Indice dei contenuti dell'articolo:
Nel mondo della progettazione di sistemi distribuiti, della scalabilità dei database e delle architetture moderne orientate alle performance, esistono tre concetti che vengono citati molto spesso ma compresi raramente fino in fondo: Replication, Partitioning e Sharding.
La confusione nasce dal fatto che tutte e tre le tecniche parlano, in un modo o nell’altro, di gestione e distribuzione dei dati. Tuttavia, ciascuna di esse risolve problemi completamente diversi, opera a livelli differenti dell’architettura e introduce impatti molto specifici su prestazioni, affidabilità, costi operativi e complessità di gestione.
Comprendere realmente queste differenze non è solo un esercizio teorico. È una competenza fondamentale per chi gestisce CMS ad alto traffico, piattaforme e-commerce, applicazioni SaaS, infrastrutture hosting professionali o sistemi basati su microservizi.
In questo articolo analizziamo in modo chiaro e pragmatico cosa sono replication, partitioning e sharding, quali problemi risolvono, quando hanno senso e quando diventano un errore, come vengono usati nel mondo reale e perché spesso vengono combinati.
Replication: alta disponibilità e scalabilità in lettura
Cos’è la replication
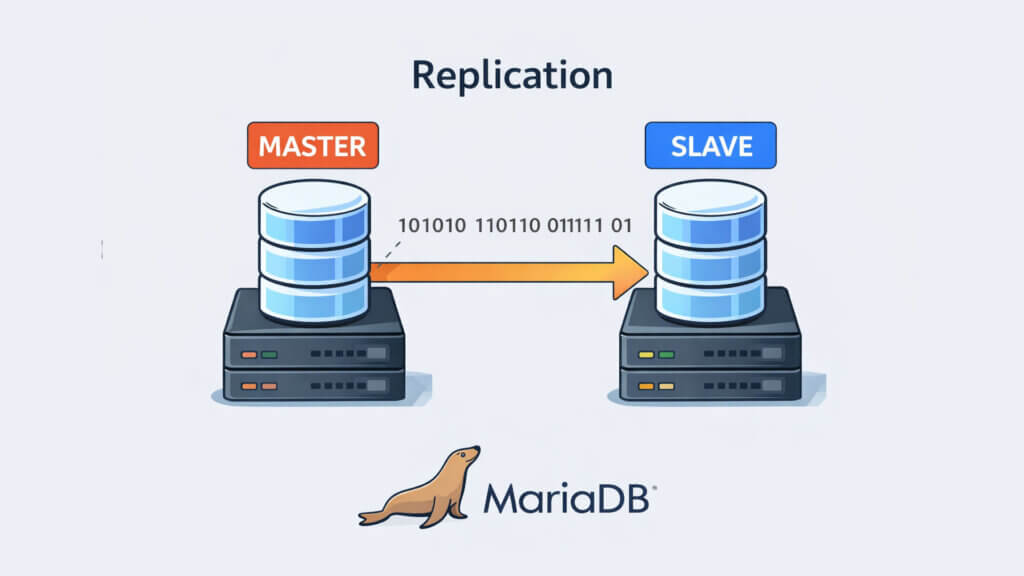
La replication è una tecnica di architettura dei database che consiste nel mantenere copie identiche dello stesso dataset su più server distinti, sincronizzati tra loro in modo automatico. Ogni nodo replica conserva l’intero database, o comunque l’intero set di dati rilevante per l’applicazione, aggiornato costantemente in base alle modifiche che avvengono sul nodo principale.
Dal punto di vista concettuale, la replication non frammenta i dati e non li suddivide: li duplica. Questo è un aspetto fondamentale da comprendere, perché definisce in modo netto sia i benefici sia i limiti di questa soluzione. Ogni server coinvolto nella replica possiede una copia completa del database, pronta a rispondere alle richieste.
Il modello più diffuso nei database relazionali è quello leader follower, noto anche come primary replica. In questa configurazione esiste un nodo leader che accetta tutte le operazioni di scrittura, come insert, update e delete, mentre uno o più nodi replica si occupano principalmente di gestire le query di lettura. Le modifiche effettuate sul leader vengono propagate ai replica in modo asincrono o semi sincrono, a seconda della configurazione.
Questo approccio consente di separare in modo netto il carico di scrittura da quello di lettura, migliorando la reattività complessiva del sistema e riducendo la pressione sul nodo principale. È una soluzione ampiamente adottata negli stack basati su MySQL, MariaDB e PostgreSQL, soprattutto in contesti hosting e web application tradizionali.
Esistono anche modelli più avanzati come il multi leader, in cui più nodi accettano scritture, oppure architetture leaderless tipiche di alcuni database distribuiti moderni. Tuttavia, questi approcci sono meno diffusi negli ambienti hosting classici perché introducono complessità aggiuntive legate alla risoluzione dei conflitti, alla consistenza dei dati e alla gestione delle transazioni.
Negli scenari più comuni, soprattutto nel mondo CMS e web application, il modello leader follower resta il compromesso migliore tra semplicità, affidabilità e prestazioni.
Qual è il vero obiettivo della replication
Uno degli errori concettuali più frequenti è pensare che la replication serva a “scalare il database” in senso generico. In realtà la replication non nasce per scalare il volume dei dati né per aumentare la capacità di scrittura del sistema.
Il suo obiettivo principale è un altro: garantire alta disponibilità, continuità del servizio e tolleranza ai guasti. In presenza di un problema hardware, software o di rete sul nodo principale, la presenza di uno o più replica consente di ridurre drasticamente il downtime e, in molti casi, di effettuare un failover rapido.
Un secondo obiettivo fondamentale è la scalabilità delle letture. In moltissime applicazioni web il numero di operazioni di lettura supera di gran lunga quello delle scritture. Pensiamo a un sito di contenuti, a un blog o a una piattaforma informativa: ogni visita genera decine di SELECT, ma pochissime operazioni di scrittura.
In questi contesti, la replication consente di distribuire il carico di lettura su più nodi, migliorando i tempi di risposta e la capacità complessiva del sistema senza dover intervenire sull’applicazione in modo invasivo.
La replication è quindi ideale per tutti quei contesti in cui il carico è prevalentemente read heavy, le scritture sono limitate o centralizzate e diventa fondamentale evitare interruzioni del servizio. È una soluzione che privilegia stabilità, affidabilità e resilienza, più che la crescita illimitata.
Vantaggi concreti della replication
Dal punto di vista operativo, la replication offre una serie di vantaggi molto concreti che la rendono una delle prime scelte quando un database standalone inizia a mostrare i suoi limiti.
Uno dei benefici più evidenti è la possibilità di effettuare failover rapido. In caso di guasto del nodo leader, un nodo replica può essere promosso a nuovo master, riducendo drasticamente i tempi di inattività. In ambienti ben progettati, questo processo può essere automatizzato o comunque gestito in modo rapido ed efficace.
Un altro vantaggio rilevante è la riduzione del carico sul nodo principale. Spostando le query di lettura sui replica, il leader può concentrarsi sulle operazioni di scrittura, migliorando la stabilità complessiva del sistema e riducendo la latenza nelle operazioni critiche.
La replication consente inoltre di eseguire backup, analisi e reportistica sui nodi replica, evitando di impattare le performance del database di produzione. Questo è particolarmente utile in contesti hosting e managed, dove la qualità del servizio dipende anche dalla capacità di svolgere attività di manutenzione senza causare rallentamenti percepibili dagli utenti.
Infine, la replication rappresenta spesso il primo step evolutivo naturale dopo un database standalone. Non richiede stravolgimenti applicativi, è supportata nativamente dai principali database relazionali ed è relativamente semplice da gestire da un punto di vista sistemistico.
I limiti strutturali della replication
Il limite più importante della replication è semplice, ma viene spesso sottovalutato o frainteso: ogni replica contiene l’intero dataset.
Questo significa che il volume complessivo dei dati non viene suddiviso tra più server, ma duplicato. Di conseguenza, se il database cresce in modo significativo, ogni nodo deve comunque disporre di risorse sufficienti per ospitare l’intero dataset, sia in termini di storage che di memoria e capacità computazionale.
Il secondo limite, ancora più critico, riguarda le scritture. In un modello leader follower tutte le operazioni di scrittura passano dal nodo leader. Questo nodo diventa inevitabilmente un collo di bottiglia quando il numero di insert, update e delete aumenta in modo consistente.
Aggiungere replica non risolve questo problema. Anzi, in alcuni casi può addirittura amplificarlo, perché il leader deve anche occuparsi di propagare le modifiche ai nodi secondari.
Il nodo leader rimane quindi il punto critico dell’intero sistema. Quando il carico di scrittura cresce oltre una certa soglia, la replication da sola non è più sufficiente e diventa necessario valutare approcci architetturali diversi, come il partitioning o lo sharding.
Un esempio pratico
Un sito WordPress ad alto traffico, con migliaia di visitatori simultanei e una prevalenza di contenuti statici o semi statici, beneficia enormemente di una replica MySQL utilizzata per le query di lettura. In questo scenario la maggior parte delle operazioni consiste in SELECT su post, pagine e metadati, mentre le scritture sono limitate alla pubblicazione dei contenuti e a poche operazioni amministrative.
Distribuire le letture su uno o più nodi replica consente di migliorare drasticamente i tempi di risposta e la stabilità del sistema, senza introdurre complessità applicative significative.
Un e-commerce, invece, presenta un pattern completamente diverso. Ogni visita può generare scritture legate a carrelli, sessioni, ordini, pagamenti e aggiornamenti di stock. In questi casi il nodo leader viene rapidamente saturato dalle operazioni di scrittura, e la replication mostra tutti i suoi limiti strutturali.
In uno scenario di questo tipo, la replication resta utile per l’alta disponibilità e per alcune letture, ma non è sufficiente da sola a sostenere la crescita del sistema. È proprio qui che diventa necessario valutare soluzioni architetturali più avanzate.
Partitioning: organizzare meglio i dati, non distribuire il carico
Cos’è il partitioning
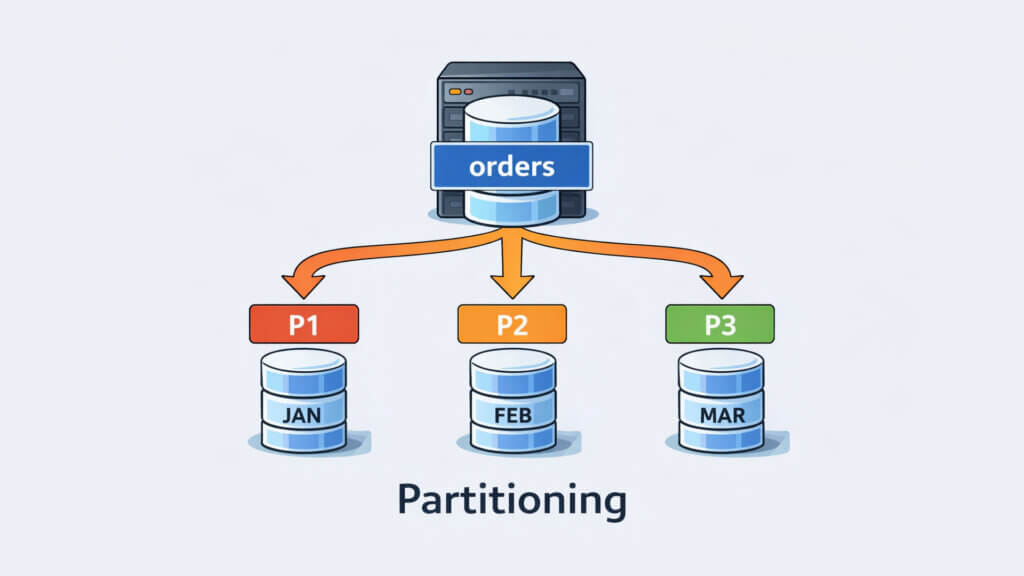
Il partitioning è una tecnica di organizzazione interna dei dati che consiste nel suddividere una grande tabella in più partizioni logiche, tutte mantenute all’interno dello stesso database server. A differenza di altre soluzioni orientate alla distribuzione del carico, il partitioning non sposta i dati su macchine diverse, ma li organizza in modo più efficiente sullo stesso sistema.
Ogni partizione contiene solo una porzione delle righe della tabella, definita in base a una regola ben precisa. Le strategie più comuni prevedono la suddivisione per range temporale, per lista di valori specifici o tramite una funzione di hash applicata a una o più colonne. La scelta del criterio di partizionamento è un aspetto cruciale, perché influisce direttamente sull’efficacia della soluzione.
Dal punto di vista dell’applicazione, e quindi del codice che interroga il database, la tabella resta una sola. Non è necessario modificare le query né introdurre logica applicativa aggiuntiva. È il database engine che, in modo completamente trasparente, decide quale partizione interrogare in base alle condizioni presenti nella query.
Questo aspetto rende il partitioning particolarmente interessante in contesti in cui non è possibile o non è desiderabile intervenire sull’applicazione, ma si vuole comunque migliorare l’efficienza del database.
A cosa serve realmente il partitioning
Il partitioning non nasce per scalare l’infrastruttura né per distribuire il carico su più server. Il suo scopo principale è migliorare le performance di tabelle molto grandi e rendere più gestibile la loro crescita nel tempo.
Quando una tabella raggiunge dimensioni elevate, anche operazioni apparentemente semplici possono diventare costose. Le scansioni complete richiedono più tempo, gli indici diventano più pesanti e le operazioni di manutenzione possono impattare in modo significativo sulle prestazioni complessive del database.
Il partitioning interviene proprio su questi aspetti. Riduce il costo delle scansioni, consente al database di lavorare su porzioni più piccole di dati, migliora l’efficacia degli indici e semplifica operazioni come la pulizia dei dati obsoleti o l’archiviazione di informazioni storiche.
Si tratta quindi di una tecnica di ottimizzazione interna, estremamente potente quando applicata nel modo corretto e nel contesto giusto. Non risolve problemi di carico strutturale, ma permette di sfruttare meglio le risorse disponibili.
I benefici principali del partitioning
Uno dei benefici più evidenti del partitioning è la riduzione del tempo di esecuzione delle query su dataset molto grandi. Quando una query include una condizione coerente con il criterio di partizionamento, il database può limitarsi a interrogare solo le partizioni rilevanti, evitando di analizzare l’intera tabella.
Questo meccanismo, noto come partition pruning, consente di ottenere miglioramenti significativi soprattutto su tabelle che crescono nel tempo, come quelle basate su date o identificativi progressivi.
Un altro vantaggio importante è la minore contesa interna. Operazioni che prima coinvolgevano l’intera tabella possono essere distribuite su più partizioni, riducendo il locking e migliorando la concorrenza tra le query.
Il partitioning semplifica inoltre la gestione dei dati storici. In molti casi, eliminare dati vecchi non richiede più delete massivi, ma semplicemente il drop di un’intera partizione, un’operazione molto più rapida e meno impattante.
Questa tecnica è particolarmente indicata per tabelle che crescono in modo continuo nel tempo, come ordini, log applicativi, eventi, transazioni e sistemi di tracciamento. In questi contesti, il partitioning consente di mantenere prestazioni stabili anche al crescere del volume dei dati.
Il limite fondamentale del partitioning
Il limite principale del partitioning è intrinseco alla sua natura: non aggiunge nuove risorse hardware.
Tutte le partizioni risiedono sullo stesso server e condividono le stesse risorse. La CPU, la memoria, lo storage e il sottosistema di I O restano invariati. Il partitioning migliora l’organizzazione dei dati, ma non aumenta la potenza del sistema.
Se il database è già vicino al limite delle proprie risorse, partizionare una o più tabelle non lo renderà improvvisamente scalabile. In alcuni casi può migliorare la situazione, ma non può risolvere problemi strutturali di saturazione.
È importante quindi non confondere il partitioning con una soluzione di scalabilità orizzontale. È uno strumento di ottimizzazione, non un modo per far crescere l’infrastruttura.
Un esempio concreto
Una tabella orders con centinaia di milioni di righe rappresenta un caso classico in cui il partitioning può fare una grande differenza. Partizionando la tabella per mese o per anno, il database può limitare le query alle sole partizioni rilevanti quando si interrogano dati recenti, come gli ordini degli ultimi trenta giorni.
Questo si traduce in query più rapide, minore carico sul sistema e una gestione molto più semplice dei dati storici. La rimozione di ordini vecchi può avvenire eliminando intere partizioni invece di eseguire operazioni di delete su milioni di righe.
Tuttavia è fondamentale ricordare che il database resta uno solo. Il carico complessivo non viene distribuito su più macchine e le risorse disponibili restano le stesse. Il partitioning migliora l’efficienza, ma non sostituisce soluzioni di scalabilità come lo sharding.
Sharding: la vera scalabilità orizzontale dei dati
Cos’è lo sharding
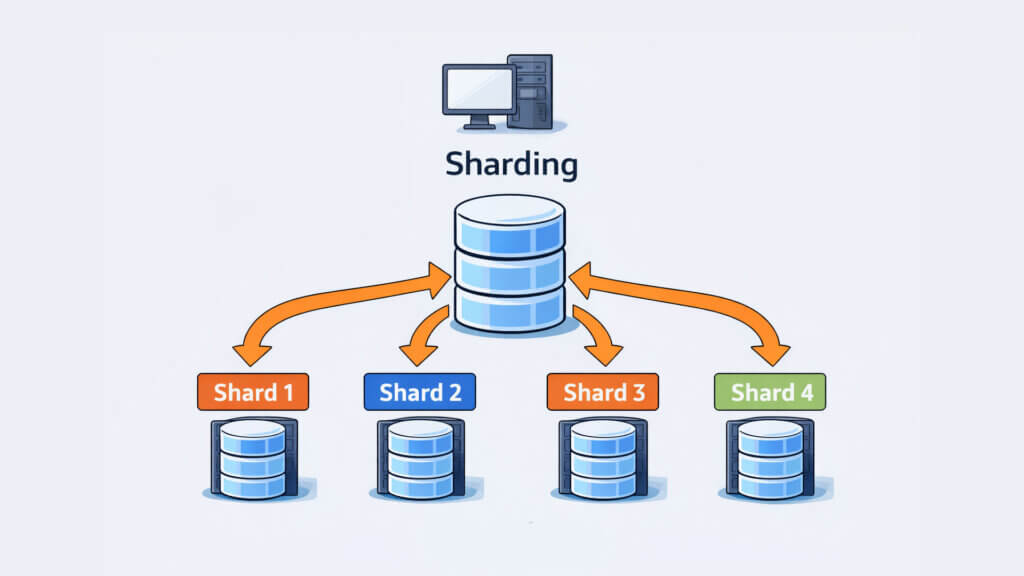
Lo sharding è una tecnica architetturale che consente di distribuire i dati su più macchine fisiche o virtuali, dividendo l’intero dataset in porzioni indipendenti chiamate shard. Ogni shard rappresenta una frazione autonoma del database complessivo ed è ospitato su un server distinto, con risorse dedicate.
A differenza di altre soluzioni che duplicano o organizzano i dati, lo sharding suddivide il dataset in modo orizzontale, assegnando a ciascun nodo solo una parte delle informazioni. Questo significa che nessun server possiede l’intero database, ma solo la porzione di cui è responsabile.
Ogni shard gestisce in modo autonomo il proprio carico di lavoro, sia in lettura che in scrittura. Le query vengono indirizzate direttamente allo shard corretto in base a una chiave di partizionamento, come un identificativo utente, un tenant ID o un intervallo di valori. Questo consente di distribuire in modo efficiente il traffico e di evitare colli di bottiglia centralizzati.
Lo sharding è l’unica delle tre soluzioni analizzate che consente una scalabilità orizzontale reale, perché permette di aumentare la capacità del sistema semplicemente aggiungendo nuovi nodi e distribuendo su di essi parte dei dati e del carico.
Perché lo sharding è concettualmente diverso
Lo sharding è concettualmente diverso sia dalla replication che dal partitioning perché interviene a un livello più profondo dell’architettura.
A differenza della replication, i dati non vengono duplicati, ma suddivisi. Ogni informazione risiede su uno shard specifico e non è presente sugli altri nodi, salvo eventuali meccanismi di replica interna allo shard per motivi di alta disponibilità.
A differenza del partitioning, la separazione dei dati è fisica e non solo logica. Le partizioni non convivono sullo stesso server, ma sono distribuite su macchine diverse, ciascuna con le proprie risorse di CPU, memoria, storage e I O.
Questo approccio consente di distribuire in modo lineare non solo il volume dei dati, ma anche il carico computazionale e il traffico di scrittura. All’aumentare degli utenti o delle transazioni, è possibile aggiungere nuovi shard e mantenere prestazioni stabili nel tempo.
Dal punto di vista architetturale, lo sharding rappresenta un vero cambio di paradigma rispetto ai modelli tradizionali basati su un singolo database centrale.
Vantaggi dello sharding
Il vantaggio principale dello sharding è la scalabilità quasi illimitata. In teoria, non esiste un limite massimo al volume di dati o al numero di operazioni che il sistema può gestire, purché sia possibile aggiungere nuovi shard e distribuire correttamente il carico.
Un altro beneficio fondamentale è la riduzione drastica della contesa. Poiché ogni shard gestisce solo una porzione dei dati, il numero di operazioni concorrenti su ciascun nodo diminuisce, migliorando le prestazioni complessive e la prevedibilità del sistema.
Lo sharding consente inoltre una migliore gestione dei carichi elevati, tipici delle piattaforme ad alto traffico, degli e-commerce di grandi dimensioni e dei servizi SaaS con molti clienti attivi. Ogni shard può essere dimensionato in base alle esigenze specifiche, rendendo l’infrastruttura più flessibile.
Un ulteriore vantaggio è la possibilità di far crescere il sistema nel tempo senza migrazioni traumatiche. In un’architettura shardata, l’aggiunta di nuovi nodi può avvenire in modo progressivo, senza dover spostare l’intero database o affrontare downtime prolungati.
Per sistemi di grandi dimensioni, lo sharding non è una scelta opzionale ma una vera e propria necessità architetturale.
Il costo architetturale dello sharding
Nonostante i suoi vantaggi, lo sharding introduce una complessità significativa che non può essere ignorata. È una soluzione potente, ma costosa dal punto di vista progettuale e operativo.
Uno degli aspetti più critici è la necessità di una logica di routing shard aware. L’applicazione deve sapere su quale shard risiedono i dati richiesti e indirizzare correttamente le query. Questo implica modifiche al codice e una progettazione attenta della chiave di sharding.
Lo sharding rende inoltre complessi i join tra shard. Operazioni che in un database monolitico erano semplici diventano difficili o addirittura impraticabili quando i dati risiedono su nodi diversi. Anche le query trasversali, che coinvolgono più shard, risultano più lente e costose.
Aumenta anche la complessità delle procedure di backup e restore, che devono tenere conto di più database indipendenti. La gestione operativa richiede strumenti, competenze e processi più avanzati rispetto a un’architettura tradizionale.
Per questi motivi, lo sharding impone un design applicativo consapevole fin dalle prime fasi del progetto. Introdurlo a posteriori può essere estremamente complesso e rischioso.
Un esempio reale
Un esempio tipico di utilizzo dello sharding è quello di una piattaforma SaaS multi tenant. In questo scenario, ogni cliente o gruppo di clienti viene assegnato a uno shard specifico, isolando i dati e distribuendo il carico in modo uniforme.
I dati non si mescolano, le performance restano prevedibili e la crescita della piattaforma diventa lineare. All’aumentare del numero di clienti, è sufficiente aggiungere nuovi shard e assegnare loro i nuovi tenant.
Questo modello è ampiamente utilizzato nei grandi servizi cloud, nelle piattaforme enterprise e nei sistemi che devono gestire milioni di utenti o volumi di dati molto elevati, dove le soluzioni tradizionali non sono più sufficienti.
Confronto diretto tra Replication, Partitioning e Sharding
Dal punto di vista pratico, le differenze tra replication, partitioning e sharding possono essere sintetizzate in modo chiaro solo se si comprende che non risolvono lo stesso problema.
La replication è una soluzione orientata alla disponibilità del servizio e alla scalabilità delle letture. È pensata per rendere il database più resiliente ai guasti e per distribuire le query di lettura su più nodi, senza modificare il modello dei dati né l’architettura applicativa.
Il partitioning, invece, è una tecnica di ottimizzazione interna che migliora l’efficienza nella gestione di tabelle molto grandi. Non aggiunge capacità al sistema, ma consente di sfruttare meglio le risorse esistenti, rendendo più veloci le query e più semplici le operazioni di manutenzione.
Lo sharding rappresenta infine un cambio di paradigma. È l’unica delle tre soluzioni che abilita una scalabilità orizzontale reale, permettendo di distribuire dati e carico su più macchine e di far crescere il sistema nel tempo senza incontrare limiti strutturali.
Confondere questi concetti porta spesso a decisioni architetturali sbagliate. Applicare la soluzione corretta al problema sbagliato non solo non risolve le criticità, ma può introdurre complessità, costi e rigidità difficili da correggere in una fase successiva.
Errori architetturali più comuni
Uno degli errori più frequenti è utilizzare la replication pensando di risolvere problemi di scrittura. Aggiungere replica può migliorare le letture e la disponibilità, ma non elimina il collo di bottiglia del nodo principale. Quando il carico di scrittura cresce, il leader resta il punto critico del sistema, indipendentemente dal numero di replica presenti.
Un altro errore comune è introdurre il partitioning senza analizzare il reale pattern delle query. Un partitioning progettato male, con criteri non coerenti con le condizioni più utilizzate nelle query, può addirittura peggiorare le performance invece di migliorarle. In questi casi il database non riesce a sfruttare il partition pruning e finisce per comportarsi come una tabella non partizionata, con un overhead aggiuntivo.
Infine capita spesso di introdurre lo sharding troppo presto. Spinti dalla paura di future limitazioni, alcuni progetti adottano lo sharding quando il carico reale non lo giustifica ancora. Questo approccio aumenta inutilmente la complessità applicativa, rende più difficile la manutenzione e introduce costi operativi senza benefici concreti nel breve e medio periodo.
Una buona architettura nasce dall’analisi dei dati reali, non da previsioni astratte.
Quando e come combinare le tre tecniche
Nelle architetture moderne più solide, replication, partitioning e sharding non si escludono a vicenda, ma convivono in modo complementare.
Un approccio molto diffuso prevede lo sharding per distribuire il carico complessivo e il volume dei dati su più nodi, la replication all’interno di ogni shard per garantire alta disponibilità e tolleranza ai guasti, e il partitioning per gestire in modo efficiente le tabelle più grandi all’interno di ciascun database shardato.
In questo modello ogni shard rappresenta un’unità relativamente autonoma, resiliente e ottimizzata internamente. La crescita del sistema avviene in modo progressivo e controllato, aggiungendo nuovi shard quando necessario e mantenendo prestazioni prevedibili nel tempo.
Questo tipo di architettura è tipico dei grandi e-commerce, delle piattaforme ad alto traffico, dei servizi SaaS enterprise e delle infrastrutture hosting avanzate, dove la scalabilità deve essere pianificata ma anche gestita con attenzione.
Implicazioni nel mondo hosting e CMS
Nel mondo dei CMS come WordPress, WooCommerce, Magento e PrestaShop, la replication rappresenta spesso la soluzione più immediata ed efficace per migliorare affidabilità e prestazioni. È relativamente semplice da implementare, non richiede modifiche applicative invasive e risolve gran parte dei problemi tipici legati all’aumento del traffico.
Il partitioning è meno diffuso in questi contesti, ma può offrire vantaggi importanti su database cresciuti nel tempo, soprattutto per tabelle come ordini, log, statistiche e dati storici. Quando applicato correttamente, consente di recuperare performance senza dover intervenire sull’infrastruttura.
Lo sharding, invece, richiede modifiche applicative e una progettazione più profonda. Non è una soluzione plug and play e va valutata con attenzione, soprattutto nei CMS tradizionali che non nascono nativamente per un’architettura distribuita.
Per questo motivo, in ambito hosting managed, la differenza reale non la fa la tecnologia in sé, ma l’esperienza sistemistica con cui viene applicata. Saper scegliere quando fermarsi, quando ottimizzare e quando ripensare l’architettura è ciò che distingue un’infrastruttura che regge la crescita da una che collassa sotto il proprio successo.
Conclusioni
Replication, Partitioning e Sharding non sono alternative tra loro, ma strumenti complementari che rispondono a esigenze diverse e a fasi differenti della vita di un progetto. Trattarli come soluzioni intercambiabili è uno degli errori più comuni nella progettazione delle architetture database moderne.
La replication è la risposta quando il problema principale è la disponibilità del servizio e la necessità di garantire continuità operativa anche in presenza di guasti. È una soluzione efficace per migliorare la resilienza dell’infrastruttura e per distribuire il carico di lettura, senza stravolgere l’architettura applicativa esistente.
Il partitioning diventa invece fondamentale quando il database cresce nel tempo e alcune tabelle iniziano a raggiungere dimensioni tali da compromettere le performance. In questi casi non serve aggiungere server, ma organizzare meglio i dati, riducendo il costo delle query e semplificando la gestione dei dati storici.
Lo sharding rappresenta infine il passo più impegnativo, ma anche quello più potente. Quando il problema è la crescita strutturale del sistema, quando il volume dei dati e il carico di scrittura superano i limiti di un singolo nodo, lo sharding diventa inevitabile. È una scelta architetturale che richiede consapevolezza, pianificazione e competenze avanzate, ma che consente di costruire sistemi realmente scalabili nel lungo periodo.
Saper riconoscere quando fermarsi e quando evolvere l’architettura è ciò che distingue un sistema che regge il successo da uno che collassa sotto il proprio traffico. Non esiste una soluzione valida per tutti, ma esiste sempre una scelta corretta in base al contesto, ai dati reali e agli obiettivi del progetto.
Ed è proprio in questa fase che una progettazione sistemistica consapevole fa la differenza, trasformando la crescita da un problema da gestire in un’opportunità da sostenere nel tempo.