
Indice dei contenuti dell'articolo:
Capita molto frequentemente durante le nostre attività di supporto sistemistico spot presso aziende esterne (aziende che hanno già i loro sistemisti in azienda ma che magari cercano aiuto su qualcosa di specifico) di imbatterci in shell script (normalmente per la versione bash) che fanno uso di procedure e routine di backup e storage.
Oltre ai vari orrori visti come quelli che fanno backup con rsync o rsnapshot invece di utilizzare i moderni Borg Archiver, oppure chi ancora è rimasto nel 1996 che crede che per fare un backup di un DB MySQL da 40 GB sia adeguato usare mysqldump piuttosto che l’ottimo Percona XtraBackup di cui abbiamo parlato in questo articolo : Backup MySQL lento e server down quando passa Google, un errore STANDARD (questa parola la useremo spesso in questo articolo) che notiamo è quello del sistemista che pretende di fare storage di archivi usando il classico e ormai vetusto ed obsoleto tar.gz secondo il formato nomearchivio.tar.gz
Il problema della compressione dati
La compressione dei dati è un grosso problema. È uno dei problemi più antichi e più studiati nell’informatica. Facebook ha sviluppato il proprio algoritmo di compressione chiamato ZStandard o “zstd” che può essere più veloce e più efficiente di altri algoritmi di compressione come gzip, tar e bzip2.

Stanno tutti sbagliando.
E per tutti ad oggi intendiamo veramente tutti. Andate a leggervi gli script del vostro sistemista in azienda o interpellatelo sulla vicenda, e non potrete che darci ragione.
Il perchè è piuttosto facile da spiegare, essendo un insieme di fattori : il sistemista spesso non scrive i propri script (e nemmeno noi lo facciamo) ma si “limitano” a cercare qualcosa di pronto eventualmente da personalizzare, su qualche sito come StackOverflow ad esempio. Questi esempi sono spesso generati da altri sistemisti che a loro volta sono partiti da una base comune che molto spesso sono basi comuni antiquate (1990 – 2000 o giù di li), soprattutto per ciò che concerne sistemi Linux che a loro volta hanno ereditato anche script di gestione da “fratelli” più grandi come sistemi UNIX.
Diverso sarebbe per chi cerca dimostrazioni su React, node js o Angular js ad esempio che essendo – per ora – linguaggi nuovi, non potrebbero per ovvie ragioni logiche disporre di esempi e documentazione “obsoleta” nel senso più letterale del termine.
Un altro motivo pratico per cui si continua a che fare con il solito .tar.gz è che di fatto funziona, e non è poco avere qualcosa che funziona al giorno d’oggi.
Il sistemista come figura professionale può risultare annoiata e non motivata se non mosso da reale passione e/o da un lauto stipendio, motivo per cui la maggior parte si limitano a fare il proprio lavoro in un modo che sia funzionale agli obiettivi di business dell’azienda, ma non il più funzionale.
Oltretutto non capita spesso che un sistemista (a meno che non lavori per un datacenter con migliaia di macchine) abbia a che fare con la compressione dati e ne faccia un problema. Una normale PMI italiana spazia dai 3 ai 10 dipendenti, figuriamoci di quanto possa essere problematico quel DB di clienti e fornitori da 1 GB. Non se ne ha il bisogno di entrare in logiche operative di massimizzare i profitti minimizzando i costi insomma.
Sulle grandi realtà con centinaia o migliaia di dipendenti il tutto viene gestito in outsourcing o alla solita società di consulenza magari con 2 o 3 subappalti, o al grande gruppo multinazionale di consulenza che prende in mano la gestione senza spiegare ne troppo il perchè ne troppo il come. Fatto sta che in queste società di consulenza molto blasonate, raramente si vedono sistemisti senior sforare i 2 mila euro / mese di salario mensile e anche questo aspetto la dice lunga sulla motivazione che un essere umano può mettere in qualcosa che viene vissuto consapevolmente come uno sfruttamento.
Infine, diciamocela tutta, anche i più valorosi sistemisti che amano sperimentale e si avventurano come un Indiana Jones provetto alla ricerca del compressore dati perduto, dopo un paio di falsi positivi fermano tutto e ritornano al classico .tar.gz
Perchè anche quando si va a testare altre alternative, si arriva praticamente sempre a valutare e testare i soliti bzip, px, rar, zip e alla fine dei test si arriva sempre a far fronte di alcune conclusioni :
- Il software fa bene il suo lavoro comprimendo “abbastanza” ma con un tempo di compressione e/o CPU veramente molto elevati.
- Il software è abbastanza veloce ma non mi fa risparmiare dati rispetto al mio .tar.gz
Motivo per cui alla fine dei giochi si rimane con un .tar.gz e tutti gli script di sistema tarati su questa tecnologia.
ZStandard, compressione dati made in Facebook
E’ sempre un piacere poter abbracciare o semplicemente studiare tecnologie prodotte da grandi azione tecnologiche come Facebook, perchè denota sin da subito grandi idee seguite da un’esecuzione impeccabile. Con i migliori ingegneri sul mercato ed importanti investimenti economici in ricerca è sviluppo, è sempre una garanzia.
Zstandard, o zstd come versione abbreviata, è un algoritmo di compressione veloce senza perdita, che mira a scenari di compressione in tempo reale a livello zlib e rapporti di compressione molto migliori.
Offre una gamma molto ampia di compromessi tra compressione e velocità, mentre è supportato da un decoder molto veloce. Offre anche una modalità speciale per piccoli dati, chiamata compressione a dizionario, e può creare dizionari da qualsiasi set di campioni.
Facebook ha aperto Zstandard quasi sei anni fa con l’obiettivo di superare Zlib sia in termini di velocità che di efficienza. Zstandard 1.5 migliora la velocità di compressione a livelli di compressione intermedi, il rapporto di compressione a livelli più alti e porta una velocità di decompressione più rapida.
Zstandard supporta livelli di compressione fino a 22. Grazie a un nuovo match finder predefinito, Zstardard 1.5 raggiunge una velocità di compressione più elevata per livelli compresi tra 5 e 12 e input superiori a 256K. Secondo i benchmark di Facebook, i miglioramenti vanno da +25% a +140% senza perdite significative in termini di rapporto di compressione.
Facebook afferma risultati ancora migliori su macchine molto caricate in una significativa contesa di cache.
Oltre a migliorare le prestazioni di compressione, Zstandard 1.5 viene compilato per impostazione predefinita con supporto multithread, standardizza alcune nuove API e depreca un certo numero di quelle precedenti. Puoi trovare tutti i dettagli nelle note di rilascio ufficiali.
Zstandard infatti è stata creata da Yann Collet a Facebook ed è utilizzata nell’ambiente di produzione di Facebook dal 2015.
Oltre allo strumento a riga di comando, Zstandard è fornito come libreria per integrarlo facilmente nei tuoi progetti.
La libreria Zstandard è fornita come software open source utilizzando una licenza BSD.
Si rimanda al link ufficiale di Facebook che vi possa introdurre non solo il progetto ma l’enorme versatilità del progetto stesso che è stato adottato da un mare di altri progetti:.
5 ways Facebook improved compression at scale with Zstandard
Backup più veloci
Uno dei maggiori vantaggi di zstd è che può comprimere i dati in pacchetti più piccoli più velocemente di altri algoritmi, il che rende i backup più veloci. Molte aziende hanno terabyte di dati di cui fare il backup ogni giorno, quindi qualsiasi modo per accelerare i backup è una grande vittoria per loro.
Secondo i benchmark di Facebook, Zstandard supera zlib per qualsiasi combinazione di rapporto di compressione e larghezza di banda.
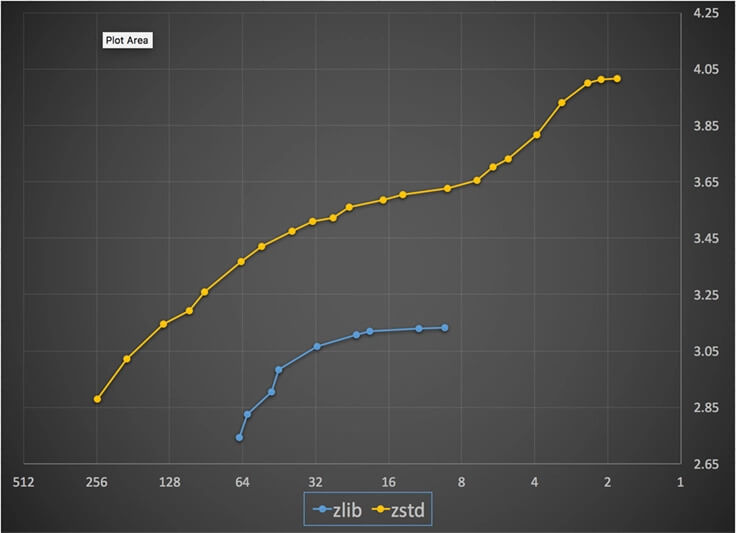
In particolare, Zstandard ha mostrato prestazioni eccezionali rispetto a zlib quando si utilizzava la compressione standard lossless :
- era circa 3–5 volte più veloce alla stessa velocità di compressione
- ha prodotto file più piccoli del 10–15% alla stessa velocità di compressione
- si è decompresso 2 volte più velocemente indipendentemente dal rapporto di compressione
- è scalato a un rapporto di compressione molto più alto (~4x contro ~3,15).
Zstandard utilizza l’entropia a stati finiti , basata sul lavoro di Jarek Duda sui sistemi numerici asimmetrici (ANS) per la codifica dell’entropia. ANS mira a “porre fine al compromesso tra velocità e velocità” e può essere utilizzato sia per una codifica precisa che per una codifica molto veloce, con supporto per la crittografia dei dati. Ma, alla base di Zstandard prestazioni migliori ci sono una serie di altre scelte di progettazione e implementazione:
- mentre zlib è limitato a una finestra di 32 KB, Zstandard sfrutta la disponibilità di memoria molto maggiore negli ambienti moderni, inclusi gli ambienti mobili e embedded, e non impone alcun limite intrinseco
- un nuovo decoder Huffman, Huff0 , viene utilizzato per decodificare simboli in parallelo grazie a più ALU riducendo le dipendenze dei dati tra le operazioni aritmetiche
- Zstandard cerca di essere il più possibile privo di diramazioni, riducendo così al minimo i costosi lavaggi delle tubazioni dovuti a previsioni di diramazione errate. Ad esempio, ecco come è
whilepossibile riscrivere un ciclo senza utilizzare rami:/* classic version */ while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8; } /* branch-less version */ nbBytesUsed = nbBitsUsed >> 3; nbBitsUsed &= 7; ptr += nbBytesUsed; accumulator = read64(ptr); - la modellazione repcode migliora notevolmente la compressione di sequenze che differiscono solo di pochi byte
Zstandard è sia uno strumento da riga di comando che una libreria, entrambi scritti in C. Fornisce più di 20 livelli di compressione che consentono di ottimizzare accuratamente il suo utilizzo per l’hardware disponibile concreto, i dati da comprimere e i colli di bottiglia da ottimizzare. Facebook consiglia di iniziare con il livello predefinito 3, che è adatto per la maggior parte dei casi, e quindi provare con livelli più alti fino al livello 9 per garantire un ragionevole compromesso tra velocità e spazio, o superiori per rapporti di compressione migliori, risparmiando livelli 20+ per quei casi in cui non ti interessa la velocità di compressione.
Collet e Turner hanno anche fornito alcuni suggerimenti su ciò che porteranno le future versioni di Zstandard, incluso il supporto per il multi-threading e nuovi livelli di compressione che consentono compressioni più veloci e rapporti più elevati.
Facciamo un test reale
Al di la di tutte le disquisizioni teoriche che possiamo produrre, quel che conta per un sistemista è poter disporre uno strumento ad uso d’uomo ed estremamente efficiente nel fare il proprio lavoro.
Parliamo di un sistema 6core / 12 thread con FS in RAID6 con dischi SATA e non nVME. L’utility zstd è stata installata su CentOS7 tramite il repository di REMI tramite : yum install zstd.
Abbiamo pertanto prodotto questa documentazione partendo da questo test che vede come bersaglio la directory /var/lib/mysql di un normalissimo DBMS MariaDB di un nostro reale cliente.
Questa directory ha una dimensione di 80GB e viene prima compressa tramite utility tar e gz e successivamente tramite la utility tar ztds.
In ogni fase di compressione andiamo a misurare tre parametri fondamentali :
- La sintassi impartita del comando
- La velocità di compressione
- La dimensione dell’archivio prodotta
Compressione tramite tar e gzip
time tar czvf prova.tar.gz /var/lib/mysql
real 19m19.862s
10.121.258.046 Mar 11 16:28 prova.tar.gz
Possiamo vedere come l’operazione di compressione abbia impiegato 19 minuti e 19 secondi e abbia prodotto un file da 10,12 Gigabyte
Compressione tramite tar e zstd
time tar –use-compress-program zstd -cf prova.tar.zst /var/lib/mysql
real 6m24.006s
5.727.249.564 Mar 11 16:47 prova.tar.zst
Possiamo vedere come l’operazione di compressione abbia impiegato 6 minuti e 24 secondi e abbia prodotto un file da 5,7 Gigabyte
Conclusioni del test
Seppur un solo test su una base di dati SQL e dunque prevalentemente testo ad alta ridondanza i risultati parlando chiaro, ZStandard ha prodotto in appena un terzo del tempo rispetto a tar e gzip un archivio che pesa la metà rispetto a quello prodotto con tar e gzip.
Capirete quanto possa essere importante per le nostre policy di backup e disaster recovery su oltre mille macchine con data retention di 60gg disporre di un sistema veloce ed efficiente come questo.