
Indice dei contenuti dell'articolo:
Perché Rspamd è diventato uno standard nei mail server moderni
Gestire un server di posta oggi non significa semplicemente installare Postfix, aprire la porta SMTP e consegnare messaggi nelle mailbox degli utenti. La posta elettronica è uno dei vettori più abusati in assoluto: spam commerciale, phishing, malware, campagne massive, mittenti falsificati, link malevoli, allegati sospetti, newsletter aggressive e botnet che cambiano IP continuamente. In questo scenario, un antispam tradizionale basato solo su regole statiche non è più sufficiente.
Rspamd nasce proprio per rispondere a questa esigenza: non è un semplice filtro che dice “spam” o “non spam”, ma un vero framework di analisi della posta elettronica. Ogni messaggio viene valutato attraverso più controlli indipendenti, chiamati symbol, ognuno dei quali contribuisce a un punteggio complessivo. In base a questo score finale, Rspamd suggerisce al mail server un’azione: accettare, aggiungere header, applicare greylisting, riscrivere l’oggetto, rifiutare o gestire il messaggio secondo policy personalizzate.
In un’infrastruttura basata su Postfix e Dovecot, Rspamd rappresenta uno dei componenti più interessanti perché lavora in modo efficiente, si integra bene con il flusso SMTP, può usare Redis per statistiche e caching, offre una WebUI molto utile per diagnosi e tuning, e permette un apprendimento progressivo basato sia su classificazioni automatiche sia sulle azioni reali degli utenti.
Come funziona Rspamd in pratica
Quando un messaggio arriva al server, Postfix può passarlo a Rspamd tramite integrazione Milter o altri metodi di scansione. Rspamd analizza il messaggio e restituisce un risultato strutturato: score, symbol attivati, azione consigliata e, se configurato, header aggiuntivi. A quel punto il mail server decide cosa fare: consegnare il messaggio, marcarlo come spam, differirlo temporaneamente o rifiutarlo.
Il punto di forza è che Rspamd non si basa su un unico controllo. Un messaggio può ottenere punti spam perché fallisce SPF, perché proviene da un IP con cattiva reputazione, perché contiene URL presenti in blacklist, perché assomiglia a campagne già viste tramite fuzzy matching, perché il Bayes lo classifica come spam o perché attiva regole euristiche sul contenuto. Allo stesso modo, può ottenere punteggi negativi se supera DKIM, DMARC, proviene da mittenti affidabili o corrisponde a whitelist e policy locali.
Questo approccio rende Rspamd molto più flessibile rispetto a un controllo binario. Non esiste un singolo “interruttore” che decide tutto: esiste una somma ponderata di segnali, più adatta a gestire la complessità reale della posta elettronica.
Le principali caratteristiche di Rspamd
Rspamd include numerose funzionalità pensate per ambienti professionali. Le più importanti sono:
- Scoring a simboli: ogni controllo genera uno o più symbol con peso positivo o negativo.
- Azioni configurabili: no action, add header, greylist, rewrite subject, reject, discard, quarantine e azioni personalizzate dove supportate.
- Bayesian filtering: classificazione statistica basata su messaggi spam e ham appresi nel tempo.
- Autolearn: apprendimento automatico dei messaggi molto chiaramente spam o chiaramente legittimi.
- Fuzzy matching: rilevamento di messaggi simili, non solo identici, utile contro campagne spam con piccole variazioni.
- Neural network: modulo neurale per migliorare il riconoscimento sulla base dei pattern osservati.
- SPF, DKIM, DMARC e ARC: verifica dei principali standard di autenticazione email.
- DKIM signing: possibilità di firmare la posta in uscita.
- RBL, DNSBL, SURBL e URL reputation: controlli su IP, domini, URL e reputazione.
- Greylisting: differimento temporaneo dei messaggi sospetti.
- Ratelimit: limitazione di comportamenti anomali o volumi eccessivi.
- Multimap: regole personalizzate basate su mappe locali o remote.
- Settings per utente o dominio: soglie e policy diverse in base a destinatario, mittente, IP, dominio o autenticazione.
- WebUI: interfaccia grafica per consultare history, symbol, score, statistiche e configurazione.
- Redis: backend consigliato per statistiche, caching, Bayes e configurazioni scalabili.
- Integrazione con Sieve: uso degli header di Rspamd per spostare messaggi in Junk e raccolta feedback tramite IMAPSieve.
La documentazione ufficiale descrive Rspamd come un sistema modulare, dove alcune funzionalità core sono implementate in C per performance e altre in Lua per flessibilità e caricamento dinamico.
Score, symbol e azioni: il cuore di Rspamd
Uno degli aspetti più importanti da comprendere è la distinzione tra symbol, score e action. Il symbol è il risultato di un controllo: ad esempio un fallimento SPF, una firma DKIM valida, una corrispondenza Bayes, un URL sospetto o un match fuzzy. Ogni symbol ha un peso. La somma dei pesi produce lo score finale.
Le azioni vengono poi decise in base a soglie configurabili. Una configurazione tipica può prevedere, ad esempio, greylist a partire da 4 punti, add header a partire da 6 punti e reject a partire da 15 punti. La soglia di greylisting produce di fatto un’azione di soft reject, cioè un rifiuto temporaneo che un server legittimo dovrebbe ritentare più avanti.
# /etc/rspamd/local.d/actions.conf
actions {
reject = 15;
add_header = 6;
greylist = 4;
}
Questo modello è molto utile in produzione perché consente di adottare un approccio prudente. Non tutto ciò che è sospetto deve essere rifiutato immediatamente. Alcuni messaggi possono essere solo marcati, altri temporaneamente ritardati, altri ancora respinti solo quando lo score è molto alto.
Fuzzy matching: riconoscere campagne simili, non solo email identiche
Una delle caratteristiche più interessanti di Rspamd è il fuzzy matching. Lo spam moderno raramente invia lo stesso messaggio identico a milioni di destinatari. Più spesso cambia piccole porzioni di testo, aggiunge parole casuali, modifica URL, varia il subject o inserisce elementi dinamici per evitare il rilevamento tramite hash tradizionali.
Un hash classico funziona bene quando due contenuti sono identici. Il fuzzy matching, invece, serve a riconoscere messaggi simili. Rspamd usa un approccio basato su shingles: il testo viene diviso in sequenze sovrapposte di parole, queste sequenze vengono trasformate in hash e poi confrontate probabilisticamente con pattern già noti. Questo permette di intercettare campagne che usano lo stesso template ma introducono piccole variazioni per aggirare i filtri più semplici.
Il modulo fuzzy_check interroga uno o più fuzzy storage worker per verificare se il messaggio assomiglia a pattern già classificati. Lo stesso modulo può gestire anche l’apprendimento, aggiungendo nuovi hash allo storage tramite rspamc o API del controller.
Il fuzzy storage è il componente che conserva gli hash fuzzy. Può essere locale o remoto, può essere usato per blacklist e whitelist separate tramite flag, e può essere aggiornato in modo controllato. La documentazione indica che il fuzzy storage può memorizzare hash e usare una probabilità di match da 0 a 1, dove 1 rappresenta una corrispondenza piena.
In pratica, il fuzzy è particolarmente utile contro:
- campagne spam massive con testo quasi identico;
- phishing che cambia piccoli dettagli tra un invio e l’altro;
- newsletter abusive o contenuti ripetitivi;
- messaggi generati automaticamente con variabili random;
- spam che prova a eludere controlli basati su hash esatto.
Bayes e autolearn: il filtro che migliora nel tempo
Rspamd integra un classificatore Bayesiano, cioè un sistema statistico che impara a distinguere tra messaggi spam e messaggi legittimi, detti ham. Il valore reale del Bayes emerge nel tempo: più il sistema riceve esempi corretti e bilanciati, più diventa capace di riconoscere pattern ricorrenti nella posta del singolo ambiente.
L’apprendimento può essere manuale, usando comandi come rspamc learn_spam e rspamc learn_ham, oppure automatico tramite autolearn. L’autolearn consente a Rspamd di imparare da messaggi con score molto alto o molto basso: ad esempio, imparare come spam un messaggio sopra una certa soglia e come ham un messaggio sotto una soglia negativa. La documentazione prevede parametri come spam_threshold, ham_threshold, check_balance e min_balance, pensati per evitare che il classificatore venga sbilanciato da troppi esempi di una sola classe.
# /etc/rspamd/local.d/classifier-bayes.conf
backend = "redis";
autolearn {
spam_threshold = 8.0;
ham_threshold = -1.0;
check_balance = true;
min_balance = 0.9;
}
La parte più importante è non essere troppo aggressivi. Se si abbassano troppo le soglie, il sistema rischia di imparare messaggi ambigui. In un ambiente professionale conviene far imparare automaticamente solo ciò che è molto evidente, lasciando ai feedback utente o alla revisione manuale i casi dubbi.
Un dettaglio spesso sottovalutato è che l’autolearn avviene dopo la determinazione dell’azione finale e non serve a cambiare la decisione sul messaggio appena analizzato: serve a migliorare il comportamento futuro del classificatore.
Neural network e apprendimento avanzato
Oltre al Bayes, Rspamd include anche un modulo neurale. Il modulo neural può addestrarsi automaticamente in base al verdetto del messaggio o, se configurato, in base a soglie di score. Anche qui il concetto è simile: imparare dai messaggi più rappresentativi e mantenere bilanciamento tra classi per evitare modelli distorti.
In produzione, Bayes e neural non devono essere visti come magie autonome. Sono strumenti potenti, ma richiedono dati buoni. Se il training è sporco, sbilanciato o basato su messaggi classificati male, il risultato peggiora. Per questo motivo è fondamentale progettare bene il flusso di apprendimento, soprattutto quando si raccolgono feedback dagli utenti.
Perché Rspamd si combina molto bene con Sieve
Rspamd e Sieve si completano molto bene perché lavorano in due momenti diversi. Rspamd analizza e classifica il messaggio; Sieve decide cosa farne nella mailbox dell’utente. Questo significa che Rspamd può aggiungere header come X-Spam o X-Spam-Action, mentre Sieve può leggere questi header e spostare automaticamente il messaggio nella cartella Junk.
Nelle integrazioni basate su rspamc --mime, Rspamd può aggiungere header come X-Spam, X-Spam-Action e X-Spam-Result, utilizzabili da LDA, Sieve o Procmail per filtrare ulteriormente la consegna.
require ["fileinto"];
if header :contains "X-Spam" "yes" {
fileinto "Junk";
stop;
}
Questa separazione è molto elegante: Rspamd si occupa dell’intelligenza antispam, Sieve della logica di consegna. In un servizio mail multiutente, questo permette anche di differenziare il comportamento: alcuni utenti possono voler marcare lo spam, altri spostarlo direttamente, altri ancora preferire regole più conservative.
IMAPSieve: trasformare le azioni degli utenti in feedback
Il vero salto di qualità arriva con IMAPSieve. Normalmente Sieve lavora durante la consegna del messaggio, ma IMAPSieve permette di eseguire script anche in risposta a eventi IMAP, come lo spostamento di una email in una cartella. Dovecot, tramite Pigeonhole, mette a disposizione il plugin imap_sieve per abilitare questa logica lato IMAP.
Questo consente un flusso molto interessante: quando un utente sposta un messaggio dalla Inbox alla cartella Junk, il sistema può considerarlo feedback spam. Quando invece sposta un messaggio da Junk alla Inbox, può considerarlo feedback ham. A quel punto uno script può inviare il messaggio a Rspamd tramite rspamc learn_spam o rspamc learn_ham, oppure copiarlo in cartelle di revisione per un controllo manuale.
Rspamd documenta proprio un approccio basato su IMAPSieve per raccogliere feedback dagli utenti quando i messaggi vengono spostati verso o fuori dalla cartella Junk.
protocol imap {
mail_plugins = $mail_plugins imap_sieve
}
plugin {
sieve_plugins = sieve_imapsieve sieve_extprograms
sieve_global_extensions = +vnd.dovecot.pipe
}
Per chiamare programmi esterni da Sieve, Dovecot utilizza il plugin sieve_extprograms, che consente di invocare programmi predefiniti dall’amministratore. Questo è importante anche dal punto di vista della sicurezza, perché gli utenti non possono eseguire arbitrariamente qualsiasi comando di sistema.
Rspamd, Postfix e Dovecot: un flusso ideale
In un’infrastruttura Linux ben progettata, il flusso può essere schematizzato così:
- Postscreen filtra connessioni SMTP grossolane e bot prima di Postfix smtpd.
- Postfix riceve il messaggio e applica le policy SMTP.
- Rspamd analizza il contenuto, la reputazione, gli header, le firme e i pattern statistici.
- Dovecot LMTP/LDA consegna il messaggio alla mailbox.
- Sieve sposta eventuale spam in Junk sulla base degli header.
- IMAPSieve raccoglie feedback quando l’utente sposta manualmente i messaggi.
- Bayes, fuzzy e neural migliorano progressivamente la classificazione futura.
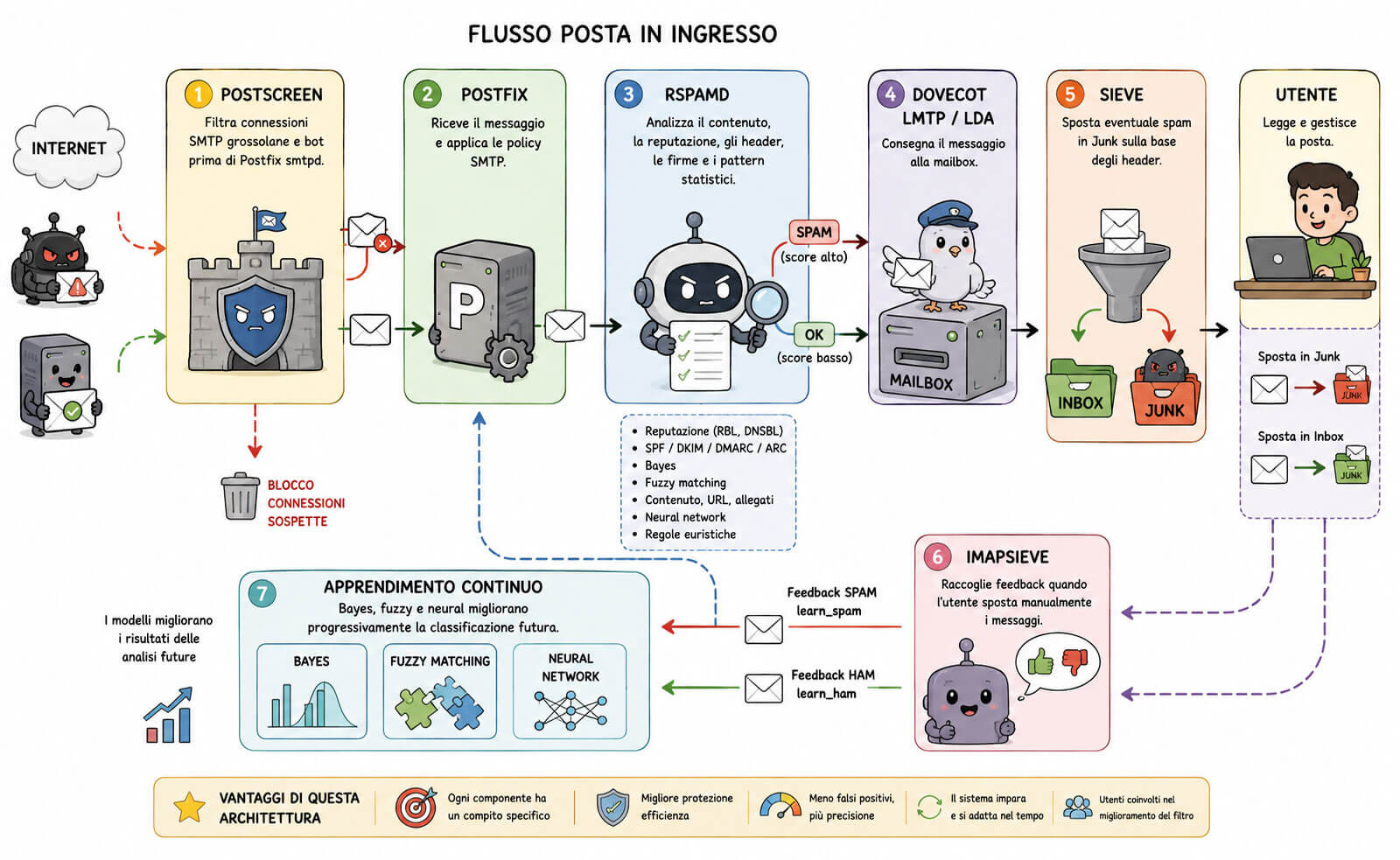
Questa architettura è molto efficace perché divide i compiti. Ogni componente fa ciò per cui è progettato: Postfix gestisce SMTP, Rspamd classifica, Dovecot consegna, Sieve ordina, IMAPSieve raccoglie feedback. Il risultato è un sistema più pulito, più scalabile e più facile da diagnosticare.
Settings per dominio, utente e contesto
Una delle funzionalità più utili in ambienti hosting è la possibilità di applicare impostazioni diverse per dominio, destinatario, mittente, IP o stato di autenticazione. Il modulo settings consente di modificare soglie, azioni e moduli abilitati in base a condizioni specifiche. Questo è particolarmente importante in ambienti multi-tenant, dove non tutti i clienti hanno le stesse esigenze.
Un dominio aziendale molto sensibile può richiedere soglie più severe; un reparto marketing può ricevere molte newsletter legittime e avere bisogno di policy meno aggressive; gli utenti autenticati in uscita possono essere gestiti con logiche diverse rispetto alla posta in ingresso da Internet.
# /etc/rspamd/local.d/settings.conf
azienda_strict {
rcpt = "@azienda.it";
apply {
actions {
reject = 10.0;
add_header = 5.0;
greylist = 3.0;
}
}
}
marketing_relaxed {
rcpt = "@marketing.azienda.it";
apply {
actions {
reject = 20.0;
add_header = 10.0;
greylist = null;
}
}
}
WebUI, log e tuning operativo
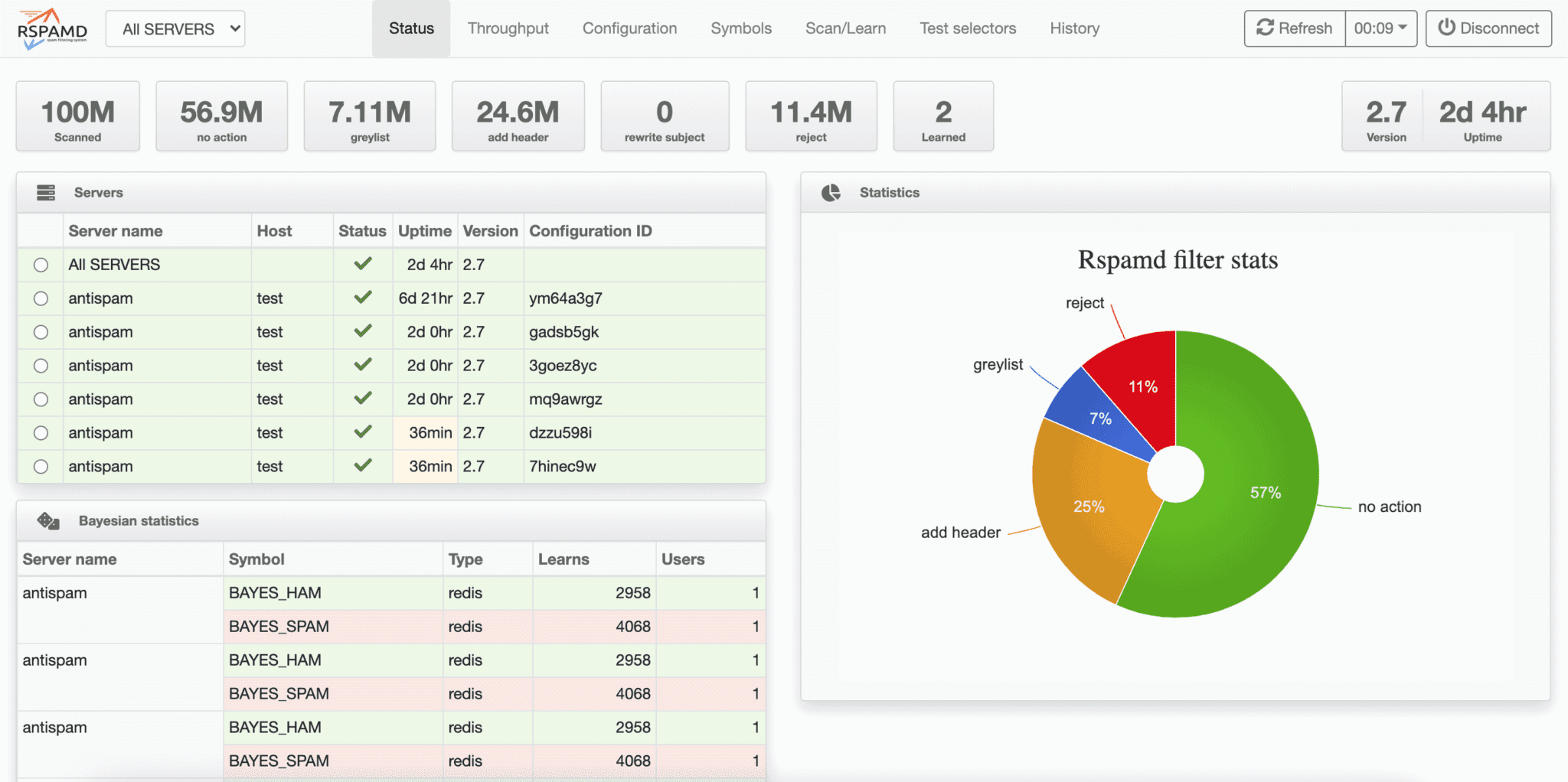
Rspamd offre una WebUI estremamente utile per chi amministra sistemi mail. Da lì è possibile consultare i messaggi analizzati, vedere i symbol attivati, verificare gli score, controllare statistiche, eseguire training e capire perché un messaggio è stato considerato spam o ham.
Questo è un vantaggio operativo enorme rispetto ai filtri opachi. Quando un cliente segnala “questa email è finita in spam”, l’amministratore può osservare i symbol reali e capire se il problema deriva da SPF, DKIM, DMARC, Bayes, URL reputation, fuzzy, RBL o regole locali. Il tuning diventa così un lavoro basato su evidenze, non su supposizioni.
Falsi positivi e buone pratiche
Un antispam efficace deve bloccare molto spam, ma soprattutto deve evitare di bloccare posta legittima. Il falso positivo è spesso più grave dello spam lasciato passare, perché può causare perdita di comunicazioni commerciali, ticket, ordini, fatture o notifiche importanti.
Per questo motivo, in produzione conviene seguire alcune buone pratiche:
- usare soglie di reject conservative, almeno nella fase iniziale;
- marcare e spostare in Junk prima di rifiutare in modo definitivo;
- abilitare autolearn solo su score molto affidabili;
- mantenere bilanciato il training spam/ham;
- monitorare i symbol più ricorrenti nei falsi positivi;
- usare whitelist e settings solo quando realmente giustificati;
- non affidarsi a una sola RBL o a un solo criterio di classificazione;
- integrare il feedback degli utenti tramite IMAPSieve o revisione manuale.
Perché Rspamd è adatto a un servizio di posta managed ?
In un contesto managed, Rspamd è particolarmente interessante perché permette di offrire un filtro antispam moderno senza introdurre complessità ingestibili. È veloce, modulare, osservabile e adattabile. Può essere configurato in modo prudente per evitare falsi positivi, ma anche irrigidito per domini bersagliati da attacchi o phishing.
La combinazione con Redis consente di gestire statistiche e dati in modo efficiente. La WebUI facilita diagnosi e supporto. L’integrazione con Sieve permette di tradurre il risultato antispam in azioni concrete nella mailbox. Il feedback degli utenti chiude il cerchio, trasformando le correzioni manuali in dati utili per il futuro.
Rispetto a un antispam puramente statico, Rspamd è più adatto alla posta reale: cambia, impara, combina segnali e consente tuning granulare. Non elimina la necessità di una buona configurazione DNS, SPF, DKIM, DMARC, reverse DNS e reputazione IP, ma diventa il centro intelligente della protezione mail.
Conclusione
Rspamd è oggi una delle soluzioni più complete per proteggere un’infrastruttura email basata su Linux, Postfix e Dovecot. Il suo valore non sta solo nella capacità di riconoscere spam, ma nella possibilità di combinare scoring, regole, reputazione, autenticazione, Bayes, fuzzy matching, neural network, policy per dominio e feedback utente.
Il fuzzy matching consente di intercettare campagne simili anche quando i messaggi non sono identici. L’autolearn permette al sistema di migliorare nel tempo, purché configurato con soglie prudenti e bilanciamento corretto. Sieve e IMAPSieve trasformano la classificazione in azioni concrete e permettono agli utenti di contribuire al miglioramento del filtro semplicemente spostando messaggi dentro o fuori dalla cartella Junk.
In un’infrastruttura managed, Rspamd non è solo un antispam: è un componente strategico di sicurezza, qualità del servizio e continuità operativa. Configurato correttamente, riduce il rumore, migliora la deliverability interna, semplifica la diagnosi e offre agli amministratori un controllo molto più fine sul comportamento della posta elettronica.