
Indice dei contenuti dell'articolo:
Nell’universo del cloud computing, poche tecnologie hanno avuto un impatto tanto significativo quanto il servizio di storage S3 (Simple Storage Service) di Amazon Web Services (AWS). Introdotto nel 2006, S3 ha rivoluzionato il modo in cui le aziende immagazzinano e accedono ai dati, offrendo una soluzione scalabile, sicura e altamente disponibile. Ma come ha fatto S3 a diventare uno standard de facto nel mondo del cloud storage? In questo articolo, esploreremo la nascita e l’evoluzione di S3, le sue caratteristiche distintive rispetto ad altre soluzioni di storage, i vantaggi che offre, e come sia stato adottato anche da altri fornitori, diventando un vero e proprio standard industriale.
Il Protocollo S3 e la Storia Iniziale
S3, acronimo di Simple Storage Service, è uno dei servizi di cloud storage più pionieristici e affidabili offerti da Amazon Web Services (AWS) sin dal suo lancio nel 2006. Ideato per fornire agli sviluppatori una soluzione efficiente e scalabile per l’archiviazione e il recupero di dati in qualsiasi dimensione e da qualsiasi luogo attraverso il web, S3 ha introdotto un cambiamento paradigmatico nel mondo dello storage di dati.
Una delle innovazioni chiave di S3 è il suo modello di storage orientato agli oggetti, che si distingue nettamente dalla tradizionale organizzazione dei dati in filesystem basati su una struttura gerarchica di file e cartelle. Invece di aderire a questo schema convenzionale, S3 adotta un approccio basato su “bucket” e “oggetti”.
Cosa È Un Bucket in S3?
Un bucket in S3 può essere paragonato a un contenitore di alto livello all’interno del quale gli utenti possono immagazzinare e organizzare una varietà di dati sotto forma di “oggetti”. Ogni bucket in S3 è univoco a livello globale, identificato da un nome che è esclusivo in tutto l’ambiente AWS. Questo significa che due bucket diversi, anche se creati da account AWS differenti, non possono avere lo stesso nome. Il concetto di bucket è fondamentale per garantire l’organizzazione e la gestione efficiente dei dati all’interno di S3.
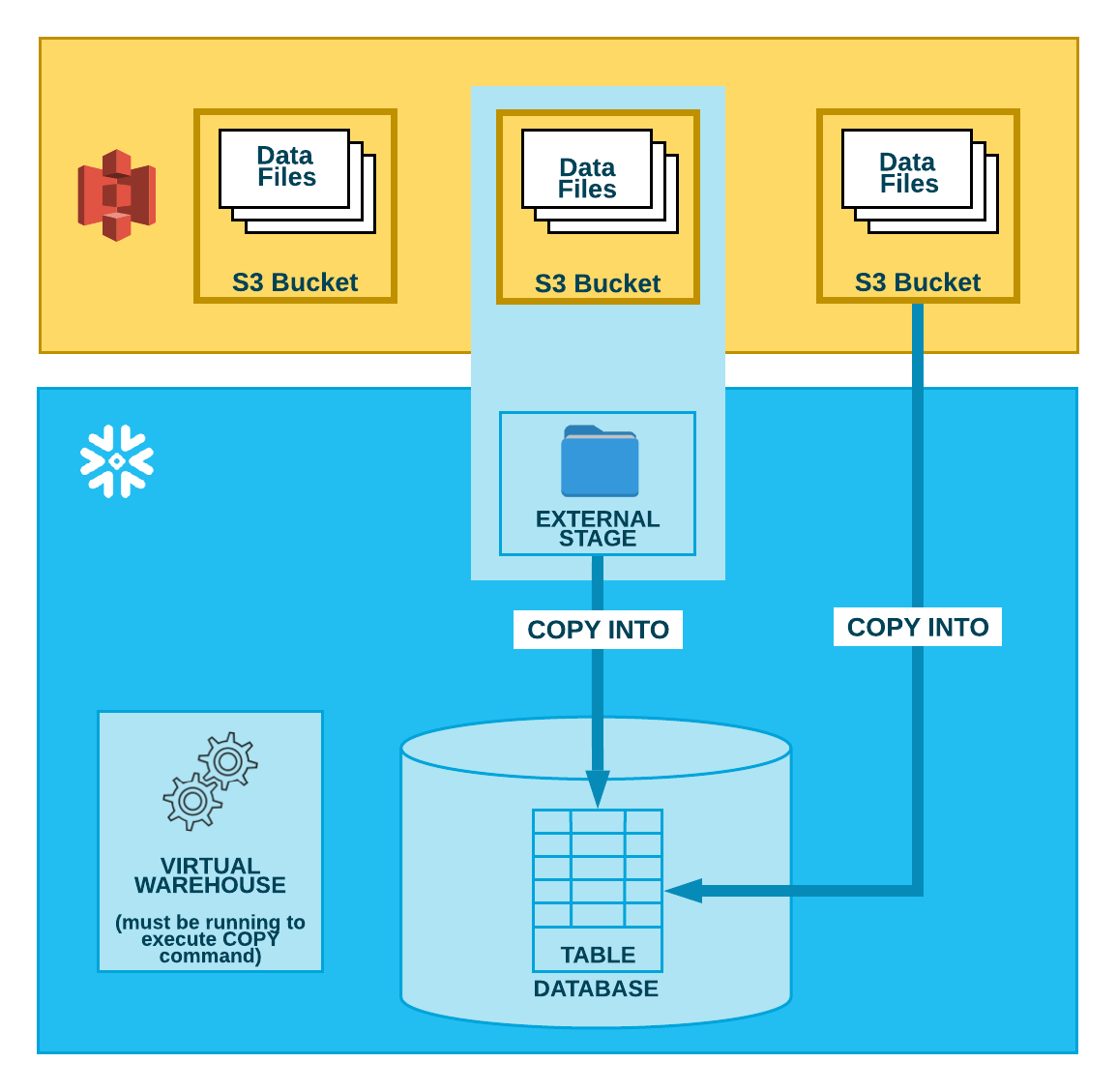
Caratteristiche Tecniche dei Bucket
Nome Univoco
Il requisito che ogni bucket abbia un nome univoco a livello globale è fondamentale per garantire l’unicità e l’accessibilità dei dati su Amazon S3. Questo significa che, una volta scelto un nome per un bucket, questo sarà riservato a livello globale sull’intera piattaforma S3, evitando conflitti e confusioni. Il nome del bucket diventa parte dell’URL attraverso cui si accede ai dati contenuti, seguendo il formato: http(s)://nome-bucket.s3.amazonaws.com/nome-oggetto.
Controllo Accessi
Amazon S3 offre meccanismi di controllo degli accessi sofisticati e granulari per i bucket e gli oggetti contenuti. I proprietari dei bucket possono utilizzare le policy IAM (Identity and Access Management) per definire chi può accedere ai dati e in che modo. Inoltre, S3 supporta le ACL (Access Control Lists) per gestire i permessi a livello di oggetto. Questo livello di controllo permette di gestire scenari complessi, come la condivisione sicura dei dati con utenti esterni o la creazione di ambienti multi-utente.
Regole di Lifecycle
Le regole di lifecycle consentono ai proprietari dei bucket di automatizzare la gestione del ciclo di vita degli oggetti, riducendo i costi e semplificando l’amministrazione del storage. Per esempio, è possibile configurare regole per trasferire automaticamente gli oggetti a classi di storage più economiche dopo un determinato periodo di inattività o per eliminarli automaticamente dopo che hanno raggiunto la fine del loro ciclo di vita utile.
Logging e Monitoraggio
S3 fornisce funzionalità avanzate di logging e monitoraggio che consentono di registrare e analizzare le operazioni eseguite sui bucket e sugli oggetti. Il logging delle richieste fornisce dettagli su chi ha accesso ai dati e come vengono utilizzati, facilitando la conformità e la sicurezza. Il monitoraggio, integrato con Amazon CloudWatch, permette di ricevere allarmi in tempo reale su eventi specifici, come l’aumento inaspettato delle richieste di accesso o dei costi di storage.
Oggetti all’Interno di un Bucket
Identificazione Unica
Ogni oggetto in S3 è identificato da una chiave univoca, che ne determina il percorso all’interno del bucket. Questa chiave, combinata con il nome univoco del bucket, fornisce un identificatore globale per l’oggetto. La struttura piatta di S3 consente di simulare una struttura di directory utilizzando le chiavi degli oggetti, ma è importante ricordare che S3 non utilizza una vera e propria struttura gerarchica.
Metadati
Gli oggetti possono includere metadati, che sono coppie chiave-valore che descrivono o controllano il comportamento dell’oggetto. I metadati standard includono informazioni come il tipo di contenuto (MIME type), la codifica dei contenuti e la data di ultima modifica. Gli utenti possono anche aggiungere metadati personalizzati per soddisfare esigenze specifiche.
Sicurezza e Crittografia
S3 offre opzioni robuste per la sicurezza e la crittografia dei dati. Gli oggetti possono essere criptati sia lato server (SSE-S3, SSE-KMS, SSE-C) che lato client, garantendo che i dati siano protetti sia in transito che a riposo. La crittografia lato server è gestita automaticamente da S3, mentre la crittografia lato client richiede che i dati vengano criptati prima del caricamento.
Come Si Differenzia da Altre Tipologie di Spazio di Archiviazione
Le differenze principali tra S3 e i tradizionali sistemi di file risiedono nella scalabilità, nella durabilità e nella disponibilità. Mentre un filesystem convenzionale è limitato dalla capacità del disco fisico su cui risiede, S3 offre una scalabilità praticamente illimitata, permettendo agli utenti di aumentare e diminuire lo spazio di archiviazione in base alle necessità.
Inoltre, S3 garantisce una durabilità dei dati del 99.999999999% (11 9’s) e una disponibilità del 99.99%, cifre praticamente ineguagliabili dai sistemi di storage tradizionali. Questo è reso possibile attraverso la replicazione automatica dei dati in più data center.
Vantaggi e Caratteristiche Principali
Scalabilità
S3 offre una scalabilità senza precedenti, permettendo alle aziende di archiviare e gestire quantità di dati che variano da pochi byte a diversi petabyte senza preoccuparsi della gestione fisica del storage.
Durabilità e Disponibilità
Con una durabilità del 99.999999999% e una disponibilità del 99.99%, S3 assicura che i dati siano sempre accessibili e protetti da perdite.
Sicurezza
S3 offre robuste funzionalità di sicurezza, tra cui il controllo degli accessi e la crittografia dei dati in transito e a riposo.
Flessibilità
Gli utenti possono scegliere tra diverse classi di storage (ad esempio, Standard, Infrequent Access, Glacier) per ottimizzare i costi in base alle necessità di accesso ai dati.
Contro e svantaggi di S3 rispetto ai Filesystem tradizionali
Sebbene S3 rappresenti il non plus ultra come sistema di Storage a blocchi distribuito, bisogna tener conto oltre che degli innegabili vantaggi, anche degli inevitabili svantaggi di cui dovremmo tener necessariamente conto ad esempio quando avremmo la tentazione di usare S3 come repository per il nostro Database MySQL o PostgreSQL, scelta assolutamente in voga ed altrettanto scellerata per le seguenti motivazioni.
Latency (Latenza)
La latenza misura il tempo necessario affinché un pacchetto di dati viaggi attraverso la rete. Nel caso del confronto tra storage tradizionale basato su file e storage basato su oggetti, lo storage basato su file ha la meglio in questo ambito. Finché il sistema ha il percorso dove i dati sono localizzati, recuperarli è veloce e semplice, specialmente con le soluzioni di storage flash odierne. Lo storage basato su oggetti, d’altra parte, è stato creato pensando all’efficienza dei costi e alla scalabilità, e questi vantaggi sono tipicamente arrivati a scapito della velocità e delle prestazioni.
Prestazioni
La throughput, o la quantità di dati inviati o ricevuti in un determinato lasso di tempo, è la misura delle prestazioni di un sistema. Anche in questo caso, lo storage tradizionale basato su file prende il sopravvento. Mentre lo storage basato su file ti permette di localizzare i dati molto velocemente attraverso il sistema gerarchico, tuttavia, il throughput diventa più lento man mano che devi aprire più directory, cartelle e file. Immagina una directory con milioni di sottodirectory, che hanno milioni di cartelle, che a loro volta contengono milioni di file ciascuna. Lo storage basato su oggetti è migliore per grandi volumi di dati. Anche se potrebbe richiedere un po’ più di tempo per accedere ai tuoi dati, non devi cercarli manualmente—il sistema lo fa per te.
Costo
Il costo è il punto di forza dello storage basato su oggetti. È stato originariamente sviluppato come un sistema per immagazzinare grandi quantità di dati che non devono essere accessi troppo frequentemente, come archivi, filmati video grezzi o dataset secondari. Lo storage basato su oggetti legacy era talvolta chiamato storage “economico e profondo” da chi era nel settore, perché il suo modello di pagamento basato sul consumo effettivo era efficiente in termini di costi. Anche se lo storage basato su file non è considerato estremamente costoso, può risultare in costi più elevati man mano che si aggiunge capacità. Lo storage basato su file non può scalare verso l’alto—deve espandersi aggiungendo altri sistemi di storage basati su file (come un server collegato alla rete, o NAS). E aggiungere interi nuovi sistemi può aumentare i costi.
Protocollo di Accesso
Le modalità con cui i sistemi di storage basati su file e oggetti accedono ai dati sono molto diverse. Lo storage tradizionale basato su file utilizza tipicamente il file system di rete (NFS) o altri protocolli di rete comuni ottimizzati per bassa latenza. Lo storage basato su oggetti tradizionale usa HTTP per accedere ai dati. Questo rende semplice recuperare dati tramite molte diverse applicazioni e persino browser web. Tuttavia, poiché HTTP è basato su testo, viene elaborato più lentamente rispetto ai protocolli di storage basati su file—sottolineando ancora una volta che lo storage basato su oggetti offre un accesso semplice ma non può garantire alte prestazioni.
S3 Come Standard De Facto
L’adozione dell’API S3 di Amazon Web Services ha trascinato il settore dello storage cloud verso un punto di convergenza, dove numerosi fornitori di servizi cloud hanno adottato o reso compatibili le loro offerte di storage con S3, rendendolo di fatto uno standard per lo storage di oggetti nel cloud. Questa compatibilità ha facilitato notevolmente la migrazione, l’integrazione e l’interoperabilità tra diversi ecosistemi cloud, permettendo agli sviluppatori e alle aziende di sfruttare la flessibilità e l’efficienza dello storage basato su oggetti. Di seguito, esploriamo alcuni dei principali servizi che hanno abbracciato questa compatibilità, espandendo l’elenco con aggiunte significative come Wasabi, Scaleway, BackBlaze e CloudFlare R2.
Google Cloud Storage
Offre un’interfaccia compatibile con S3, progettata per facilitare la migrazione e l’interoperabilità dei dati. Questo permette agli utenti di sfruttare le potenti funzionalità di Google Cloud, come l’analisi dei dati e l’intelligenza artificiale, mantenendo una gestione familiare dei dati.
Microsoft Azure Blob Storage
Supporta una modalità di compatibilità con S3, consentendo agli sviluppatori di utilizzare le stesse API di S3 per interagire con i dati. Questo facilita l’integrazione di Azure nelle architetture esistenti basate su S3 e sfrutta le avanzate capacità di Azure in termini di sicurezza e analisi.
IBM Cloud Object Storage
Propone una soluzione di storage di oggetti con compatibilità API con S3, ottimizzata per l’archiviazione e la gestione dei dati su larga scala. IBM Cloud Object Storage è particolarmente indicato per le aziende che necessitano di elevata durabilità e scalabilità per i loro dati.
Alibaba Cloud OSS
Offre servizi di storage di oggetti con compatibilità con le API S3, consentendo una facile integrazione e una gestione dei dati efficiente su scala globale, beneficiando della vasta rete di data center di Alibaba.
Wasabi Hot Cloud Storage
Wasabi si presenta come una soluzione altamente competitiva nel panorama dello storage cloud, offrendo prezzi estremamente competitivi e prestazioni elevate. La sua piena compatibilità con l’API S3 permette una migrazione semplice per gli utenti S3, con il vantaggio aggiunto di non applicare tariffe per egresso o API request, rendendolo una scelta vantaggiosa per un’ampia varietà di casi d’uso, dalla backup alla disaster recovery fino all’archiviazione di lungo periodo.
Scaleway Object Storage
Scaleway offre un servizio di storage di oggetti che combina facilità d’uso e prezzi trasparenti con la compatibilità dell’API S3. Questo lo rende una soluzione attraente per le startup e le aziende in cerca di una piattaforma cloud europea affidabile e conforme alle normative GDPR.
BackBlaze B2 Cloud Storage
BackBlaze B2 fornisce storage di oggetti ad alte prestazioni a un costo significativamente inferiore rispetto ad altri fornitori. La compatibilità con l’API S3 lo rende un’opzione interessante per le aziende che cercano di ridurre i costi di storage senza compromettere la velocità o l’affidabilità.
CloudFlare R2 Storage
CloudFlare R2 si distingue per la sua integrazione nativa con la rete di distribuzione dei contenuti (CDN) di CloudFlare, offrendo storage di oggetti senza tariffe per egresso, il che lo rende particolarmente vantaggioso per i contenuti distribuiti globalmente. La compatibilità con l’API S3 consente agli sviluppatori di sfruttare facilmente questa integrazione, migliorando le prestazioni e riducendo i costi di distribuzione dei contenuti.
Soluzioni S3 compatibili per progetti Self Hosted con MinIO
MinIO è una soluzione di storage di oggetti self-hosted che si distingue per le sue elevate prestazioni e la sua piena compatibilità con le API di Amazon S3. Questa piattaforma è progettata per fornire agli sviluppatori e alle aziende un sistema di storage scalabile, sicuro e facilmente gestibile, sfruttando l’infrastruttura esistente sia on-premise che in cloud privati. Di seguito, approfondiamo il modello di licenza, il costo, le feature compatibili e la tipologia di impiego di MinIO.
Modello di Licenza
MinIO adotta un modello di licenza open source sotto la GNU Affero General Public License v3.0 (AGPLv3), che permette di utilizzare, modificare e distribuire il software liberamente, a condizione che qualsiasi modifica o versione derivata venga anch’essa resa disponibile sotto la stessa licenza. Per le aziende che necessitano di una licenza commerciale, che esclude l’obbligo di rilasciare le modifiche sotto AGPL, MinIO offre opzioni di sottoscrizione enterprise. Questo modello consente alle organizzazioni di beneficiare del supporto tecnico dedicato, delle funzionalità avanzate di sicurezza e di gestione, e delle garanzie SLA (Service Level Agreement).
Costo
MinIO può essere utilizzato gratuitamente nella sua versione open source, rendendolo una scelta attraente per startup e progetti con budget limitati. Per le organizzazioni che cercano funzionalità aggiuntive e supporto professionale, MinIO propone diverse opzioni di sottoscrizione enterprise basate sulla dimensione dell’infrastruttura e sulle esigenze specifiche. Il costo della sottoscrizione enterprise è personalizzato in base ai requisiti del cliente e può variare a seconda del numero di nodi, della capacità di storage necessaria e del livello di supporto richiesto.
Feature Compatibili
MinIO supporta un’ampia gamma di funzionalità compatibili con le API S3, tra cui:
- Bucket e gestione degli oggetti: Creazione, elenco e cancellazione di bucket; caricamento, download e gestione di oggetti.
- Multitenancy: Supporto per ambienti multi-utente con isolamento dei dati.
- Criptazione dei dati: Supporto per la crittografia dei dati a riposo e in transito, utilizzando SSE (Server-Side Encryption) e TLS.
- Controllo accessi fine: Implementazione di politiche di accesso e token di autenticazione per la gestione sicura degli accessi ai dati.
- Replicazione dei dati: Configurazione della replicazione dei dati tra cluster MinIO per la ridondanza e la disaster recovery.
- Gestione del ciclo di vita dei dati: Automazione delle politiche di retention e di eliminazione degli oggetti per ottimizzare i costi e la gestione dello storage.
Tipologia di Impiego
MinIO è particolarmente adatto a scenari di utilizzo che richiedono alte prestazioni, scalabilità e controllo completo dei dati, tra cui:
- Archiviazione dati su larga scala: Ideale per l’archiviazione di dataset di grandi dimensioni, come dati di telemetria, log di sistema, backup e archivi.
- Applicazioni cloud-native: Supporto per applicazioni progettate per l’esecuzione in ambienti cloud, sfruttando container e orchestrazione per una facile scalabilità e gestione.
- Big Data e analitica: Fornisce una piattaforma affidabile per l’immagazzinamento di dati analitici, compatibile con strumenti di elaborazione come Hadoop, Spark e Presto.
- Machine Learning e AI: Archiviazione di grandi volumi di dati utilizzati per l’addestramento e l’inferenza dei modelli di machine learning.
In sintesi, MinIO offre alle aziende una soluzione di storage di oggetti versatile e performante, con la libertà e la flessibilità di un modello open source, ma con la possibilità di optare per supporto e funzionalità avanzate attraverso le sue opzioni enterprise.
Conclusione
Da quando è stato lanciato nel 2006, S3 di Amazon Web Services ha ridefinito le aspettative e le possibilità dello storage di dati nel cloud. La sua affidabilità, scalabilità e sicurezza lo hanno reso uno standard de facto nel settore, una posizione rafforzata ulteriormente dalla sua ampia adozione e dalla compatibilità con altri fornitori di cloud. Con l’avvento di soluzioni come MinIO, anche le organizzazioni che preferiscono gestire il proprio storage possono beneficiare della flessibilità e dell’efficienza di S3. In un mondo sempre più orientato al cloud, S3 continua a essere una colonna portante per le strategie di gestione dei dati di aziende di tutte le dimensioni.