
Indice dei contenuti dell'articolo:
Kubernetes ha vinto le guerre dei container presumibilmente. Tuttavia, Kubernetes è ancora difficile e causa un sacco di dolori.
Credo che dovrei dare una piccola prefazione a questo articolo. Kubernetes è il nuovo runtime per molte applicazioni e se usato correttamente può essere un potente strumento per ottenere la complessità dal vostro ciclo di vita di sviluppo. Tuttavia, negli ultimi anni ho visto molte persone e aziende inciampare nel desiderio di gestire la propria installazione. Spesso rimane in fase sperimentale e non entra mai in produzione.
Come funziona Kubernetes?
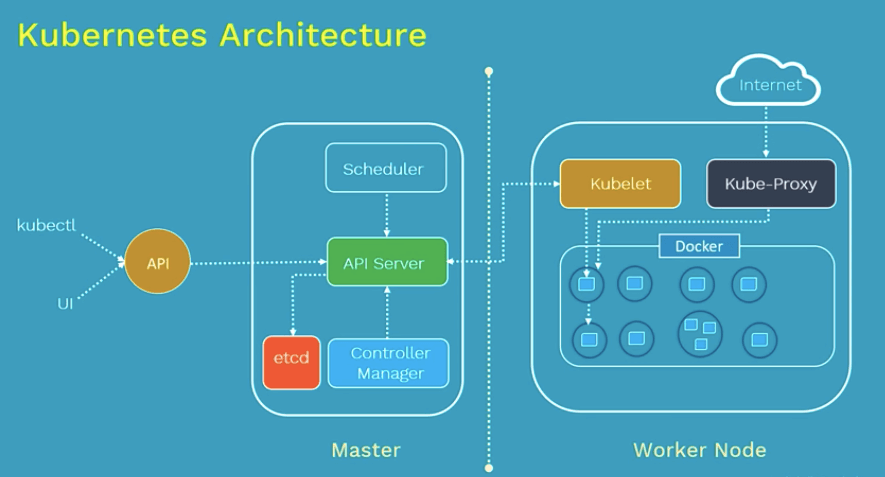
In ampi tratti, Kubernetes o K8s sembra essere molto semplice. I nodi (macchine) su cui si esegue Kubernetes sono divisi in (almeno) due tipi: il master e i worker. Il master (o i master), per impostazione predefinita, non esegue alcun carico di lavoro effettivo, questo è il lavoro dei workers. Il master Kubernetes include un componente chiamato API server che fornisce un’API con cui puoi parlare usando il kubectl. Inoltre include anche un pianificatore, che prende decisioni su quale contenitore deve essere eseguito dove (pianifica i contenitori). Il componente finale è il controller-manager, che in realtà è un insieme di controllori multipli responsabili della gestione delle interruzioni dei nodi, della gestione delle repliche, dell’unione di servizi e pod (insiemi di container), e infine della gestione degli account di servizio e dei token di accesso alle API. Tutti i dati sono memorizzati in etcd, che è un database di valori chiave fortemente consistente (con alcune caratteristiche davvero interessanti). Quindi, per riassumere, il master è responsabile della gestione del cluster. Non c’è da stupirsi. Il worker, d’altra parte, sta gestendo i carichi di lavoro effettivi. A tal fine comprende, ancora una volta, una serie di componenti. Prima di tutto, esegue il kubelet, che è di nuovo un’API che funziona con i contenitori su quel nodo. C’è anche il kube-proxy, che inoltra le connessioni di rete, containerd per eseguire container, e a seconda della configurazione ci possono essere altre cose come kube-dns o gVisor. Avrete anche bisogno di una sorta di rete overlay o di un’integrazione con la vostra configurazione di rete sottostante in modo che Kubernetes possa gestire la rete tra i vostri pod.
Kubernetes pronto per la produzione
Questo, finora, non suona troppo male. Installare un paio di programmi, configurazioni, certificati, ecc. Non fraintendetemi, è ancora una curva di apprendimento, ma non è niente con cui un sysadmin medio non abbia avuto a che fare in passato. Tuttavia, la semplice installazione manuale di Kubernetes non è esattamente pronta per la produzione, quindi parliamo dei passi necessari per mettere in funzione questa cosa. In primo luogo, l’installazione.
Vuoi davvero avere una sorta di installazione automatizzata. Non importa se si tratta di Ansible, Terraform o altri strumenti, si desidera che sia automatizzato. kops, per esempio, aiuta in questo, ma usare kops significa che non si sa esattamente come è impostato e che può causare problemi quando si desidera successivamente eseguire il debug di qualcosa. Questa automazione dovrebbe essere testata e testata regolarmente. Successivamente, è necessario monitorare l’installazione di Kubernetes. Quindi subito ti serve qualcosa come Prometeo, Grafana, ecc. Lo fai correre all’interno dei tuoi Kubernetes? Se il vostro Kubernetes ha un problema, il vostro monitoraggio è interrotto? O lo gestisci separatamente? Se sì, allora dove lo gestisci?
Degni di nota sono anche i backup.
Cosa farete se il vostro master si blocca, i dati sono irrecuperabili e avete bisogno di ripristinare tutti i pod sul sistema? Hai testato quanto tempo ci vuole per eseguire di nuovo tutti i lavori nel tuo sistema ? Hai un piano di recupero in caso di disastro? Ora, visto che stiamo parlando del sistema CI, è necessario eseguire un registro Docker per le immagini. Questo, naturalmente, si può fare di nuovo in Kubernetes, ma se Kubernetes si blocca. Anche il sistema CI è ovviamente un problema, così come il sistema di controllo della versione. Idealmente, isolato dal vostro ambiente di produzione in modo che se quel sistema ha un problema, almeno potete accedere al vostro git, reimpiegare, ecc.
Data Storage
Parliamo dell’elefante nella stanza: la memorizzazione. Kubernetes in sé e per sé non fornisce una soluzione di stoccaggio. Naturalmente, è possibile montare una cartella dalla macchina host, ma questo non è né raccomandato, né semplice. Rok, per esempio, rende relativamente semplice utilizzare Ceph come memoria di blocco sottostante per le vostre esigenze di archiviazione dei dati, ma la mia esperienza con Ceph è che ha un sacco di valori e configurazioni che necessitano di tuning, quindi non siete affatto fuori dai guai semplicemente avanzando al prossimo step.
Debugging
Quando si parlava di Kubernetes con gli sviluppatori, uno schema comune si presentava abbastanza regolarmente: quando si usava un Kubernetes gestito, la gente aveva problemi di debug delle proprie applicazioni. Anche problemi semplici, come il mancato avvio di un contenitore, hanno causato confusione. Questo, naturalmente, è un problema di istruzione. Negli ultimi decenni gli sviluppatori hanno imparato il debug delle configurazioni “classiche”: leggere i file di log in /var/log, ecc. ma con i container non sappiamo nemmeno su quale server è in esecuzione il container, quindi presenta un cambiamento di paradigma.
Il problema complessità
Potreste aver notato che sto saltando le cose che i fornitori di cloud ti danno, anche se non si tratta di un Kubernetes completamente gestito. Naturalmente, se usate una soluzione gestita da Kubernetes, è fantastico, e non avrete bisogno di occuparvi di nulla di tutto questo, tranne che per il debug. Kubernetes ha molte parti mobili, e Kubernetes da solo non fornisce una pila completa di soluzioni. RedHat OpenShift, ad esempio, lo fa, ma costa e devi ancora aggiungere le cose da solo. In questo momento Kubernetes è sulla collina del ciclo dell’hype di Gartner, tutti lo vogliono, ma pochi lo capiscono veramente. Nei prossimi anni parecchie aziende dovranno rendersi conto che Kubernetes non è la soluzione a tutti i mali e capire come usarlo in modo corretto ed efficiente.
Penso che far funzionare il proprio Kubernetes ne valga la pena solo se ci si può permettere di dedicare un team operativo al tema del mantenimento della piattaforma sottostante per i propri sviluppatori.