
Indice dei contenuti dell'articolo:
Negli ultimi dodici mesi abbiamo assistito, come azienda di Hosting e sistemistica Linux specializzata nelle Web Performance dei principali CMS, a un fenomeno sempre più evidente: il traffico automatizzato verso i siti web è aumentato in modo importante, spesso improvviso, e in alcuni casi con effetti molto pesanti sulle infrastrutture dei clienti.
Non si tratta più soltanto dei classici bot dei motori di ricerca, né dei crawler SEO, né degli scanner automatizzati che da anni scandagliano Internet alla ricerca di vulnerabilità note. Oggi il panorama è molto più complesso. Alla tradizionale attività di crawling si è aggiunta una nuova ondata di bot e scraper su scala globale, motivata in larga parte dalla raccolta massiva di dati per addestrare, aggiornare o arricchire nuovi Large Language Model.
L’esplosione dell’intelligenza artificiale generativa ha reso i contenuti pubblici del Web una risorsa preziosissima. Blog, forum, documentazione tecnica, e-commerce, descrizioni prodotto, schede informative, knowledge base, recensioni, portali editoriali e siti aziendali sono diventati obiettivi interessanti per chiunque voglia raccogliere grandi quantità di testo, dati strutturati o informazioni settoriali.
In alcuni casi questo crawling viene svolto in modo trasparente. Alcuni operatori noti, come OpenAI o Anthropic, utilizzano user-agent dichiarati e documentati. Un crawler può presentarsi, ad esempio, con uno user-agent come GPTBot, OAI-SearchBot, ClaudeBot, Claude-SearchBot o simili, permettendo al gestore del sito di riconoscerlo e di applicare regole tramite robots.txt.

Questo è l’approccio corretto: il bot si annuncia, dichiara la propria identità e consente al webmaster di decidere se permettere o negare l’accesso a determinate sezioni del sito. Le direttive Allow, Disallow o eventuali indicazioni di rate limiting, ove supportate o rispettate, permettono almeno di instaurare un rapporto chiaro tra chi pubblica contenuti e chi li acquisisce.
Purtroppo non tutti si comportano così.
Sempre più spesso osserviamo crawler che non dichiarano affatto la propria natura automatizzata. Al contrario, si camuffano tra gli utenti reali utilizzando user-agent apparentemente legittimi, copiati dai browser più comuni: Chrome, Safari, Firefox, Microsoft Edge, Opera, DuckDuckGo Browser, browser mobile, WebView Android, WebView iOS e così via.
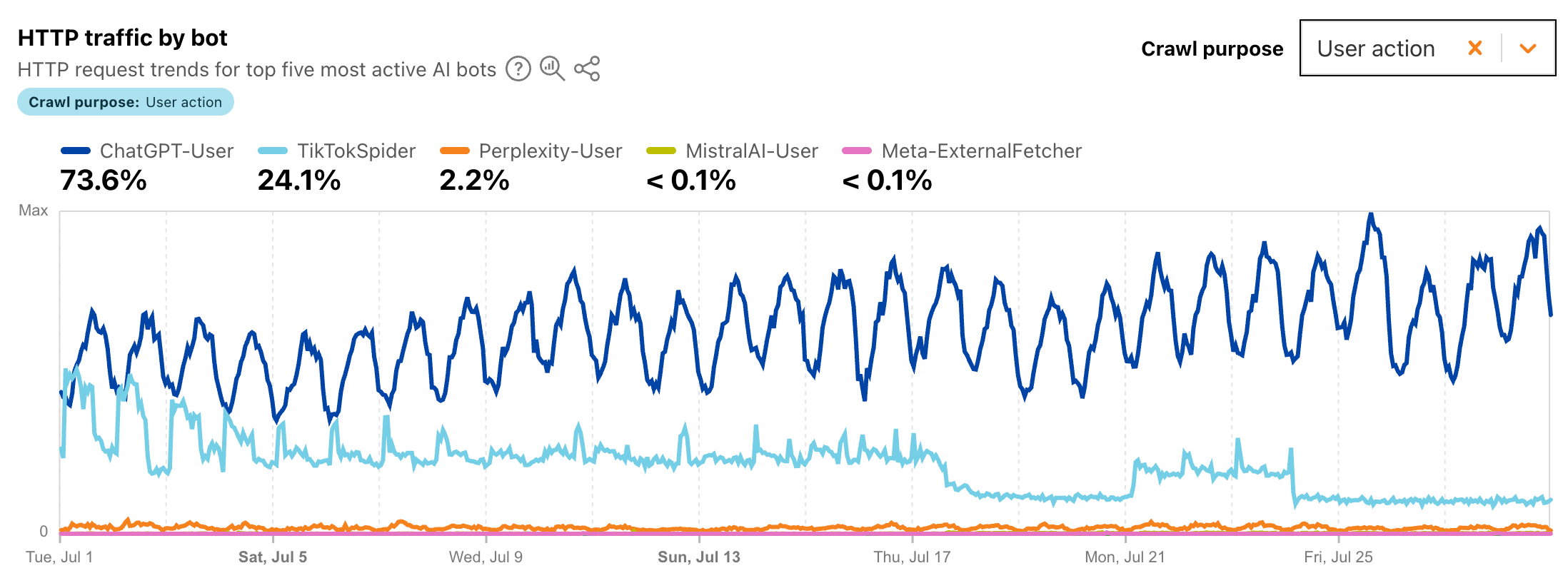
In molti casi questi bot arrivano da infrastrutture cloud, provider esteri, reti proxy, IP residenziali o classi di rete difficili da attribuire con certezza. Talvolta il traffico proviene da paesi asiatici, talvolta da datacenter europei o americani, talvolta ancora da reti apparentemente domestiche. L’obiettivo è sempre lo stesso: confondersi con il traffico legittimo e rendere difficile il blocco tramite regole semplici.
Il problema di fondo è che lo user-agent, da solo, non ha più alcun valore affidabile. È una stringa liberamente impostabile dal client. Un bot scritto in Python, Go, Rust, Node.js o qualunque altro linguaggio può tranquillamente dichiararsi come un normale Chrome su Windows o un Safari su macOS. Ma questo non significa che dietro quella richiesta ci sia davvero un utente seduto davanti a un monitor, con un browser reale, una GPU reale, un viewport reale, un ambiente grafico reale e un comportamento umano reale.
Quando il crawling diventa un problema di performance
In un sito ben configurato, come un blog con cache di pagina efficiente, il crawling anche massivo può risultare relativamente trascurabile dal punto di vista del carico. Se le richieste vengono servite da Varnish, da Nginx FastCGI Cache, da una cache applicativa o da una CDN, l’impatto su PHP, CPU, RAM e database può essere contenuto.
Un bot che scarica pagine già cachate genera traffico, consuma banda, riempie log e può alterare statistiche e metriche, ma difficilmente porta al collasso il backend applicativo. In questi casi il problema esiste, ma è spesso gestibile o perfettamente ignorabile perchè non provoca alcun problema.
La situazione cambia radicalmente quando il sito non è adeguatamente cacheabile oppure quando ci troviamo davanti a un e-commerce complesso. WooCommerce, Magento, PrestaShop e piattaforme simili sono molto più delicate rispetto a un blog statico o semi-statico. Un catalogo prodotti può generare migliaia, decine di migliaia o addirittura milioni di URL differenti, soprattutto quando entra in gioco la navigazione faccettata.
La navigazione faccettata permette all’utente di filtrare i prodotti per colore, taglia, prezzo, brand, disponibilità, materiale, categoria, attributo, ordinamento, paginazione e altri criteri. Dal punto di vista dell’esperienza utente è una funzione spesso essenziale. Dal punto di vista della sicurezza e delle performance, però, può diventare una superficie di attacco enorme.
Un crawler non autorizzato può iniziare a seguire combinazioni infinite di filtri e parametri. Può richiedere URL sempre diversi, spesso non presenti in cache, costringendo il backend a generare dinamicamente ogni singola pagina. Il risultato è prevedibile: PHP-FPM inizia a saturare, MySQL o MariaDB ricevono query sempre più pesanti, la CPU sale, la RAM si consuma, il load average aumenta e il tempo di risposta del sito peggiora drasticamente.
In questi scenari il passaggio di un bot non è più una semplice attività di crawling, diventa flooding applicativo. Non sempre siamo davanti a un DDoS volumetrico nel senso tradizionale del termine, ma l’effetto finale è molto simile: il sito rallenta, il checkout diventa instabile, gli utenti reali non riescono a navigare, le conversioni crollano e il cliente percepisce il servizio come indisponibile.
Il paradosso è che spesso il traffico malevolo o indesiderato non appare immediatamente tale. Nei log può sembrare traffico browser. Lo user-agent dichiara Chrome. L’IP non è necessariamente in blacklist. Le richieste sono formalmente HTTP valide. Non ci sono payload evidentemente malevoli. Non c’è un exploit riconoscibile. C’è semplicemente un numero anomalo di richieste, distribuite su molte URL e capaci di generare carico reale.
L’approccio tradizionale: più hardware, più ottimizzazione, più blocchi
Quando un sito inizia a soffrire a causa di questi fenomeni, la prima reazione è spesso quella di aumentare le risorse hardware. Si passa a più CPU, più RAM, dischi più veloci, database separato, server più grande, istanze cloud più costose o architetture più complesse.
In alcuni casi questo è necessario. Se un sito è cresciuto davvero, se il traffico legittimo è aumentato, se il volume di vendite giustifica un’infrastruttura più robusta, scalare è corretto. Ma quando la causa principale del carico è traffico automatizzato indesiderato, aumentare le risorse rischia di diventare solo un modo più costoso per alimentare il problema.
Dopo l’aumento hardware arriva solitamente la fase di ottimizzazione. Si analizzano le query lente, si migliorano gli indici database, si riducono le chiamate inutili, si interviene su plugin pesanti, moduli inefficienti, template lenti, configurazioni errate, cache mancante o mal implementata. Anche questo è corretto e fa parte del nostro lavoro quotidiano.
Tuttavia, ottimizzare un’applicazione per servire meglio utenti reali è una cosa. Ottimizzarla per reggere centinaia di richieste al secondo generate da bot indesiderati è un’altra. In quest’ultimo caso il problema non è solo prestazionale, ma di controllo del traffico.
A quel punto si passa spesso a sistemi di firewalling, blocco IP, rate limiting e geoblocking. Si bloccano intere classi di rete, ASN sospetti, paesi da cui non dovrebbero arrivare clienti o aree geografiche considerate non rilevanti per il business. Questo approccio può funzionare quando il sito vende solo in determinati mercati e il traffico malevolo arriva chiaramente da paesi non serviti.
Ma non sempre è così.
Se un e-commerce vende in Italia e il traffico malevolo arriva dall’estero, il geoblocking può essere una soluzione accettabile. Ma se il traffico legittimo e quello malevolo arrivano dallo stesso paese, bloccare l’intera nazione diventa impossibile. Se i bot utilizzano IP residenziali, proxy distribuiti o infrastrutture collocate negli stessi mercati dei clienti reali, il blocco geografico diventa uno strumento troppo grossolano.
In questi casi serve un filtro più chirurgico. Non basta chiedersi da dove arriva la richiesta. Bisogna iniziare a chiedersi che cosa è davvero il client che la sta generando.
Bot AI e scanner hacker: finalità diverse, metodo simile
Lo stesso problema, in forme diverse, esiste da anni nel campo della sicurezza applicativa. Ogni volta che viene pubblicata una vulnerabilità critica in un plugin WordPress, in un modulo WooCommerce, in un’estensione PrestaShop, in un componente Magento o in un CMS diffuso, iniziano scansioni automatizzate su larga scala.
Gli attaccanti sanno che molti siti non vengono aggiornati tempestivamente. Sanno che tra la pubblicazione di una falla e l’applicazione della patch può passare tempo. Sanno che esistono migliaia di installazioni esposte, spesso gestite male, con plugin abbandonati, temi obsoleti o moduli non mantenuti. Per questo sviluppano scanner automatici capaci di cercare versioni vulnerabili e, quando possibile, sfruttare immediatamente la falla.
La finalità di questi scanner è ovviamente diversa rispetto a quella dei crawler AI. Nel primo caso si parla di raccolta dati, scraping o acquisizione massiva di contenuti. Nel secondo caso si parla di compromissione, exploit, caricamento di webshell, furto di dati, spam, defacement o accesso non autorizzato. La gravità è diversa.

Ma dal punto di vista tecnico esiste un elemento comune fondamentale: nella maggior parte dei casi questi sistemi non usano browser reali.
Utilizzano client HTTP automatizzati. Possono essere script basati su curl, moduli Python come requests o aiohttp, agenti scritti in Go, Rust, Node.js o Java. Possono rinominare lo user-agent, falsificare header, simulare cookie, seguire redirect e persino gestire in modo rudimentale alcune risposte. Ma nella maggior parte dei casi non sono veri browser.
Non hanno un motore grafico completo. Non hanno una GPU reale. Non hanno plugin. Non hanno una cronologia. Non hanno un utente che muove il mouse, clicca, scorre, cambia tab, interagisce con la pagina. Spesso non hanno nemmeno un interprete JavaScript. Si limitano a inviare richieste GET e POST in modo cadenzato, sistematico e massivo.
Anche quando ci troviamo davanti a soluzioni più evolute, basate su browser headless come Chromium controllato da Puppeteer, Playwright o Selenium, resta comunque una differenza importante rispetto a un browser reale usato da una persona. Un browser headless può eseguire JavaScript, ma spesso presenta segnali distintivi. Può avere proprietà anomale, fingerprint uniformi, viewport artificiali, GPU software, assenza di plugin, comportamenti prevedibili o incoerenze tra ambiente dichiarato e ambiente reale.
Ed è proprio qui che entra in gioco il browser fingerprinting.
Che cos’è il browser fingerprinting
Il browser fingerprinting è un insieme di tecniche che consentono di raccogliere segnali dal browser e dall’ambiente di esecuzione per costruire un profilo tecnico del client. Questo profilo può essere usato per molti scopi: analisi antifrode, sicurezza, rilevamento bot, prevenzione scraping, protezione da abusi, identificazione di anomalie o controllo di coerenza tra ciò che il client dichiara e ciò che effettivamente risulta essere.
Nel contesto della protezione anti-bot, il fingerprinting non serve necessariamente a identificare una persona. Serve piuttosto a capire se il client che sta effettuando la richiesta assomiglia a un browser reale oppure a un ambiente automatizzato.
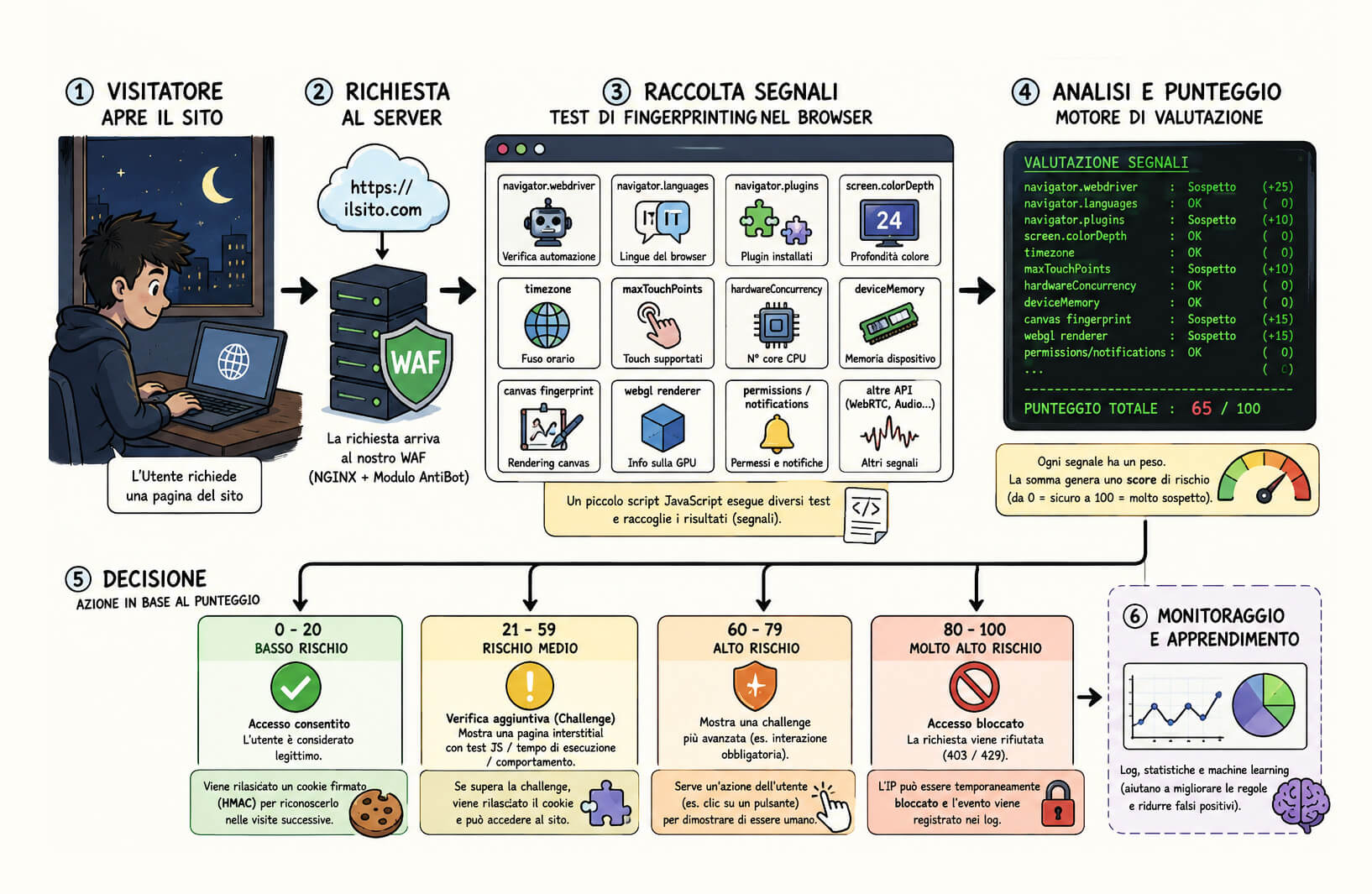
La domanda non è: “Chi è questo utente?”.
La domanda corretta è: “Questo client si comporta e si presenta come un browser reale o come un processo automatizzato che sta fingendo di esserlo?”.
Questa distinzione è fondamentale. Un sistema di protezione moderno non deve necessariamente bloccare tutto ciò che non riconosce. Deve assegnare un livello di rischio. Deve osservare segnali. Deve combinarli. Deve decidere se accettare la richiesta, bloccarla, limitarla, sottoporla a challenge o monitorarla più attentamente.
Un singolo test può produrre falsi positivi. Un insieme di test, ponderato correttamente, può invece fornire un’indicazione molto più robusta.
Le tecniche più utili per distinguere browser reali e bot
Un WAF moderno, soprattutto se progettato per distinguere utenti reali da bot automatizzati, può utilizzare numerosi segnali lato client. Alcuni sono semplici, altri più raffinati. Nessuno è perfetto da solo, ma la combinazione di più tecniche permette di ottenere un profilo molto efficace.
Uno dei controlli più noti è quello su navigator.webdriver. Questa proprietà viene spesso impostata quando un browser è controllato da strumenti di automazione come Selenium, Puppeteer o Playwright. Se il flag risulta attivo, siamo davanti a un segnale molto forte di automazione.
Un altro controllo riguarda le lingue del browser, disponibili tramite navigator.languages. Nei browser reali è normale trovare un array coerente con le impostazioni dell’utente, ad esempio italiano, italiano-Italia, inglese o altre combinazioni. Nei browser headless o negli ambienti artificiali questo valore può essere assente, vuoto o ridotto a un singolo valore generico.
Anche il numero di plugin installati, leggibile tramite navigator.plugins.length, può fornire informazioni interessanti. I browser reali moderni espongono spesso alcuni plugin o componenti integrati, mentre molti ambienti headless ne sono privi. Non è un segnale assoluto, perché l’evoluzione dei browser ha ridotto molto il ruolo dei plugin tradizionali, ma rimane utile come elemento di correlazione.
La profondità colore, ottenibile da screen.colorDepth, può rivelare anomalie. Valori troppo bassi, nulli o incoerenti indicano spesso ambienti di rendering non reali o mal configurati. Allo stesso modo, la risoluzione dello schermo, il rapporto tra viewport e schermo, il device pixel ratio e altri parametri grafici possono aiutare a distinguere un dispositivo reale da un ambiente simulato.
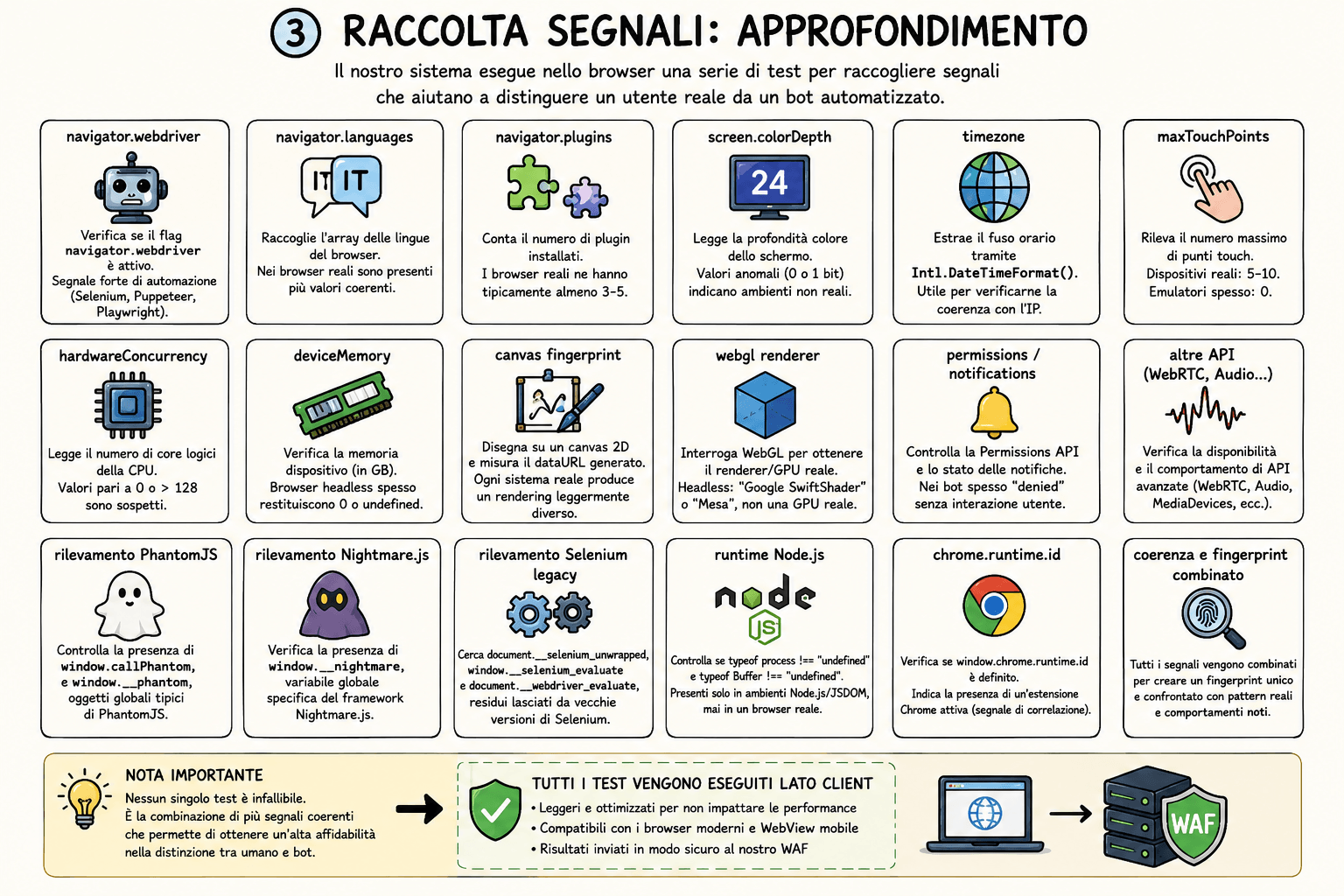
Il fuso orario, ottenibile tramite Intl.DateTimeFormat().resolvedOptions().timeZone, è un altro dato prezioso. Se un IP risulta geolocalizzato in Italia ma il browser dichiara un fuso orario incompatibile, questo non significa automaticamente che siamo davanti a un bot, ma è certamente un segnale da pesare. VPN, viaggi e configurazioni particolari esistono, ma su grandi volumi le incoerenze diventano statisticamente significative.
Anche navigator.maxTouchPoints può essere utile. Un dispositivo mobile reale presenta spesso più punti di contatto touch, mentre un ambiente emulato può dichiarare valori assenti o incoerenti rispetto allo user-agent. Se un client si presenta come iPhone ma non espone caratteristiche compatibili con un dispositivo touch, qualcosa non torna.
navigator.hardwareConcurrency, che indica il numero di core logici disponibili, può evidenziare valori sospetti. Un valore pari a zero, assente o eccessivamente alto può indicare un ambiente artificiale. Lo stesso vale per navigator.deviceMemory, quando disponibile, che fornisce una stima della memoria del dispositivo. Molti browser headless o ambienti automatizzati riportano valori mancanti, generici o poco plausibili.
Tra le tecniche più note c’è il canvas fingerprinting. Si genera un’immagine su un elemento canvas 2D, disegnando testo, forme, colori e trasformazioni. Il risultato viene poi convertito in una rappresentazione misurabile. Ogni combinazione di sistema operativo, motore grafico, font, GPU e driver può produrre piccole differenze. I browser headless, soprattutto se standardizzati e replicati su larga scala, tendono invece a generare output più uniformi e prevedibili.
Un discorso simile vale per WebGL. Interrogando alcune proprietà del renderer, quando disponibili, è possibile ottenere informazioni sulla GPU o sul renderer software utilizzato. Browser headless o ambienti virtualizzati possono esporre renderer come SwiftShader, Mesa o altri backend software, invece di una GPU hardware coerente con il dispositivo dichiarato.
Esistono poi controlli specifici per vecchi framework di automazione. PhantomJS, ad esempio, può lasciare oggetti globali come window.callPhantom o window._phantom. Nightmare.js può esporre window.__nightmare. Versioni legacy di Selenium possono lasciare tracce come document.__selenium_unwrapped, window.__selenium_evaluate o document.__webdriver_evaluate.
Un ulteriore gruppo di controlli riguarda la presenza di ambienti Node.js o JSDOM. In un browser reale non dovrebbero esistere oggetti globali come process o Buffer, tipici invece di ambienti server-side o simulati. Se questi elementi sono disponibili nel contesto della pagina, siamo probabilmente davanti a un ambiente non browser.
Altri segnali possono arrivare dalla Permissions API, dallo stato delle notifiche, dalla presenza di window.chrome, dal comportamento delle API audio, dalla gestione dei font, dal supporto WebRTC, dai codec multimediali, dai sensori disponibili, dalla coerenza tra user-agent e client hints, dalla gestione dei cookie, dal tempo di esecuzione del JavaScript e dal comportamento del client dopo la prima visita.
Il valore non è nel singolo test, ma nel punteggio complessivo
Il punto importante è che nessuno di questi test dovrebbe essere usato in modo cieco e assoluto. Bloccare un utente solo perché un singolo parametro appare anomalo può generare falsi positivi. Ci sono browser particolari, estensioni privacy, configurazioni aziendali, dispositivi embedded, WebView, browser in-app, modalità restrittive, sistemi antitracking e utenti reali con ambienti non standard.
Per questo l’approccio più efficace è quello a punteggio.
Ogni test contribuisce a un risk score. Alcuni segnali sono molto gravi, altri solo debolmente sospetti. Ad esempio, navigator.webdriver attivo può pesare molto. Un fuso orario incoerente può pesare meno. L’assenza di plugin può essere un segnale leggero. Un renderer WebGL software può essere più significativo se combinato con altri elementi. La presenza di oggetti PhantomJS o Selenium legacy può essere considerata molto grave.
A quel punto il WAF può prendere decisioni progressive.
Un client con punteggio molto basso, ad esempio inferiore a 20, può essere considerato legittimo. In questo caso è possibile accettarlo automaticamente e, se opportuno, rilasciare un cookie firmato che consenta di riconoscerlo nelle richieste successive senza ripetere continuamente la verifica.
Un client con punteggio molto alto, ad esempio prossimo a 100, può essere bloccato immediatamente. Se fallisce praticamente tutti i test e mostra segnali evidenti di automazione, non ha senso sprecare risorse backend.
I casi intermedi sono i più interessanti. Un punteggio di 50 o 60 può indicare un client dubbio: non abbastanza pulito per essere accettato automaticamente, ma non abbastanza grave per essere bloccato senza appello. In questi casi si può applicare una challenge più approfondita: un interstitial JavaScript, una verifica comportamentale, una richiesta di interazione, una human checkbox o una modalità simile a quelle rese popolari dai sistemi “Under Attack”.
Questo modello progressivo è molto più efficace del blocco binario. Non divide il mondo in “buoni” e “cattivi” sulla base di un singolo header, ma costruisce una valutazione dinamica e adattiva.
Perché bloccare prima della cache e prima del backend
Un aspetto spesso sottovalutato è il punto dell’infrastruttura in cui viene eseguito il filtering. Se il bot viene bloccato dopo aver raggiunto PHP o il database, il danno è già parzialmente avvenuto. Anche una risposta 403 generata dall’applicazione consuma risorse. Anche un plugin di sicurezza WordPress, se eseguito dentro WordPress, richiede bootstrap del CMS, caricamento di PHP, query al database e uso di memoria.
Per questo le protezioni più efficaci devono agire il più a monte possibile.
Idealmente, il filtro deve intervenire a livello di reverse proxy, WAF, Nginx, OpenResty, Varnish o comunque prima che la richiesta raggiunga il backend applicativo. Bloccare una richiesta indesiderata in meno di un millisecondo, senza coinvolgere PHP-FPM e senza interrogare MySQL, è enormemente più efficiente rispetto a lasciare che sia il CMS a decidere.
Questo principio è particolarmente importante sui siti e-commerce. Se uno scraper sta generando migliaia di richieste a pagine prodotto non cacheate, ogni richiesta intercettata prima del backend rappresenta CPU risparmiata, query evitate e tempo di risposta preservato per gli utenti reali.
Un WAF anti-bot ben progettato non deve diventare a sua volta un collo di bottiglia. Deve essere veloce, leggero, deterministico nelle operazioni più frequenti e capace di prendere decisioni sulla base di cookie firmati, blacklist, whitelist, score e regole di comportamento.
La nostra esperienza con WAF 4 NGINX
Nella nostra recente esperienza abbiamo sviluppato internamente un sistema WAF, AntiBot e AntiCrawler proprietario chiamato WAF 4 NGINX, da non confondere con l’omonima applicazione commerciale storicamente associata a F5 Networks e oggi nota con altra denominazione commerciale “App Protect”
L’obiettivo era chiaro: disporre di una soluzione proprietaria, on premise, controllabile, integrabile con la nostra infrastruttura e concettualmente analoga ad alcune funzionalità rese popolari da Cloudflare, ma senza obbligare il cliente a cambiare nameserver, delegare il traffico a terzi o adottare un servizio esterno non sempre compatibile con vincoli organizzativi, burocratici o GDPR.
Molti clienti possono usare Cloudflare senza problemi. Altri, per policy interne, requisiti contrattuali, sensibilità dei dati, vincoli di conformità o scelte infrastrutturali, preferiscono o devono mantenere pieno controllo sul percorso delle richieste. In questi casi una protezione locale, integrata direttamente sul reverse proxy Nginx, rappresenta un vantaggio importante.
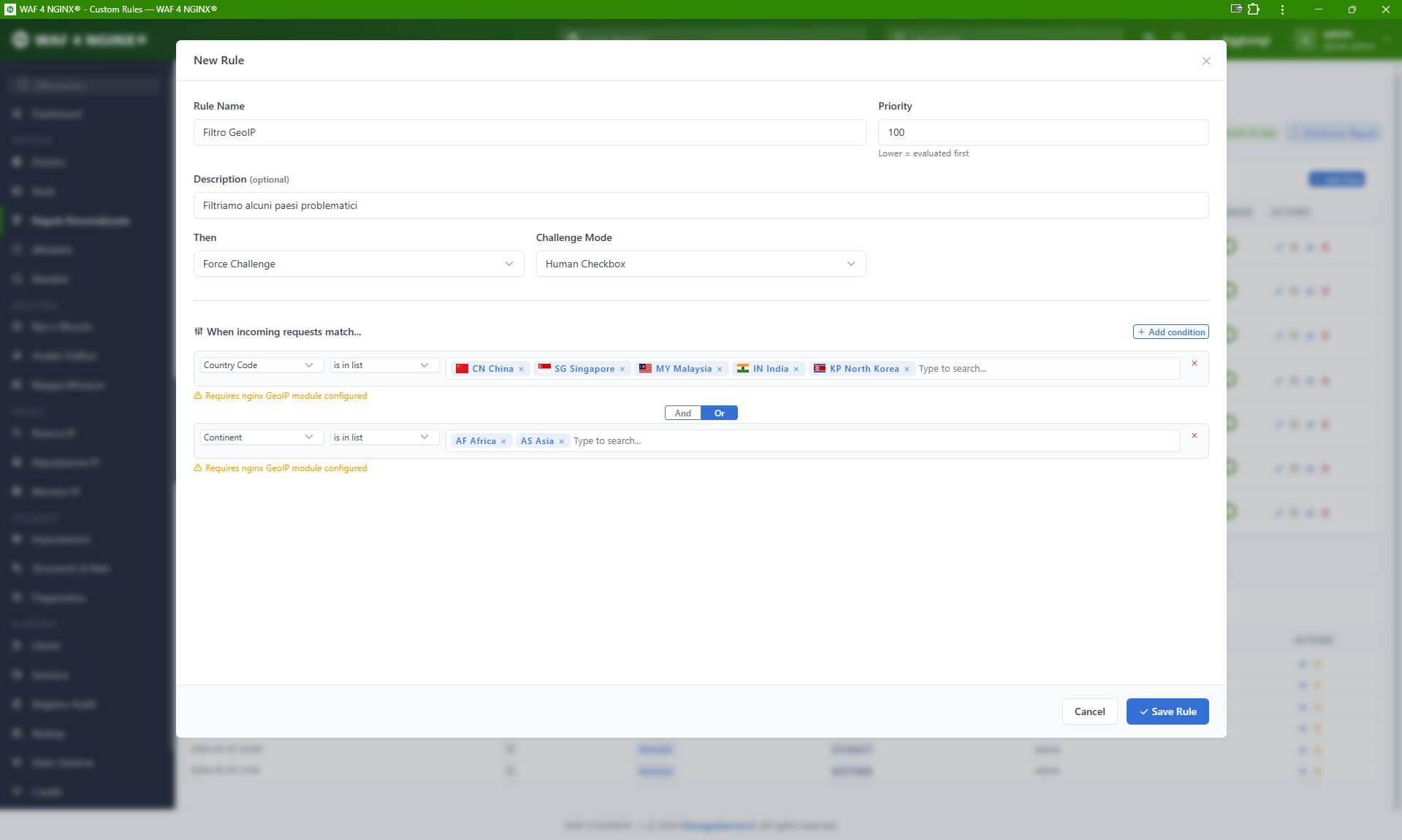
WAF 4 NGINX è stato progettato con diverse modalità operative. Include sistemi di whitelist e blacklist, ban temporanei, regole di filtering personalizzate, controlli sul comportamento delle richieste, challenge JavaScript, modalità trasparenti, interstitial e verifiche più invasive come la human checkbox.
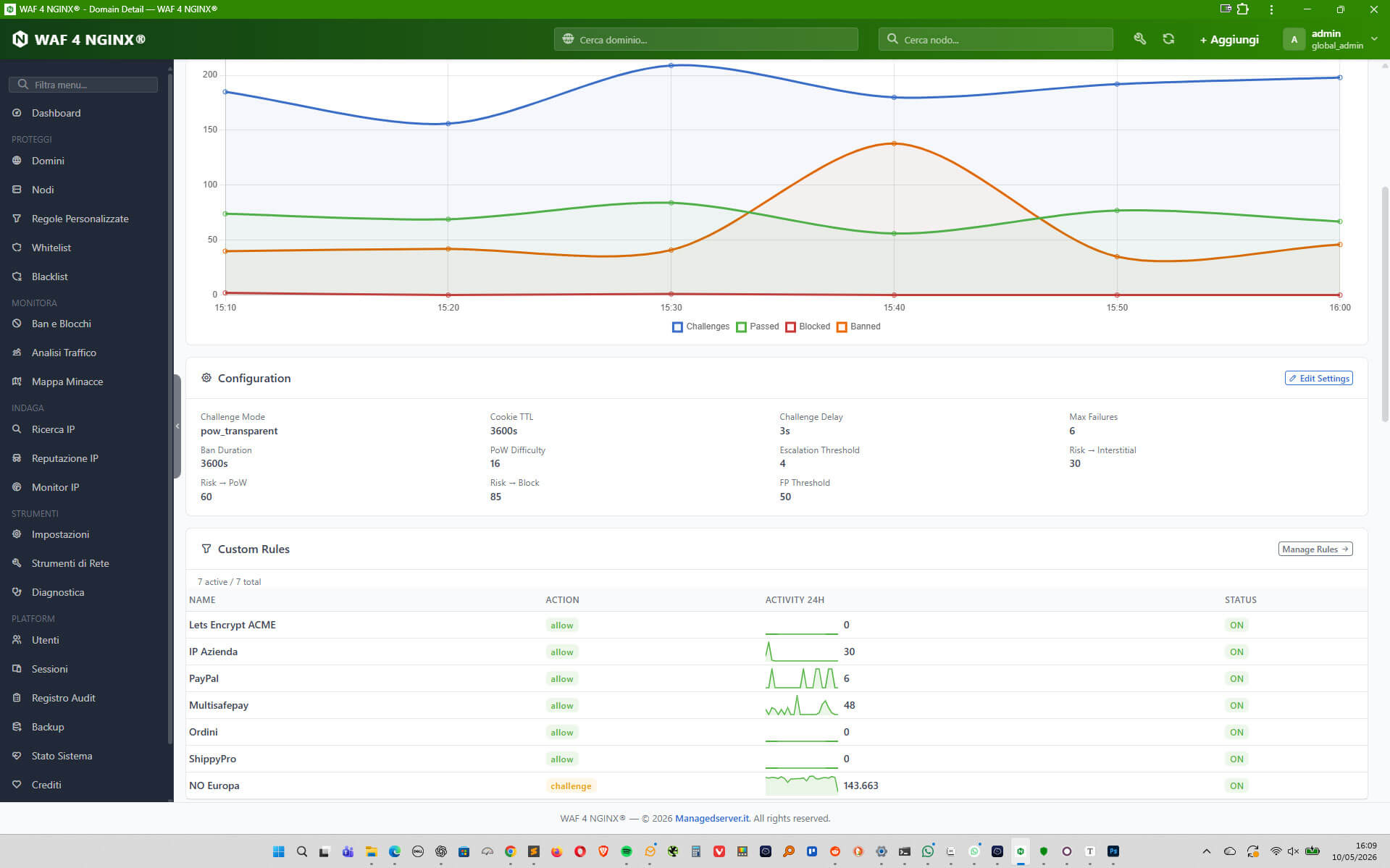
La modalità trasparente è particolarmente interessante perché consente di effettuare verifiche senza mostrare banner, loghi, pagine intermedie o comunicazioni visibili all’utente. Il visitatore reale continua a navigare normalmente, mentre il sistema raccoglie segnali, valuta il fingerprint, assegna uno score e decide se rilasciare un cookie HMAC firmato che attesta l’esito positivo della verifica.
La modalità interstitial, invece, è utile nei casi più critici, quando il sito è sotto attacco, sotto crawling aggressivo o quando il traffico anomalo ha già iniziato a compromettere le performance del backend. In questo scenario viene introdotta una barriera esplicita prima dell’accesso effettivo al sito: il visitatore viene temporaneamente fermato su una pagina intermedia, mentre il sistema esegue controlli lato client, verifica la capacità di eseguire JavaScript, valuta il fingerprint del browser e decide se consentire la prosecuzione della navigazione.
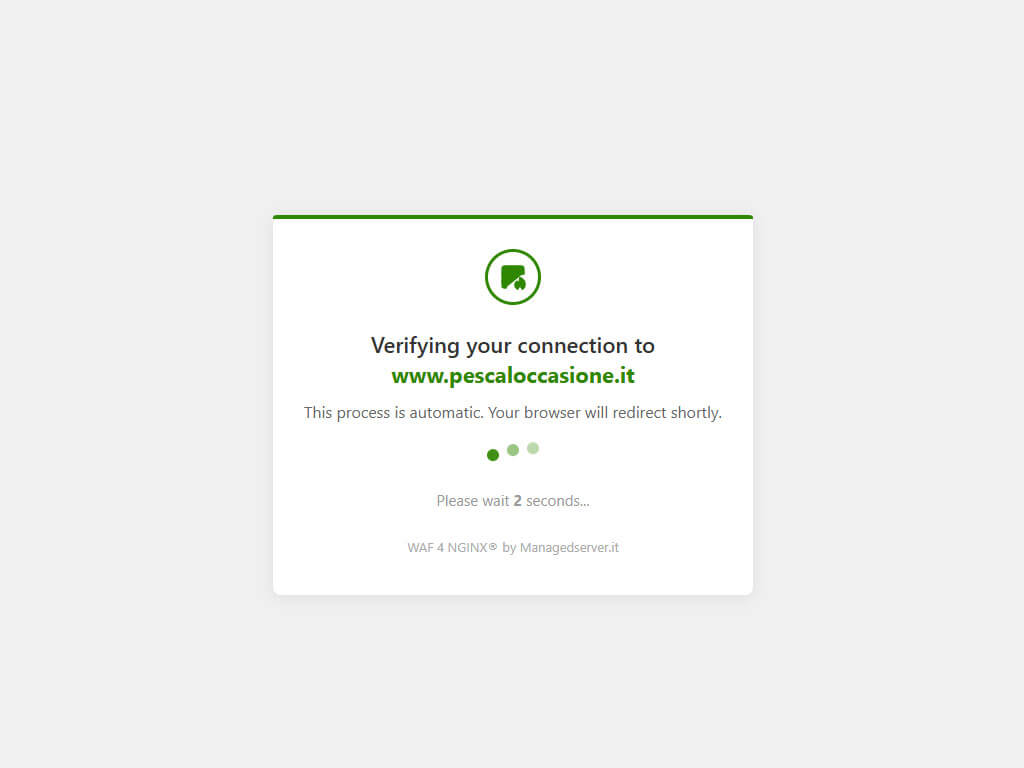
Questa modalità è più visibile rispetto al controllo trasparente, ma ha il vantaggio di alleggerire immediatamente l’infrastruttura, impedendo ai client sospetti di raggiungere direttamente pagine dinamiche, cataloghi, filtri, endpoint di ricerca o aree particolarmente costose dal punto di vista computazionale. È particolarmente indicata durante picchi improvvisi, campagne di scraping massive, scansioni automatizzate su larga scala o tentativi di flooding applicativo.
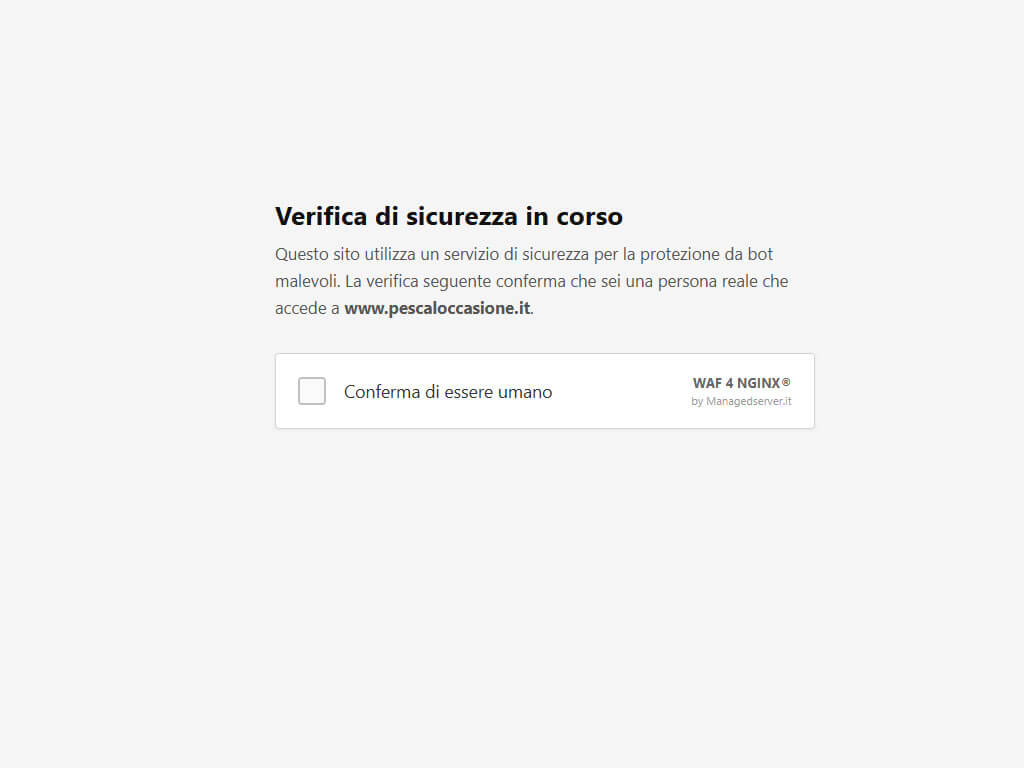
La human checkbox rappresenta invece il livello più invasivo della verifica, ma anche uno dei più efficaci quando è necessario distinguere con maggiore certezza tra traffico umano e automazione. Richiedendo una forma esplicita di interazione, permette di bloccare molti bot che, pur riuscendo a eseguire JavaScript o a simulare parzialmente un browser, non sono progettati per superare una verifica manuale. Proprio per la sua maggiore invasività, dovrebbe essere utilizzata con criterio, preferibilmente nei casi di rischio elevato o come escalation per i client che ottengono un punteggio di sospetto intermedio o alto.
Risultati ottenuti in produzione
I risultati ottenuti in produzione sono stati molto significativi. Nei casi in cui il problema era rappresentato da crawling intensivo, scraping aggressivo o attacchi DDoS L7, l’introduzione del WAF ha permesso di ridurre drasticamente il carico backend e, nella totalità dei casi trattati, eliminare gli interventi manuali di emergenza che prima erano necessari per mitigare saturazioni improvvise.
In particolare, abbiamo osservato una riduzione del carico backend nell’ordine del 50-70% nei siti soggetti a crawling intensivo, soprattutto quando il blocco avveniva prima della cache Varnish e prima del backend applicativo. Questo significa meno richieste a PHP, meno query database, meno saturazione CPU e una maggiore stabilità percepita dagli utenti reali.
Il tempo di risposta del WAF è rimasto costantemente inferiore a 1 millisecondo (durante lo sviluppo siamo arrivati a ragionare su ottimizzazioni in termini di nanosecondi) per richiesta nel 99,9% dei casi misurati in produzione tramite ngx.now() su carichi reali. Questo dato è fondamentale: una protezione anti-bot deve proteggere, non appesantire. Se il sistema di difesa introduce latenza significativa su ogni richiesta, rischia di diventare parte del problema.
Un altro risultato importante è stato l’azzeramento dei falsi positivi rilevati sugli utenti reali nelle modalità transparent, grazie alla combinazione tra challenge, fingerprinting e cookie HMAC firmato. Una volta verificato il client, il sistema può riconoscerlo in modo efficiente senza ripetere continuamente controlli costosi o invasivi.
La compatibilità è stata verificata con i principali browser moderni, incluse WebView mobile e browser in-app come quelli utilizzati da Facebook, Instagram, DuckDuckGo e altri ambienti integrati. Questo aspetto è cruciale perché molti utenti reali non navigano più solo da Chrome desktop o Safari classico. Arrivano da app, browser embedded, dispositivi mobili, ambienti privacy-oriented e configurazioni con Content Security Policy restrittive.
Un sistema anti-bot moderno deve tenere conto di questa varietà. Deve essere efficace contro gli automatismi, ma non deve penalizzare l’utente reale solo perché naviga da un contesto meno tradizionale.
Perché una soluzione on premise può essere preferibile
Cloudflare ha avuto il grande merito di rendere accessibili a un pubblico molto ampio strumenti avanzati di protezione, caching, mitigazione DDoS, ottimizzazione del traffico e challenge anti-bot. Ha inoltre contribuito a tracciare una strada tecnica e concettuale che, inevitabilmente, ha ispirato anche lo sviluppo di rare soluzioni proprietarie come la nostra.
Sarebbe ipocrita sostenere che una soluzione come WAF 4 NGINX sarebbe potuta nascere nello stesso modo senza l’esistenza di piattaforme come Cloudflare. Cloudflare ha reso popolare un approccio moderno alla protezione applicativa: filtrare il traffico prima che raggiunga il backend, valutare il comportamento del client, applicare challenge progressive, distinguere gli utenti legittimi dagli automatismi e proteggere il sito non soltanto dagli attacchi volumetrici, ma anche dagli abusi di livello applicativo.
Per molti siti, servizi di questo tipo rappresentano una soluzione valida, comoda e veloce da implementare. In pochi passaggi è possibile attivare una protezione efficace, beneficiare di una rete distribuita globale, ridurre il carico sull’origine, mitigare attacchi DDoS, migliorare la gestione della cache e introdurre meccanismi anti-bot senza dover sviluppare internamente componenti complessi. Per blog, siti aziendali, portali editoriali e molti e-commerce, questo modello può essere assolutamente adeguato.
Tuttavia, non sempre rappresenta la risposta ideale.
Delegare a un soggetto terzo la gestione del traffico HTTP e HTTPS significa far transitare richieste, header, cookie, indirizzi IP, URL visitate e, in alcuni casi, anche contenuti o dati sensibili attraverso un’infrastruttura esterna. Per molte realtà questo non è un problema, soprattutto quando il beneficio operativo supera ampiamente le implicazioni architetturali. Per altre aziende, invece, questa scelta richiede valutazioni molto più attente.
Alcune organizzazioni non vogliono, per policy interna, che il traffico web passi attraverso un intermediario esterno. Altre non possono cambiare i nameserver perché il DNS è gestito da reparti separati, da fornitori terzi, da policy corporate o da procedure burocratiche molto rigide. In altri casi il dominio è parte di un’infrastruttura più ampia, con record, deleghe, configurazioni mail, servizi legacy e vincoli operativi che rendono complesso o rischioso modificare la gestione DNS.
Esistono poi contesti in cui i vincoli legali, contrattuali o di conformità assumono un peso determinante. Aziende che trattano dati sensibili, pubbliche amministrazioni, portali sanitari, piattaforme B2B, e-commerce con particolari obblighi di trattamento dati o realtà soggette a policy GDPR molto restrittive possono preferire che l’intero ciclo di gestione della richiesta rimanga sotto il proprio controllo infrastrutturale.
Una soluzione on premise consente di decidere esattamente dove vengono processate le richieste, quali dati vengono raccolti, quanto vengono conservati, come vengono firmati i cookie, quali log vengono scritti e quali regole vengono applicate. Questo livello di controllo è particolarmente importante per aziende che trattano dati sensibili, e-commerce con volumi importanti, portali B2B, infrastrutture pubbliche o clienti con compliance stringente, e WAF 4 NGINX da noi sviluppato ed implementato risolve elegantemente il problema ed i requisiti di governance e riservatezza, girando on premise direttamente sul server del cliente.
Inoltre, una soluzione locale può essere adattata con precisione al singolo stack. Un sito WordPress con WooCommerce non ha le stesse esigenze di un Magento. Un PrestaShop con navigazione faccettata non si comporta come un blog editoriale. Un portale headless non ha gli stessi pattern di un sito legacy. Un WAF integrato nel reverse proxy può essere personalizzato per il caso specifico, invece di applicare regole generiche valide per tutti.
Fingerprinting non significa bloccare gli utenti privacy-oriented
Un’obiezione legittima riguarda la privacy. Il browser fingerprinting è spesso associato al tracciamento pubblicitario e alla profilazione invasiva. È quindi importante chiarire la differenza tra fingerprinting usato per advertising e fingerprinting usato per sicurezza.
Nel primo caso l’obiettivo è identificare o seguire un utente tra siti diversi, spesso senza consenso esplicito, per finalità commerciali o pubblicitarie. Nel secondo caso l’obiettivo è valutare se un client è reale o automatizzato, proteggere l’infrastruttura, evitare abusi, prevenire scraping e ridurre attacchi applicativi.
Un sistema progettato correttamente non ha bisogno di costruire profili persistenti invasivi. Può limitarsi a calcolare uno score tecnico, firmare un cookie di validazione, applicare una scadenza ragionevole e conservare solo le informazioni necessarie alla sicurezza. Il principio deve essere quello della minimizzazione: raccogliere quanto basta per distinguere un bot da un browser reale, non quanto possibile per profilare l’utente.
È anche importante evitare un approccio punitivo verso gli utenti attenti alla privacy. Browser con protezioni antitracking, estensioni privacy, configurazioni restrittive o fingerprint parzialmente mascherati non devono essere automaticamente trattati come malevoli. Devono semplicemente ricevere uno score coerente e, se necessario, essere sottoposti a una challenge non invasiva.
Il fingerprinting anti-bot deve essere uno strumento di sicurezza, non uno strumento di sorveglianza.
Il futuro del filtering sarà sempre più comportamentale
Il semplice blocco per IP è destinato a diventare sempre meno efficace. I bot moderni possono cambiare IP, usare proxy residenziali, distribuire richieste, ruotare user-agent, simulare header realistici e imitare alcune caratteristiche dei browser.
Per questo il futuro della protezione sarà sempre più basato sulla combinazione di segnali. Fingerprinting, analisi comportamentale, reputazione IP, coerenza geografica, frequenza delle richieste, pattern di navigazione, validazione JavaScript, cookie firmati, challenge progressive e osservazione del traffico dovranno lavorare insieme.
Un utente reale non naviga come uno scraper. Non apre sistematicamente migliaia di combinazioni di filtri. Non richiede centinaia di URL al minuto con tempi perfettamente regolari. Non ignora completamente asset, immagini, CSS e JavaScript. Non salta da una categoria all’altra seguendo pattern alfabetici o parametrici. Non colpisce endpoint vulnerabili noti in sequenza su decine di siti diversi.
Il comportamento racconta molto. Il fingerprint racconta molto. La coerenza tra dichiarato e reale racconta molto. La forza di un WAF moderno sta nel mettere insieme questi elementi.
Conclusione
Il traffico automatizzato è diventato una delle principali sfide operative per chi gestisce siti web moderni. L’aumento dei crawler legati al mondo AI, unito alla persistenza degli scanner malevoli alla ricerca di vulnerabilità nei CMS, ha reso evidente un fatto: non possiamo più fidarci dello user-agent, dell’IP o di regole statiche troppo semplici.
Quando il traffico indesiderato colpisce siti poco cacheabili, e-commerce complessi o piattaforme con navigazione faccettata, il risultato può essere devastante. CPU alle stelle, database sotto pressione, checkout rallentati, utenti reali penalizzati e costi infrastrutturali inutilmente aumentati.
Aggiungere hardware può aiutare, ma non risolve il problema alla radice. Ottimizzare il database è doveroso, ma non basta se il carico è generato da bot. Bloccare interi paesi può funzionare in alcuni casi, ma diventa impraticabile quando traffico legittimo e traffico malevolo provengono dalle stesse aree geografiche.
Serve un approccio più intelligente, chirurgico e adattivo.
Il browser fingerprinting, se usato correttamente e nel rispetto della privacy, permette di distinguere con maggiore precisione un browser reale da un client automatizzato. Combinato con challenge JavaScript, cookie firmati, scoring progressivo, ban temporanei, whitelist, blacklist e filtering a livello di reverse proxy, diventa uno strumento estremamente efficace per proteggere siti web e infrastrutture applicative.
La nostra esperienza con WAF 4 NGINX dimostra che è possibile ottenere un livello di protezione paragonabile, e in alcuni scenari persino migliore, rispetto a soluzioni esterne come Cloudflare, mantenendo pieno controllo sull’infrastruttura, sulla privacy dei dati e sulla conformità normativa.
Il punto non è bloccare tutto. Il punto è distinguere.
Distinguere il cliente reale dal bot.
Distinguere il crawler dichiarato dallo scraper mascherato.
Distinguere il browser vero dal client HTTP che finge di esserlo.
Distinguere il traffico utile dal traffico che consuma risorse, riduce performance e mette a rischio la disponibilità del servizio.
In un Web sempre più popolato da agenti automatici, questa capacità di distinzione non è più un lusso tecnico. È una necessità operativa.
Se anche il tuo sito ha iniziato a soffrire di carichi immotivati e non riesci ad arginare elegantemente BOT e Crawler contattaci, abbiamo le competenze e la soluzione giusta per te !