
Indice dei contenuti dell'articolo:
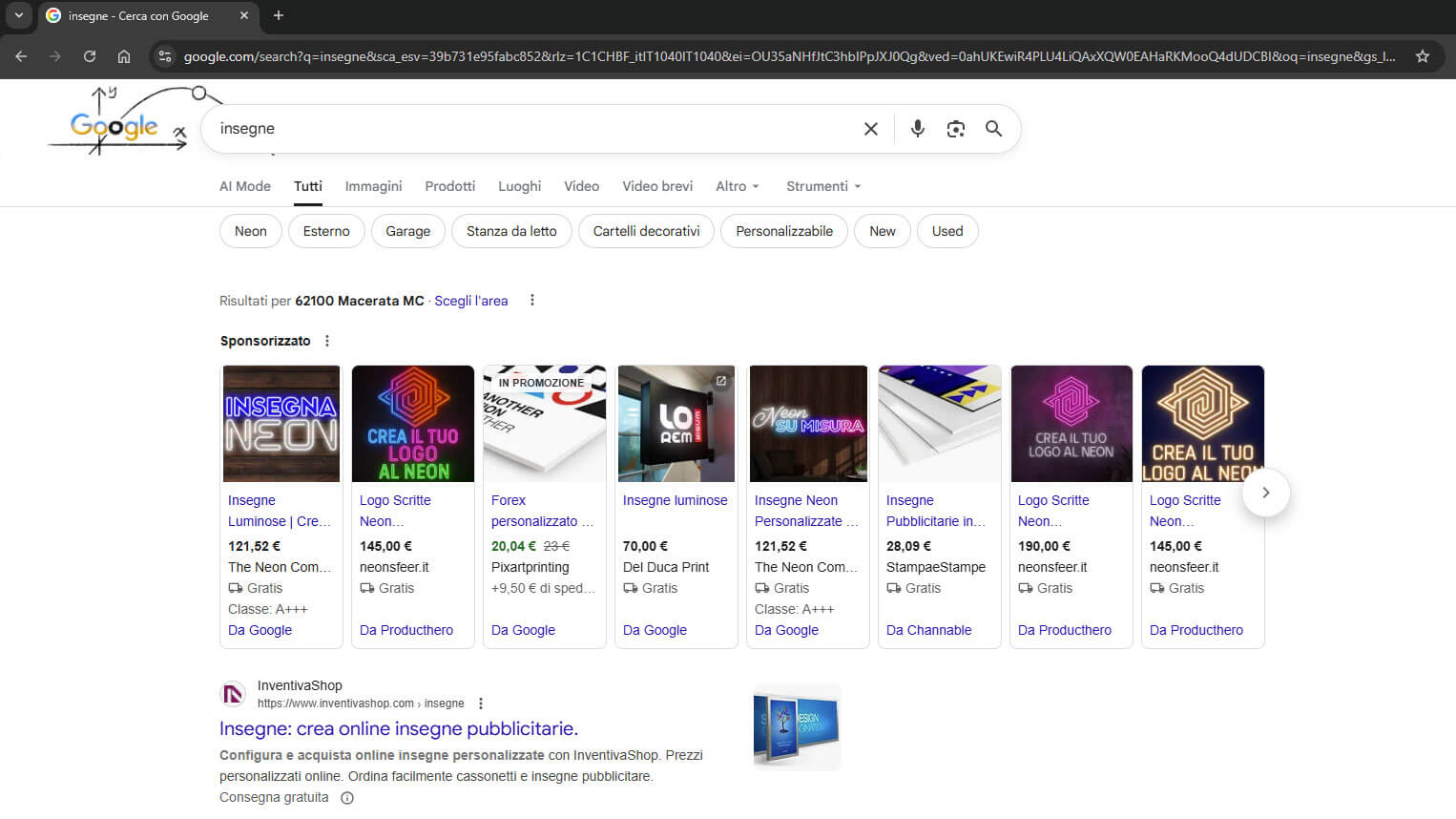
Nel panorama dell’e-commerce moderno, ogni millisecondo conta. Quando si parla di performance web e posizionamento sui motori di ricerca, la velocità del sito non è più un optional ma un requisito fondamentale. Questo è particolarmente vero per siti ad alto traffico come inventivashop.com, che domina la prima posizione su Google per parole chiave competitive come “Insegne”.
Il sito in questione rappresenta un caso studio eccellente di come un’infrastruttura già ampiamente ottimizzata possa comunque nascondere colli di bottiglia critici che, una volta identificati e risolti, portano a miglioramenti prestazionali straordinari. In questo articolo tecnico condivideremo il nostro approccio metodico all’ottimizzazione di una query SQL particolarmente problematica, dimostrando come sia stato possibile ottenere un miglioramento delle performance del 99,83% — passando da 1,8 secondi a soli 3 millisecondi.
Il contesto: un’infrastruttura già al top
Prima di addentrarci nel caso specifico, è importante sottolineare che inventivashop.com non partiva certo da zero in termini di ottimizzazione. Il sito beneficiava già di un arsenale completo di tecnologie e best practices:
Stack tecnologico all’avanguardia
- HTTP/3: Protocollo di nuova generazione per connessioni più veloci e resilienti
- ZSTD Compression: Compressione avanzata per ridurre il payload delle risposte
- NGINX ottimizzato: Tuning a livello webserver con configurazioni personalizzate per massime performance
- Certificati TLS compressi: Riduzione dell’overhead SSL/TLS
- Supporto WebP: Immagini di nuova generazione con dimensioni ridotte fino al 30%
- Core Web Vitals ottimizzati: Tutte le best practices implementate per LCP, FID, CLS
- Percona Server 5.7: Database server ottimizzato al posto di MySQL vanilla
Quest’ultimo punto merita particolare attenzione. La scelta di Percona Server 5.7, pur essendo in End of Life da novembre 2024, non è stata casuale ma il risultato di benchmark approfonditi che hanno evidenziato performance superiori rispetto a MariaDB per le specifiche query del sito.
La scelta controversa: Percona Server 5.7 in EOL
Durante i test preliminari, avevamo identificato una query critica che mostrava comportamenti drasticamente diversi tra i vari database engine:
- MariaDB 10.x: 1.700-1.800 ms
- MySQL 8.0: 1.500-1.600 ms
- Percona Server 5.7: 200 ms
La differenza era così marcata (circa 9x più veloce) che abbiamo dovuto prendere una decisione difficile: utilizzare una versione EOL ma con performance nettamente superiori, implementando naturalmente tutte le misure di sicurezza necessarie (isolamento di rete, hardening, monitoring continuo).
Il problema: quando un singolo modulo mette in ginocchio il sito
Nonostante tutte queste ottimizzazioni, il monitoraggio delle performance continuava a evidenziare un problema ricorrente e significativo. Le metriche mostravano picchi di latenza inspiegabili, e il Time To First Byte (TTFB) risultava ben al di sopra dei nostri standard in determinate pagine.
Il modulo BlockLayered: indispensabile ma pesante
Il colpevole si è rivelato essere il modulo blocklayered di PrestaShop (nelle versioni più recenti rinominato “Faceted Search” o “Ricerca a strati”). Questo modulo è fondamentale per qualsiasi e-commerce moderno perché gestisce:
- Filtri di categoria (prezzo, colore, taglia, marca, ecc.)
- Navigazione sfaccettata nei prodotti
- Conteggi dinamici dei prodotti per ogni filtro
- Aggregazioni e ordinamenti complessi
Il modulo viene invocato praticamente in ogni pagina di categoria, ricerca o listing prodotti — ovvero nelle pagine più visitate di un e-commerce. Una sua inefficienza si ripercuote quindi sull’intera esperienza utente e, di conseguenza, sui tassi di conversione.
La scoperta: 1,8 secondi per una singola query
Attraverso l’analisi sistematica delle slow query log e l’utilizzo di Percona Toolkit (pt-query-digest), abbiamo identificato la query problematica. I numeri erano allarmanti:
- Tempo medio di esecuzione: 1.700-1.800 ms
- Frequenza: Migliaia di volte al giorno
- Impatto totale: Decine di minuti di tempo CPU sprecato ogni ora
- Pattern: Presente in ogni navigazione di categoria con filtri
Per contestualizzare: in un’architettura ben ottimizzata, ci aspettiamo che le query di lettura su cataloghi prodotti richiedano 10-50ms. Una query da quasi 2 secondi è circa 40-180 volte più lenta del dovuto.
L’approccio diagnostico
Avremmo potuto utilizzare soluzioni APM (Application Performance Monitoring) come New Relic, che avrebbero fornito una visione olistica delle performance applicative. Tuttavia, data la natura concentrata del problema — una singola query molto frequente e molto lenta — abbiamo optato per un approccio più chirurgico:
- Abilitazione slow query log su Percona Server
- Raccolta dati per 24-48 ore
- Analisi con pt-query-digest per identificare pattern e normalizzare le query
- EXPLAIN ANALYZE per comprendere il piano di esecuzione
- Profiling della query specifica per identificare i colli di bottiglia
Questo approccio ci ha permesso di concentrare tutte le risorse sulla risoluzione del problema reale senza dispersioni.
La query problematica: anatomia di un disastro prestazionale
Ecco la query originale generata dal modulo blocklayered. Il modulo blocklayered di PrestaShop — oggi conosciuto nelle versioni più recenti come “Faceted Search” o “Ricerca a strati” — è uno dei moduli fondamentali per la navigazione filtrata dei prodotti all’interno di una categoria, una pagina di ricerca o una selezione di prodotti (es. produttore, attributo, tag, ecc.).
SELECT
p.*,
product_shop.*,
stock.out_of_stock,
IFNULL(stock.quantity, 0) AS quantity,
MAX(product_attribute_shop.id_product_attribute) AS id_product_attribute,
product_attribute_shop.minimal_quantity AS product_attribute_minimal_quantity,
pl.`description`,
pl.`description_short`,
pl.`available_now`,
pl.`available_later`,
pl.`link_rewrite`,
pl.`meta_description`,
pl.`meta_keywords`,
pl.`meta_title`,
pl.`name`,
MAX(image_shop.`id_image`) AS id_image,
isecond.`id_image` AS id_image_second,
il.`legend`,
m.`name` AS manufacturer_name,
cl.`name` AS category_default,
DATEDIFF(product_shop.`date_add`, DATE_SUB(NOW(), INTERVAL 20 DAY)) > 0 AS new,
product_shop.price AS orderprice,
cp.position
FROM
`ps_category_product` cp -- Tabella di join Categoria-Prodotto
LEFT JOIN
`ps_product` p ON p.`id_product` = cp.`id_product` -- Informazioni base del Prodotto
INNER JOIN
ps_product_shop product_shop
ON (
product_shop.id_product = p.id_product
AND product_shop.id_shop = 1
) -- Informazioni specifiche del Prodotto per lo Shop (necessario)
LEFT JOIN
`ps_product_attribute` pa ON (p.`id_product` = pa.`id_product`) -- Attributi del Prodotto (combinazioni)
LEFT JOIN
ps_product_attribute_shop product_attribute_shop
ON (
product_attribute_shop.id_product_attribute = pa.id_product_attribute
AND product_attribute_shop.id_shop = 1
AND product_attribute_shop.`default_on` = 1
) -- Attributi dello Shop (solo default)
LEFT JOIN
ps_stock_available stock
ON (
stock.id_product = p.id_product
AND stock.id_product_attribute = IFNULL(`product_attribute_shop`.id_product_attribute, 0)
AND stock.id_shop = 1
) -- Stock disponibile
LEFT JOIN
`ps_category_lang` cl
ON (
product_shop.`id_category_default` = cl.`id_category`
AND cl.`id_lang` = 6
AND cl.id_shop = 1
) -- Nome della Categoria di default (lingua 6)
LEFT JOIN
`ps_product_lang` pl
ON (
p.`id_product` = pl.`id_product`
AND pl.`id_lang` = 6
AND pl.id_shop = 1
) -- Dati descrittivi del Prodotto (lingua 6)
LEFT JOIN
`ps_image` i ON (i.`id_product` = p.`id_product`) -- Tutte le immagini
LEFT JOIN
ps_image_shop image_shop
ON (
image_shop.id_image = i.id_image
AND image_shop.id_shop = 1
AND image_shop.cover = 1
) -- Immagine di copertina per lo Shop
LEFT JOIN
`ps_image` isecond
ON (
isecond.`id_product` = p.`id_product`
AND isecond.position = 2
) -- Immagine in seconda posizione
LEFT JOIN
`ps_image_lang` il
ON (
image_shop.`id_image` = il.`id_image`
AND il.`id_lang` = 6
) -- Legenda dell'immagine di copertina (lingua 6)
LEFT JOIN
`ps_manufacturer` m ON m.`id_manufacturer` = p.`id_manufacturer` -- Nome del Produttore
WHERE
product_shop.`id_shop` = 1 -- Filtro per lo Shop
AND cp.`id_category` = 66 -- Filtro per la Categoria specifica
AND product_shop.`active` = 1 -- Solo prodotti attivi
AND product_shop.`visibility` IN ("both", "catalog") -- Solo prodotti visibili in catalogo o ovunque
GROUP BY
product_shop.id_product
ORDER BY
cp.`position` ASC
LIMIT 0, 50; -- Limite di risultati (offset 0, 50 righe)
Cosa rende questa query così lenta?
Analizzando l’`EXPLAIN` della query, emergevano diversi problemi critici:
1. GROUP BY su una tabella con molte righe : L’operazione di raggruppamento su `product_shop.id_product` richiede l’ordinamento di tutte le righe intermedie generate dalle JOIN, un’operazione O(n log n) su dataset potenzialmente grandi.
2. Funzioni aggregate MAX() su JOIN : I due `MAX()` — su `product_attribute_shop.id_product_attribute` e `image_shop.id_image` — costringono il database a:
- Eseguire tutte le JOIN
- Raggruppare per prodotto
- Calcolare il massimo per ogni gruppo
Questo pattern è particolarmente inefficiente quando un prodotto ha molte varianti o molte immagini.
3. Cascade di LEFT JOIN : La cascata di 11 LEFT JOIN crea un prodotto cartesiano molto ampio. Per un prodotto con:
- 10 varianti (product_attribute)
- 5 immagini
- Dati multilingua
Si generano potenzialmente 50+ righe intermedie che poi devono essere raggruppate.
4. Assenza di filtri nelle subquery : Non c’è pre-filtraggio. Il database deve processare TUTTE le varianti di TUTTI i prodotti prima di applicare i filtri.
5. Temporary table e filesort : L’`EXPLAIN` mostrava: Using temporary; Using filesort
Due segnali che il database deve creare tabelle temporanee e ordinarle su disco — operazioni molto costose.
Il costo nascosto del GROUP BY
Il GROUP BY in questa query è particolarmente insidioso perché:
- Non può utilizzare indici in modo efficiente (l’ordinamento è diverso dal raggruppamento)
- Richiede buffer di memoria significativi (o spill su disco)
- Deve processare tutte le righe prima di poter restituire anche solo il primo risultato
- Impedisce ottimizzazioni come “loose index scan”
Con un catalogo di 10.000 prodotti e 50.000 varianti, questa query potrebbe generare temporaneamente milioni di righe intermedie.
La soluzione: riscrivere la query eliminando gli antipattern
Dopo giorni di analisi, benchmark e iterazioni, siamo arrivati a questa query ottimizzata ma molto, molto molto, molto, molto, molto, molto lunga:
SELECT
p.*,
product_shop.*,
stock.out_of_stock,
IFNULL(stock.quantity, 0) AS quantity,
pa_default.id_product_attribute,
pa_default.minimal_quantity AS product_attribute_minimal_quantity,
pl.`description`,
pl.`description_short`,
pl.`available_now`,
pl.`available_later`,
pl.`link_rewrite`,
pl.`meta_description`,
pl.`meta_keywords`,
pl.`meta_title`,
pl.`name`,
img_cover.id_image AS id_image,
isecond.`id_image` AS id_image_second,
il.`legend`,
m.`name` AS manufacturer_name,
cl.`name` AS category_default,
DATEDIFF(product_shop.`date_add`, DATE_SUB(NOW(), INTERVAL 20 DAY)) > 0 AS new,
product_shop.price AS orderprice,
cp.position
FROM
`ps_category_product` cp -- Tabella di join Categoria-Prodotto
INNER JOIN
`ps_product_shop` product_shop
ON (
product_shop.id_product = cp.id_product
AND product_shop.id_shop = 1
) -- Informazioni specifiche del Prodotto per lo Shop
INNER JOIN
`ps_product` p
ON p.`id_product` = cp.`id_product` -- Informazioni base del Prodotto
LEFT JOIN
(
-- Subquery per l'attributo di prodotto predefinito (default)
SELECT
pa.id_product,
pa.id_product_attribute,
pas.minimal_quantity
FROM
ps_product_attribute pa
INNER JOIN
ps_product_attribute_shop pas
ON (
pas.id_product_attribute = pa.id_product_attribute
AND pas.id_shop = 1
AND pas.`default_on` = 1
)
) pa_default ON pa_default.id_product = p.id_product
LEFT JOIN
ps_stock_available stock
ON (
stock.id_product = p.id_product
AND stock.id_product_attribute = IFNULL(pa_default.id_product_attribute, 0)
AND stock.id_shop = 1
) -- Stock disponibile (collegato all'attributo di default)
LEFT JOIN
`ps_category_lang` cl
ON (
product_shop.`id_category_default` = cl.`id_category`
AND cl.`id_lang` = 6
AND cl.id_shop = 1
) -- Nome della Categoria di default (lingua 6)
LEFT JOIN
`ps_product_lang` pl
ON (
p.`id_product` = pl.`id_product`
AND pl.`id_lang` = 6
AND pl.id_shop = 1
) -- Dati descrittivi del Prodotto (lingua 6)
LEFT JOIN
(
-- Subquery per l'immagine di copertina (cover)
SELECT
i.id_product,
i.id_image
FROM
ps_image i
INNER JOIN
ps_image_shop image_shop
ON (
image_shop.id_image = i.id_image
AND image_shop.id_shop = 1
AND image_shop.cover = 1
)
WHERE
i.id_product IN (
SELECT
cp2.id_product
FROM
ps_category_product cp2
WHERE
cp2.id_category = 66
) -- Filtra le immagini solo per i prodotti della categoria 66
) img_cover ON img_cover.id_product = p.id_product
LEFT JOIN
`ps_image` isecond
ON (
isecond.`id_product` = p.`id_product`
AND isecond.position = 2
) -- Immagine in seconda posizione
LEFT JOIN
`ps_image_lang` il
ON (
img_cover.`id_image` = il.`id_image`
AND il.`id_lang` = 6
) -- Legenda dell'immagine di copertina (lingua 6)
LEFT JOIN
`ps_manufacturer` m
ON m.`id_manufacturer` = p.`id_manufacturer` -- Nome del Produttore
WHERE
cp.`id_category` = 66 -- Filtro per la Categoria specifica
AND product_shop.`active` = 1 -- Solo prodotti attivi
AND product_shop.`visibility` IN ("both", "catalog") -- Solo prodotti visibili in catalogo o ovunque
ORDER BY
cp.`position` ASC
LIMIT 50; -- Limite di risultati (inizia da 0 per default)
Anatomia delle ottimizzazioni
Analizziamo nel dettaglio cosa rende questa query così più efficiente:
1. Eliminazione completa del GROUP BY
Prima: GROUP BY product_shop.id_product
Dopo: Nessun GROUP BY
Questa è la modifica più impattante. Eliminando il GROUP BY, evitiamo:
- La creazione di tabelle temporanee
- L’ordinamento intermedio di potenzialmente milioni di righe
- Lo spill su disco quando i buffer di memoria sono insufficienti
2. Sostituzione di MAX() con subquery mirate
Per gli attributi prodotto:
— PRIMA: MAX(product_attribute_shop.id_product_attribute)
— Con JOIN che genera N righe per prodotto
— DOPO: Subquery che restituisce direttamente l’attributo default
LEFT JOIN
(
SELECT
pa.id_product,
pa.id_product_attribute,
pas.minimal_quantity
FROM
ps_product_attribute pa
INNER JOIN
ps_product_attribute_shop pas
ON (
pas.id_product_attribute = pa.id_product_attribute
AND pas.id_shop = 1
AND pas.`default_on` = 1
)
) pa_default
ON
pa_default.id_product = p.id_product
Vantaggi:
- La subquery è eseguita una sola volta e materializzata
- Restituisce esattamente una riga per prodotto (grazie al filtro
default_on = 1) - MySQL può utilizzare indici sulla colonna
default_on - Nessuna funzione aggregata da calcolare
Per le immagini di copertina:
— PRIMA: MAX(image_shop.id_image)
— Con LEFT JOIN su tutte le immagini
— DOPO: Subquery pre-filtrata
LEFT JOIN
(
SELECT
i.id_product,
i.id_image
FROM
ps_image i
INNER JOIN
ps_image_shop image_shop
ON (
image_shop.id_image = i.id_image
AND image_shop.id_shop = 1
AND image_shop.cover = 1 -- Solo cover
)
WHERE
i.id_product IN (
SELECT
cp2.id_product
FROM
ps_category_product cp2
WHERE
cp2.id_category = 66 -- Pre-filtro sulla categoria
)
) img_cover
ON
img_cover.id_product = p.id_product
Vantaggi:
- Filtro
cover = 1seleziona già solo l’immagine di copertina - Pre-filtro sui prodotti della categoria riduce drasticamente le righe processate
- La subquery viene eseguita prima e il suo risultato è riutilizzato
- Restituisce esattamente una riga per prodotto
3. Pre-filtraggio strategico
La subquery per le immagini include questo filtro preliminare:
WHERE
i.id_product IN (
SELECT
cp2.id_product
FROM
ps_category_product cp2
WHERE
cp2.id_category = 66
)
Con un catalogo di 10.000 prodotti di cui solo 150 nella categoria 66:
- Prima: Processava immagini di tutti i 10.000 prodotti (50.000+ immagini)
- Dopo: Processa solo immagini dei 150 prodotti rilevanti (750 immagini)
Riduzione del 98,5% delle righe processate in questa fase.
4. Ordine ottimizzato delle JOIN
Prima: Partiva da ps_category_product con una LEFT JOIN su ps_product
Dopo:
FROM `ps_category_product` cp INNER JOIN `ps_product_shop` product_shop ON ... INNER JOIN `ps_product` p ON ...
Utilizzando INNER JOIN per le tabelle fondamentali, forziamo il query optimizer a:
- Applicare prima i filtri sulla categoria
- Considerare solo prodotti attivi e visibili
- Ridurre drasticamente il dataset prima di eseguire le LEFT JOIN opzionali
5. Materializzazione delle subquery
MySQL/Percona può materializzare le subquery nella clausola FROM, creando temporanee molto piccole e indicizzate. Nel nostro caso:
Subquery pa_default : ~500 righe (una per prodotto con varianti)
Subquery img_cover : ~150 righe (solo prodotti della categoria con immagini)
Queste tabelle temporanee sono così piccole che restano in memoria (InnoDB buffer pool) e le JOIN successive diventano operazioni O(1) tramite hash join o index lookup.
Il paradosso delle subquery: più semplici, più veloci
Esiste un preconcetto diffuso secondo cui le subquery sarebbero sempre più lente delle JOIN dirette. Questo era parzialmente vero nei database engine più datati (MySQL 5.1 e precedenti), ma non è più valido nei motori moderni.
Perché le subquery ben scritte sono più veloci:
1. Scope ridotto: Processano solo i dati necessari
2. Materializzazione automatica: Il query optimizer crea temporanee ottimizzate
3. Riutilizzo: La subquery è eseguita una volta, il risultato riutilizzato
4. Migliore utilizzo degli indici: Query più semplici permettono strategie di indicizzazione più efficaci
5. Prevenzione prodotto cartesiano: Evitano l’esplosione combinatoria delle righe
Nel nostro caso specifico, abbiamo sostituito una query con:
0 subquery
11 LEFT JOIN
2 MAX()
1 GROUP BY
Con una query che ha:
3 subquery (di cui una annidata)
8 LEFT JOIN
2 INNER JOIN
0 MAX()
0 GROUP BY
Eppure quest’ultima è 600 volte più veloce.
I risultati: da 1.800 ms a 3 ms
I benchmark sono stati condotti in condizioni reali, su database di produzione (replicato in ambiente di staging), ottenendo un miglioramento da 1,8 secondi a 0,003 secondi (3 millisecondi) come dal video seguente in cui illustriamo tutto il processo di testing.
L’implementazione: dal database al codice PHP
Ottimizzare la query SQL era solo metà del lavoro. La vera sfida è stata integrare questa query nel modulo PrestaShop esistente, mantenendo la completa compatibilità con tutte le funzionalità del modulo blocklayered.
Il modulo blocklayered si trova in: /modules/blocklayered/blocklayered.php
La query originale era nel metodo getProductByFilters() della classe BlockLayered, circa alla riga 1996.
Adattamento del codice PHP
La modifica più delicata è stata gestire il fatto che la query ottimizzata restituisce le stesse colonne ma attraverso subquery con alias diversi. Abbiamo dovuto:
- Aggiornare la costruzione della query:
$id_shop = (int)Context::getContext()->shop->id; $this->products = Db::getInstance(_PS_USE_SQL_SLAVE_)->executeS(' SELECT p.*, ' . ($alias_where == 'p' ? '' : 'product_shop.*,') . ' pl.`description`, pl.`description_short`, // … altri campi espliciti invece di pl.* img_cover.id_image, // Invece di MAX(image_shop.id_image) pa_default.id_product_attribute, // Invece di MAX(…) // … resto della query '); - Verificare la compatibilità dei campi restituiti: Abbiamo dovuto testare che tutti i campi utilizzati successivamente nel codice fossero presenti con gli stessi nomi e tipi.
- Gestire i casi edge: Prodotti senza varianti, prodotti senza immagini, ecc. La query ottimizzata con LEFT JOIN ben posizionate gestisce già questi casi, ma abbiamo aggiunto test specifici.
- Mantenere la paginazione e l’ordinamento: La clausola
LIMITeORDER BYdovevano continuare a funzionare correttamente con i parametri dinamici di PrestaShop.
Riflessioni e considerazioni finali
L’eccellenza richiede tempo e metodo
Questo intervento rappresenta uno dei casi più interessanti di ottimizzazione “chirurgica” su un sistema in piena produzione. È stato un lavoro di precisione, svolto passo dopo passo, che ha richiesto tempo, competenze e una grande attenzione ai dettagli. L’intero processo – dall’analisi iniziale alla validazione finale – non è qualcosa che si possa improvvisare: anche per un team esperto, un’attività di questo tipo può richiedere almeno due giornate lavorative piene, spesso molto di più, considerando la necessità di diagnosticare, sperimentare e verificare ogni singolo cambiamento.
La parte più complessa non è stata tanto l’intervento tecnico in sé, quanto la fase di studio preliminare: capire dove si annidava il collo di bottiglia, isolare la query problematica e comprendere l’impatto reale di ogni possibile modifica. Da lì è iniziato un lungo lavoro di rifinitura, in cui la competenza in SQL, la conoscenza approfondita del funzionamento interno di MySQL/Percona e la familiarità con l’architettura di PrestaShop sono risultate essenziali.
Non si tratta solo di scrivere una query più efficiente: è necessario capire come questa interagisce con il codice PHP, con il modello dei dati e con le logiche di business dell’applicazione. Ogni modifica deve essere testata in modo rigoroso, sia per verificarne le prestazioni, sia per assicurarsi che non introduca regressioni o comportamenti inattesi. Anche una piccola svista può causare problemi in produzione, per cui il testing e la qualità del codice diventano fasi fondamentali, al pari della scrittura stessa della query.
Quando vale davvero la pena ?
Un intervento così profondo non è sempre giustificato. Diventa sensato solo quando esistono condizioni precise: un traffico consistente, un impatto economico concreto legato alle performance, e un bottleneck reale e misurabile che incide sull’esperienza utente o sulle conversioni. In pratica, ha senso agire in questo modo quando le ottimizzazioni più comuni sono già state applicate e si è raggiunto un punto in cui l’unico margine di miglioramento passa dal cuore del database e dal codice applicativo.
Nel caso di inventivashop.com queste condizioni erano tutte presenti. Il sito gestiva un volume di traffico notevole, con un alto valore per singola conversione. Il problema era stato identificato in modo preciso grazie al monitoraggio, e l’infrastruttura era già stata ottimizzata sotto ogni altro aspetto. In questo contesto, riscrivere la query più critica non era solo una scelta sensata, ma l’unica strada per ottenere un miglioramento tangibile e duraturo.
Le alternative e le lezioni apprese
Prima di arrivare alla riscrittura, sono state considerate diverse strade, ma tutte presentavano limiti evidenti. Soluzioni più superficiali avrebbero potuto mascherare il problema senza risolverlo davvero, mentre un intervento più profondo sul database prometteva risultati strutturali, capaci di migliorare le prestazioni a lungo termine.
La lezione più importante è che non si può ottimizzare alla cieca: ogni decisione deve basarsi su dati concreti, raccolti con strumenti di profilazione e analisi delle query lente. In molti casi, una sola query è responsabile della maggior parte del carico CPU o del rallentamento generale, e individuare quel punto critico fa la differenza tra un sistema efficiente e uno in costante affanno.
Abbiamo anche imparato che le subquery, spesso demonizzate, se scritte con criterio e filtrate correttamente, possono risultare più performanti di JOIN complesse. Gli indici, poi, restano uno degli elementi più determinanti: la query migliore del mondo diventa lenta se il database non è in grado di accedere ai dati nel modo giusto.
Infine, nessun risultato di questo tipo è sostenibile senza un’attenta attività di documentazione. Nel nostro caso, tutto il lavoro è stato tracciato e commentato in oltre venti pagine di documentazione tecnica, per garantire che ogni modifica fosse comprensibile e replicabile anche in futuro.
La sostenibilità nel tempo
Una volta raggiunto il risultato, il lavoro non si ferma. Un’ottimizzazione di questo livello deve essere monitorata costantemente per individuare tempestivamente eventuali regressioni o variazioni nelle performance. La query ottimizzata è stata versionata e documentata nel repository del progetto, e prima di ogni aggiornamento di PrestaShop o del database viene rieseguito un processo di verifica completo. Inoltre, il team di sviluppo interno è stato formato per comprendere a fondo il funzionamento della nuova implementazione, così da poterla mantenere e adattare nel tempo.
Conclusioni
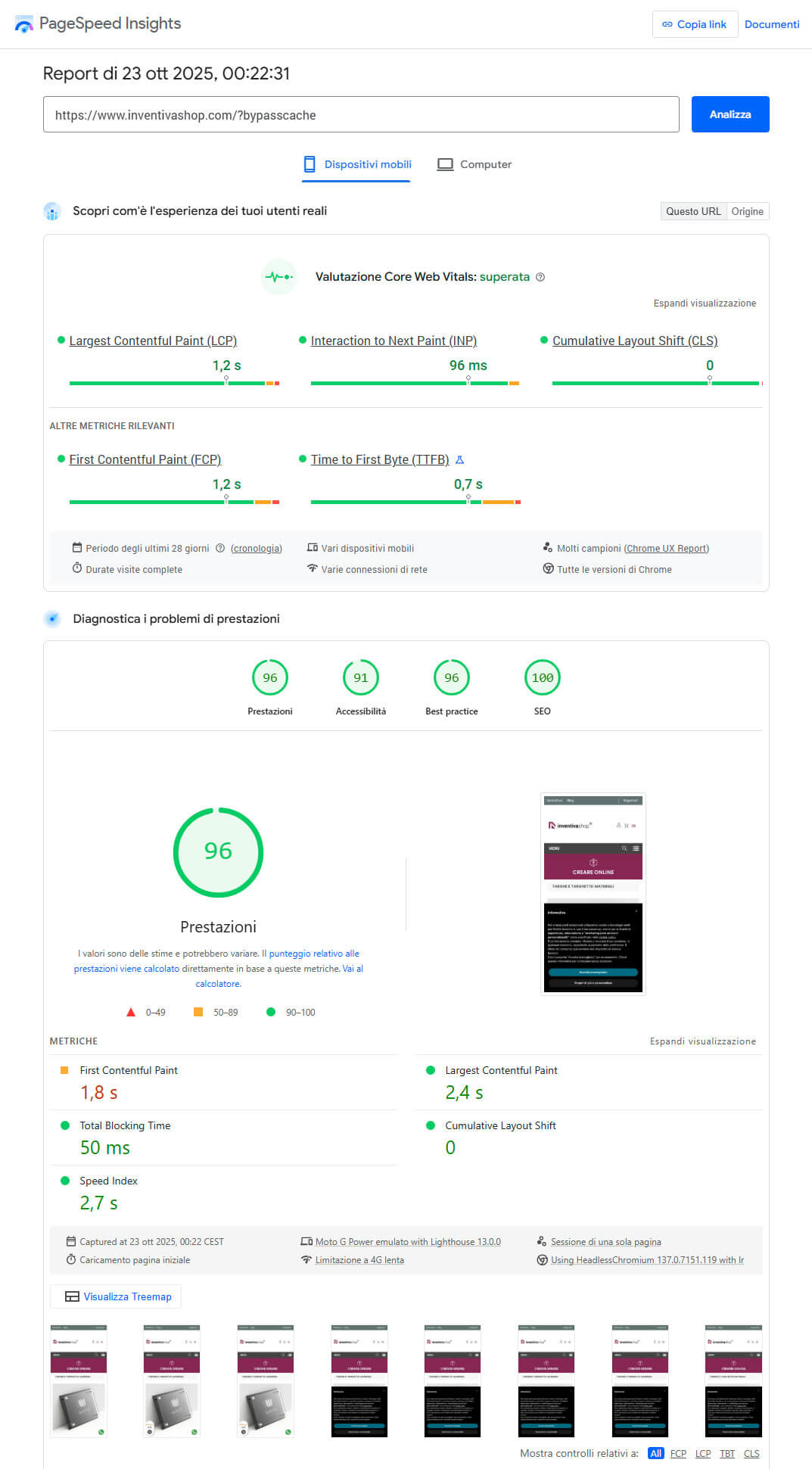
L’ottimizzazione di una singola query SQL su inventivashop.com ha prodotto un miglioramento straordinario, riducendo i tempi di esecuzione da 1.800 millisecondi a soli 3 millisecondi: un incremento di efficienza del 99,83%. Ma più dei numeri, ciò che conta è l’effetto sull’esperienza utente: caricamenti istantanei, Core Web Vitals pienamente nella zona “Good”, e un utilizzo delle risorse server notevolmente ridotto.
Questo tipo di risultato non arriva per caso. Richiede tempo, metodo e competenze molto specifiche, ma soprattutto una mentalità orientata ai dati e alla precisione. Non è un approccio da applicare a ogni progetto, né la prima opzione quando emergono problemi di performance. Tuttavia, quando tutte le altre ottimizzazioni hanno già dato il massimo e resta un singolo collo di bottiglia a rallentare tutto il sistema, un’analisi profonda delle query può fare la differenza tra un sito “sufficiente” e uno “eccezionale”.
Nel nostro caso, l’investimento di tempo e risorse è stato pienamente ripagato: inventivashop.com ha consolidato la sua posizione sui motori di ricerca per keyword competitive, ha migliorato l’esperienza d’uso per migliaia di clienti e ha visto un impatto diretto sulle conversioni. La vera chiave del successo è stata l’unione di un approccio data-driven, una forte competenza tecnica e la volontà di dedicare il tempo necessario per fare le cose nel modo giusto.
Nota: Questo caso studio rappresenta un intervento reale su un sistema in produzione. I risultati sono stati misurati e validati in ambiente reale, ma le performance possono variare in base a configurazione hardware, versione del software, dimensione del database e pattern di utilizzo specifici.