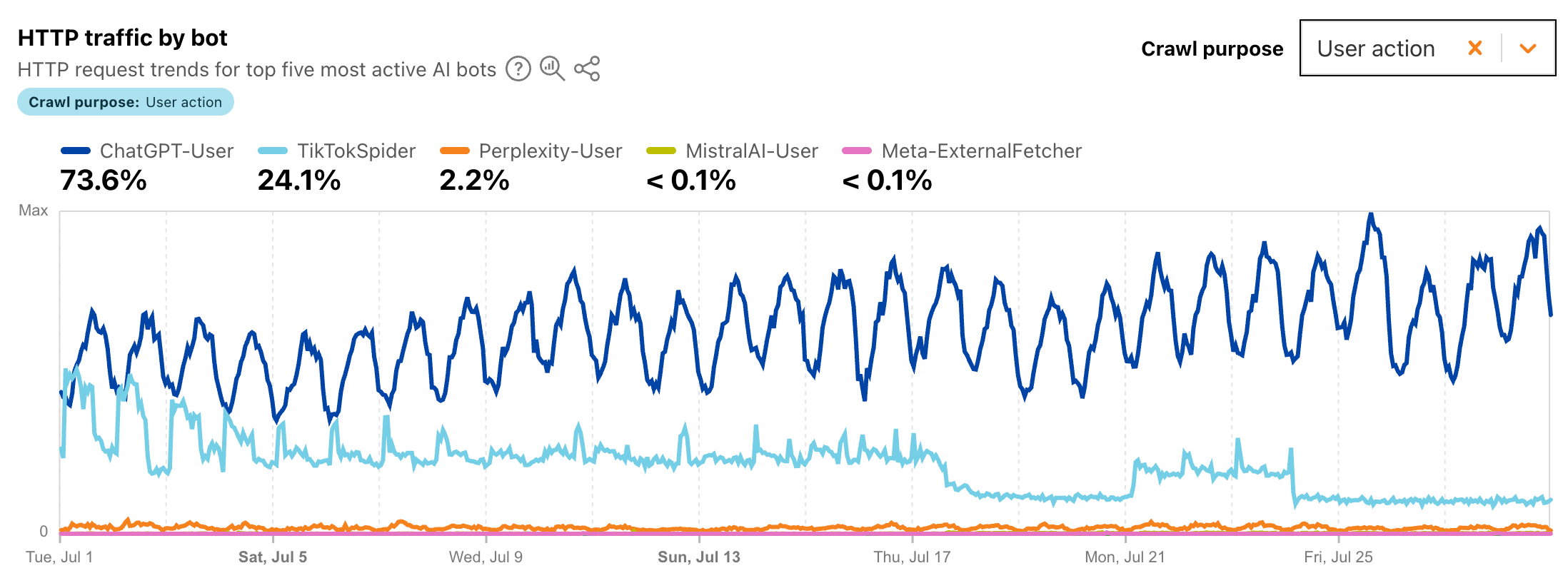
Bot AI: pochi rispetto al totale, ma molto influenti
Una delle novità più rilevanti riguarda i bot legati all’intelligenza artificiale. In termini percentuali possono rappresentare una quota inferiore rispetto al traffico bot complessivo, ma il loro impatto può essere sproporzionato.
I crawler e fetcher AI non si limitano a indicizzare pagine come i motori di ricerca tradizionali. Possono raccogliere contenuti, elaborarli, sintetizzarli, riutilizzarli in risposte generate, scollegare l’informazione dalla fonte originaria e ridurre la necessità per l’utente finale di visitare il sito che ha prodotto quel contenuto.
Questo introduce una questione strategica nuova: un contenuto può essere letto, assimilato e riutilizzato da sistemi automatici senza generare traffico diretto, lead, conversioni o riconoscimento sufficiente per l’editore originale.
Il problema non riguarda solo il copyright o la visibilità del brand. Riguarda anche l’infrastruttura. Se un crawler AI accede a contenuti dinamici, pagine non cacheable, ricerche interne o endpoint specifici, ogni richiesta può generare costo computazionale senza un ritorno proporzionato.
Il tema, quindi, non è demonizzare l’intelligenza artificiale, ma stabilire regole. Chi può accedere? A quali contenuti? Con quale frequenza? Con quale identificazione? Con quale beneficio per il proprietario del sito?
Robots.txt non basta più
Per anni il file robots.txt è stato considerato lo strumento principale per comunicare ai crawler cosa possono o non possono visitare. Rimane utile, ma ha un limite strutturale: funziona solo con bot collaborativi.
Un bot malevolo può ignorarlo completamente. Uno scraper aggressivo può leggerlo addirittura per capire quali aree evitare in apparenza e quali endpoint potrebbero essere più interessanti. Un sistema automatizzato può dichiararsi come un bot noto senza rispettarne realmente le regole.
Anche i meta tag noindex, gli header X-Robots-Tag e le direttive simili sono strumenti di policy, non barriere tecniche. Sono indicazioni. Non impediscono fisicamente l’accesso.
Per questo motivo, la gestione moderna dei bot deve combinare dichiarazioni pubbliche, controlli tecnici e osservabilità.
Il robots.txt serve a comunicare. Il WAF serve a difendere. Il reverse proxy serve a governare. I log servono a capire. Confondere questi ruoli porta a strategie fragili.
Il problema della visibilità
Molte organizzazioni non sanno realmente quanto traffico bot ricevono. Guardano Google Analytics, Search Console o strumenti simili, ma questi sistemi vedono solo una parte del fenomeno.
Molti bot non eseguono JavaScript, non caricano tag analytics, non accettano cookie, non seguono il comportamento di un browser reale e non vengono conteggiati correttamente nelle statistiche marketing.
Il paradosso è che l’infrastruttura vede il traffico, ma il reparto marketing spesso no. Il server lo gestisce, il WAF lo registra, il reverse proxy lo serve, il database può subirne gli effetti, ma le dashboard analitiche tradizionali possono sottostimarlo drasticamente.
Per capire davvero il fenomeno bisogna guardare i log HTTP, i log del reverse proxy, i log applicativi, i codici di risposta, le latenze, la cache hit ratio, gli IP sorgenti, gli ASN, gli user-agent, gli endpoint più colpiti, la percentuale di richieste cache HIT e MISS, la frequenza per client, la distribuzione geografica e la correlazione con picchi di CPU, RAM, I/O e query database.
Senza questa visibilità, si rischia di ottimizzare la parte sbagliata del sistema.
Dalla sicurezza alla performance
La gestione dei bot viene spesso trattata come tema di sicurezza. È corretto, ma riduttivo.
I bot incidono anche sulle performance. Un sito può avere tempi di risposta peggiori non perché sia mal ottimizzato in senso assoluto, ma perché sta servendo troppo traffico non umano. In particolare, le richieste che generano cache MISS, query pesanti, ricerche interne o sessioni possono aumentare il TTFB percepito dagli utenti reali.
In un e-commerce, questo può tradursi in checkout più lenti, ricerca prodotto meno reattiva, backend amministrativo appesantito, processi PHP saturi, database sotto stress e maggiore probabilità di errori 502, 503 o timeout.
La conseguenza è semplice: la bot mitigation è anche una strategia di web performance.
Bloccare o limitare traffico inutile a monte significa liberare risorse per gli utenti reali. Significa migliorare stabilità, ridurre il carico, contenere i costi e rendere più prevedibile il comportamento dell’infrastruttura.
Un’infrastruttura veloce non è solo quella che risponde rapidamente. È quella che sa anche decidere a chi vale la pena rispondere.
Non bisogna bloccare tutto
Una strategia ingenua potrebbe essere: “blocchiamo tutti i bot”. Ma non è quasi mai la scelta corretta.
Alcuni bot servono. I crawler dei motori di ricerca sono fondamentali per la SEO. I sistemi di monitoraggio sono necessari per rilevare downtime. Alcuni servizi di terze parti devono accedere a endpoint specifici. I social network generano anteprime. I marketplace possono verificare feed e disponibilità. Alcuni sistemi AI, se governati correttamente, potrebbero persino portare visibilità indiretta.
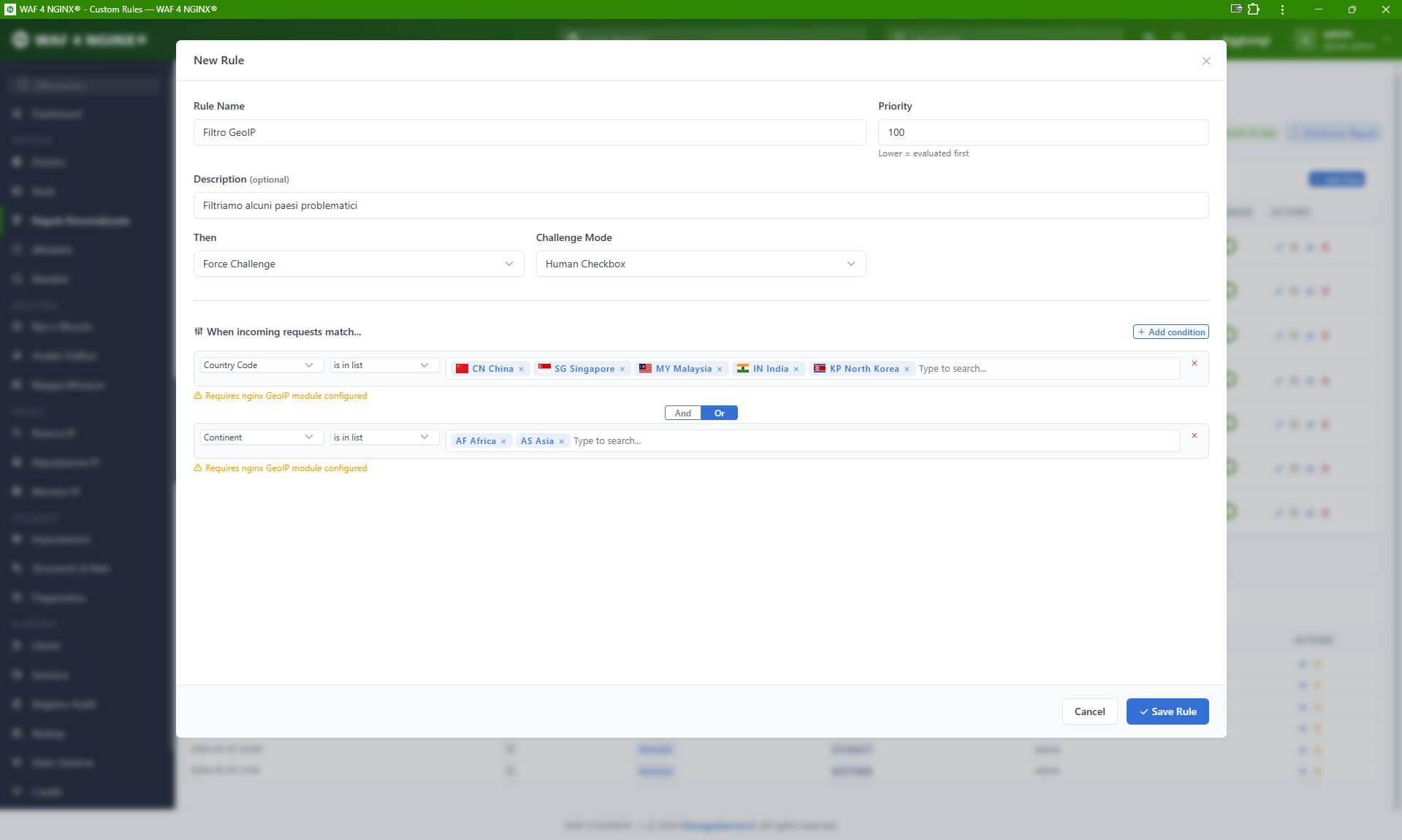
Il punto non è bloccare indiscriminatamente. Il punto è decidere.
Quali bot sono ammessi? Su quali path? Con quale frequenza? Possono accedere a pagine dinamiche? Possono interrogare la ricerca interna? Possono colpire endpoint API? Devono essere limitati per ASN, nazione, fingerprint o comportamento? Devono ricevere contenuti completi, contenuti ridotti o risposte differenziate? Devono essere bloccati solo quando superano certe soglie?
La gestione moderna dei bot è granulare.
Bloccare tutto è semplice, ma spesso dannoso. Governare il traffico è più complesso, ma molto più efficace.
Policy diverse per contenuti diversi
Non tutti i contenuti hanno lo stesso valore e non tutti gli endpoint hanno lo stesso costo.
Una homepage cacheable non è uguale a una ricerca interna. Una scheda prodotto non è uguale a un endpoint di checkout. Un articolo pubblico non è uguale a un’area riservata. Una sitemap non è uguale a una REST API. Un’immagine statica non è uguale a una pagina generata dinamicamente con decine di query.
Per questo motivo, le policy dovrebbero essere differenziate.
Si può essere più permissivi sulle risorse statiche e più restrittivi sugli endpoint dinamici. Si può consentire la scansione delle sitemap, ma limitare la frequenza di accesso alle pagine prodotto. Si può permettere l’accesso ai crawler verificati dei motori di ricerca, ma bloccare user-agent falsificati. Si può applicare rate limiting severo a login, carrello, checkout, ricerca interna e API.
Questa distinzione permette di ridurre il rumore senza danneggiare il traffico realmente utile.
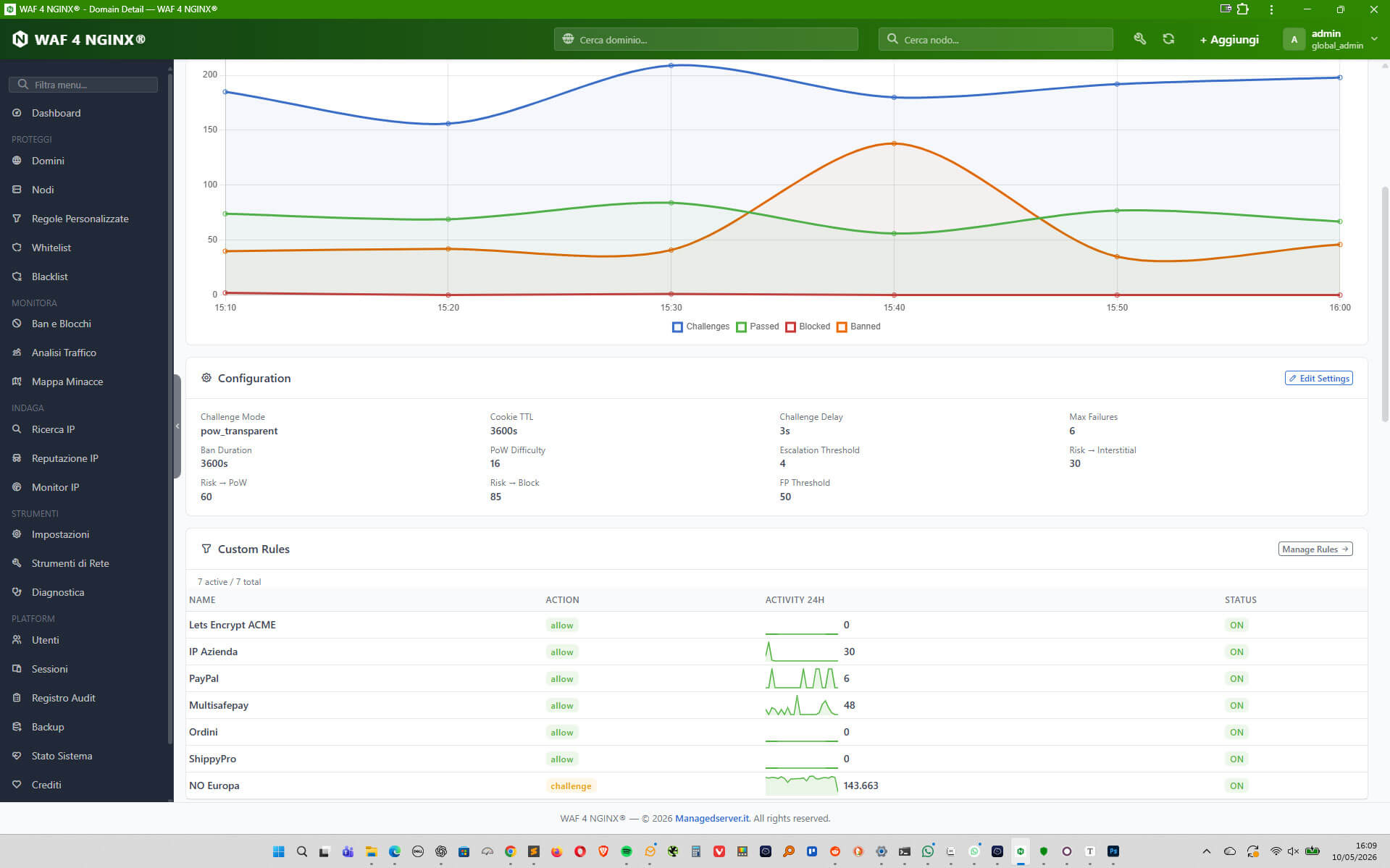
Il ruolo del reverse proxy e del WAF
La mitigazione efficace deve avvenire il più possibile vicino al bordo dell’infrastruttura, prima che la richiesta arrivi all’applicazione.
In un’architettura tipica, Nginx, Varnish, HAProxy, un WAF o un reverse proxy evoluto possono intercettare e filtrare molte richieste prima che raggiungano PHP-FPM, Node.js, Java, database o backend applicativi.
Questo approccio ha due vantaggi. Il primo è prestazionale: una richiesta bloccata a monte costa pochissimo. Il secondo è di sicurezza: riduce la superficie di attacco dell’applicazione.
Regole basate su path, metodo HTTP, header, user-agent, IP reputation, ASN, geolocalizzazione, rate, cookie, presenza di JavaScript challenge, comportamento e coerenza della richiesta possono ridurre drasticamente il traffico indesiderato.
L’importante è non trasformare il WAF in un muro cieco. Le regole devono essere osservabili, testate, versionate e adattate al contesto specifico del sito.
Una buona regola di sicurezza è quella che blocca il traffico sbagliato senza penalizzare quello giusto.
Rate limiting intelligente
Il rate limiting è uno degli strumenti più utili, ma deve essere applicato con criterio.
Limitare semplicemente il numero di richieste per IP può funzionare contro bot primitivi, ma è meno efficace contro reti distribuite, proxy residential, botnet o sistemi che ruotano indirizzi. Inoltre, soglie troppo aggressive possono penalizzare utenti reali, crawler legittimi o aziende dietro NAT condivisi.
Un rate limiting moderno dovrebbe considerare più dimensioni: IP, subnet, ASN, user-agent, endpoint, metodo HTTP, cookie di sessione, autenticazione, paese, fingerprint, risposta generata e costo della richiesta.
Una richiesta a un file CSS non ha lo stesso peso di una richiesta a una ricerca interna. Una richiesta GET a una pagina cacheable non ha lo stesso impatto di una POST verso un form di login. Un accesso sporadico alla sitemap non è paragonabile a centinaia di richieste al minuto verso filtri prodotto.
Il rate limiting migliore non conta solo le richieste. Conta il costo e il rischio.
Bot e API: una superficie spesso sottovalutata
Le API sono un bersaglio naturale per il traffico automatizzato. Sono strutturate, prevedibili, facilmente interrogabili e spesso restituiscono dati in formato comodo da elaborare.
Molti siti proteggono le pagine HTML ma lasciano endpoint API poco controllati. Questo vale per REST API, GraphQL, endpoint custom, AJAX, feed JSON, integrazioni mobile, app headless e sistemi interni esposti pubblicamente.
Gli attacchi alle API possono includere enumeration di ID, scraping di dati, abuso di funzioni di ricerca, credential stuffing, bypass logici, abuso di coupon, tentativi di accesso a dati non autorizzati e consumo eccessivo di risorse.
Per questo motivo, la protezione dai bot non deve fermarsi al frontend. Deve includere anche API gateway, autenticazione, autorizzazione, schema validation, limiti per token, controllo dei metodi, protezione da query costose e logging dettagliato.
Un’API pubblica senza limiti chiari è spesso un invito all’automazione abusiva.
L’impatto economico nascosto
Il traffico bot ha un costo anche quando non causa incidenti evidenti.
Consuma banda. Aumenta le richieste servite dalla CDN o dal reverse proxy. Genera log. Occupa storage. Fa crescere il volume dei dati da analizzare. Può aumentare i costi cloud, i costi di egress, i costi di logging e monitoring. Può obbligare a sovradimensionare server, database, cache e bilanciatori.
In ambienti ad alto traffico, anche una piccola percentuale di richieste dinamiche inutili può tradursi in costi significativi. In ambienti più piccoli, invece, può bastare uno scraping aggressivo per saturare risorse e compromettere l’esperienza degli utenti reali.
Questo è particolarmente importante per chi gestisce hosting, e-commerce e applicazioni con margini sensibili. Pagare infrastruttura per servire traffico che non produce valore significa ridurre efficienza e redditività.
Il traffico non umano non è gratuito. Anche quando non compra, non converte e non interagisce, viene comunque servito da qualcuno.
Dalla difesa passiva alla governance dell’accesso
La vera evoluzione è culturale: non bisogna più pensare ai bot solo come minaccia da bloccare, ma come soggetti da governare.
Ogni richiesta automatizzata dovrebbe essere valutata in base a tre domande.
Chi è il richiedente?
È un bot verificato, un crawler noto, un sistema interno, un servizio partner, un client sospetto o un’identità falsificata?
Che cosa sta facendo?
Sta leggendo contenuti pubblici, interrogando endpoint dinamici, tentando login, scansionando vulnerabilità, copiando cataloghi, eseguendo ricerche o accedendo ad API?
Qual è il valore o il rischio?
Porta traffico utile, indicizzazione, monitoraggio e visibilità, oppure genera solo costo, esposizione, scraping e potenziale abuso?
Solo rispondendo a queste domande è possibile costruire una policy sensata.
Cosa dovrebbe fare un’azienda oggi
Il primo passo è misurare. Senza misurazione, ogni decisione è arbitraria.
Bisognerebbe analizzare almeno trenta giorni di log, distinguendo traffico umano, bot noti, bot sospetti, traffico non classificato, richieste cache HIT, richieste cache MISS, endpoint dinamici più colpiti, IP e ASN più attivi, user-agent più frequenti, codici di risposta, tassi di errore e correlazione con picchi infrastrutturali.
Il secondo passo è classificare. Non tutti i bot devono essere trattati allo stesso modo. Bisogna creare categorie operative: consentiti, limitati, monitorati, sfidati, bloccati.
Il terzo passo è applicare controlli progressivi. Prima logging e alerting, poi regole soft, poi rate limiting, poi blocchi selettivi. Le regole troppo aggressive applicate senza osservazione possono causare danni a SEO, integrazioni e utenti reali.
Il quarto passo è proteggere gli endpoint più costosi: login, carrello, checkout, ricerca interna, API, XML-RPC, REST API, aree amministrative, form, pagine con query complesse, feed dinamici.
Il quinto passo è rivedere periodicamente le policy. I bot cambiano rapidamente. Nuovi crawler emergono, vecchi user-agent vengono falsificati, nuove reti proxy vengono usate, nuove tecniche di evasione diventano comuni.
La gestione dei bot non è un’attività da configurare una volta e dimenticare. È un processo continuo.
Conclusione
Il web moderno non è più composto principalmente da persone che visitano pagine. È un ecosistema misto, in cui utenti reali, crawler legittimi, automazioni commerciali, scraper, bot malevoli e sistemi AI competono per accedere agli stessi contenuti e alle stesse risorse.
Quando una quota enorme del traffico può essere non umana, la gestione dei bot non è più un dettaglio tecnico. Diventa un tema di sicurezza, performance, costi, SEO, protezione dei contenuti e strategia aziendale.
La domanda non è più se un sito riceverà traffico automatizzato. Lo riceve già.
La vera domanda è se l’infrastruttura è in grado di distinguerlo, misurarlo, limitarlo e governarlo senza danneggiare gli utenti reali e senza rinunciare ai bot che generano valore.
In un contesto in cui l’intelligenza artificiale, lo scraping e l’automazione stanno ridefinendo il modo in cui i contenuti vengono raccolti, riassunti e consumati, il controllo dell’accesso diventa una leva fondamentale.
Chi saprà gestire i bot in modo selettivo e intelligente avrà siti più veloci, infrastrutture più efficienti, costi più prevedibili e maggiore controllo sui propri contenuti. Chi continuerà a ignorare il problema rischierà invece di pagare, in termini economici e prestazionali, per traffico che non porta alcun beneficio reale.