
Indice dei contenuti dell'articolo:
In questo scenario la domanda diventa inevitabile: come si può risparmiare sui Server Dedicati senza peggiorare prestazioni, stabilità e sicurezza? La risposta parte da un principio semplice: prima di comprare più risorse bisogna ridurre gli sprechi. Molto spesso un server non è realmente troppo piccolo. È costretto a servire traffico inutile, a eseguire codice non ottimizzato, a generare pagine dinamiche che potrebbero essere cacheable, a gestire bot aggressivi, query inefficienti, endpoint esposti e richieste che non producono valore.
Il server più economico è quello che non viene sprecato
Quando un sito rallenta, la reazione più comune è guardare CPU e RAM e concludere che serva un server più potente. È una lettura comprensibile, ma spesso incompleta. Un picco di CPU può essere causato da utenti reali, ma anche da crawler non desiderati. Un consumo elevato di RAM può dipendere da traffico legittimo, ma anche da troppi worker PHP occupati da richieste dinamiche inutili. Un database sotto stress può indicare una crescita del business, ma anche una ricerca interna bombardata da bot o filtri prodotto interrogati migliaia di volte al giorno.
Prima di spendere di più conviene chiedersi se il server attuale stia lavorando per utenti, clienti e processi utili oppure se stia consumando risorse per automazioni senza valore. Ogni richiesta gestita inutilmente dall’applicazione è una piccola tassa: CPU, RAM, I/O, database, log, banda e tempo di risposta.
Risparmiare sui Server Dedicati significa quindi ragionare in termini di efficienza. Un’infrastruttura ben progettata deve rispondere velocemente agli utenti reali, ma deve anche essere capace di non sprecare risorse per ciò che non merita di arrivare all’origine. In altre parole: non basta avere un server performante. Serve un server governato.
Il traffico non umano ha un costo reale
Una parte sempre più significativa del traffico web non proviene da persone reali. Bot, scraper, crawler SEO, crawler AI, scanner di vulnerabilità, sistemi di monitoraggio, automazioni commerciali, strumenti di preview, tentativi di brute force, credential stuffing e comment spam generano milioni di richieste ogni giorno verso siti, e-commerce, CMS e API.
Non tutti i bot sono dannosi. I crawler dei motori di ricerca possono essere fondamentali per la visibilità organica. I sistemi di monitoraggio sono utili. Alcune integrazioni esterne devono poter accedere a endpoint specifici. Il problema nasce quando il traffico automatizzato è eccessivo, non verificato, aggressivo o economicamente inutile. Un bot che accede a una pagina cacheable può avere un costo limitato. Un bot che forza cache MISS, interroga ricerche interne, colpisce REST API, genera sessioni, apre carrelli, tenta login o attraversa filtri prodotto può invece diventare costoso quanto, e talvolta più, di un utente reale.
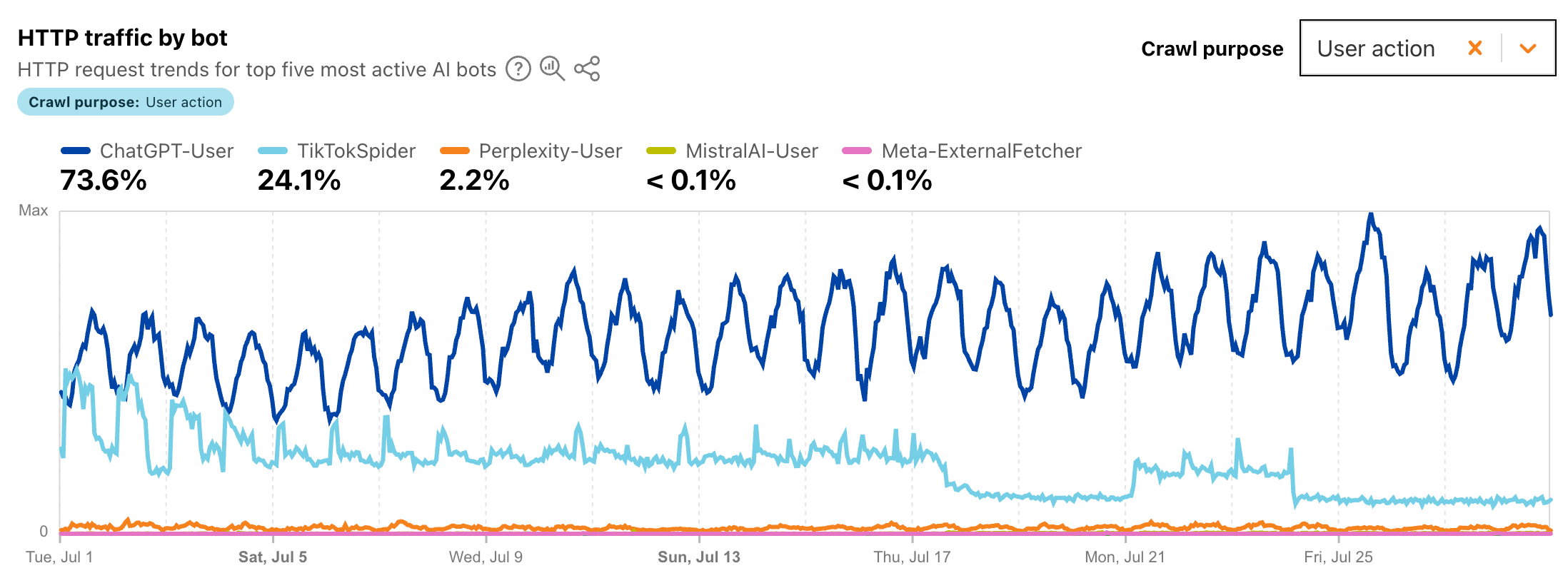
Per WordPress, WooCommerce, Magento, PrestaShop e Joomla questo tema è particolarmente importante. Molte richieste apparentemente banali possono attivare PHP, plugin, hook applicativi, query MySQL o MariaDB, Redis, controlli di sessione, calcolo prezzi, disponibilità magazzino, moduli di spedizione o funzioni di ricerca. Se queste richieste provengono da bot non utili, il sito sta pagando infrastruttura per traffico che non compra, non converte e non porta valore.
Filtering: bloccare prima che il costo arrivi al backend
Uno dei modi più concreti per risparmiare è introdurre un sistema di filtering a monte dell’applicazione. Il concetto è semplice: una richiesta bloccata o limitata da Nginx, Varnish, HAProxy, un reverse proxy o un WAF costa molto meno di una richiesta lasciata arrivare fino a PHP-FPM e al database. Più la decisione avviene vicino al bordo dell’infrastruttura, minore è il costo.
Un buon sistema di filtering non deve essere un muro cieco. Bloccare tutto è facile, ma può danneggiare SEO, integrazioni legittime e utenti reali. Serve una governance selettiva: crawler verificati ammessi, bot sospetti limitati, scanner bloccati, endpoint sensibili protetti, richieste troppo frequenti rallentate o respinte, path inutili chiusi, aree amministrative ristrette, API controllate.
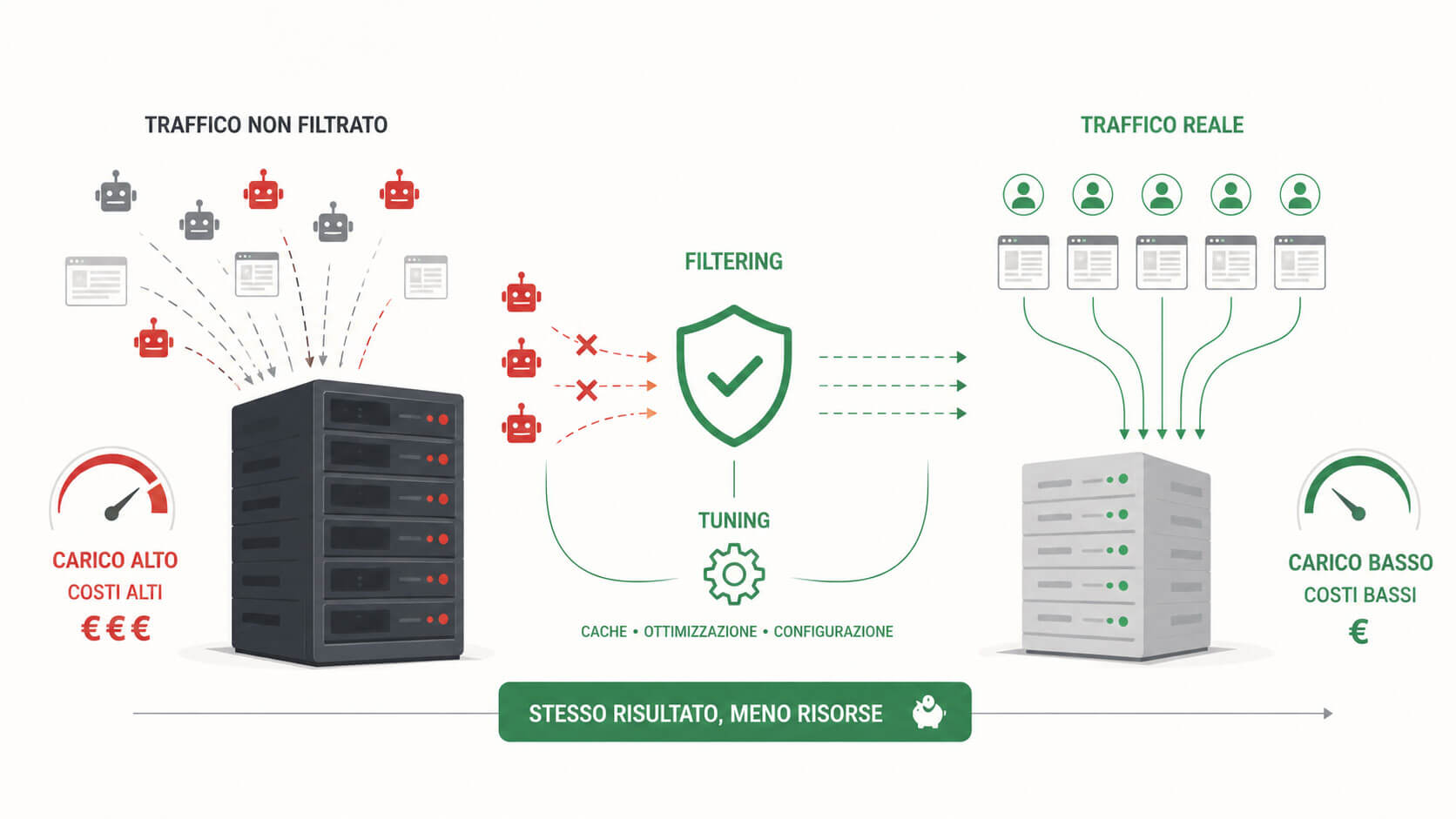
Tuning: far rendere davvero l’hardware acquistato
Il secondo grande capitolo è il tuning. Molte aziende acquistano server più grandi non perché ne abbiano davvero bisogno, ma perché l’ambiente applicativo è configurato in modo generico. Un server dedicato non ottimizzato può comportarsi peggio di una macchina più piccola ma ben configurata. Il tuning serve proprio a trasformare l’hardware disponibile in prestazioni reali.
Nel mondo web questo significa lavorare su più livelli. A livello web server bisogna configurare correttamente keepalive, timeout, compressione, HTTP/2 o HTTP/3 quando disponibili, gestione delle connessioni, buffer, limiti per client e caching degli asset statici. A livello PHP-FPM occorre dimensionare i processi in base alla RAM reale, evitando sia la carenza di worker sia l’eccesso di processi che porta allo swap. OPcache deve essere attivo, dimensionato e monitorato. I timeout devono essere coerenti con l’applicazione, non lasciati a valori casuali.

Sul database il tuning è ancora più importante. MySQL, MariaDB o Percona Server devono essere configurati in base al carico, alla quantità di RAM, al tipo di query e alla dimensione dei dati. InnoDB buffer pool, redo log, temporary tables, query lente, indici mancanti, connessioni simultanee e lock vanno osservati e corretti. Un database mal configurato può far sembrare insufficiente qualsiasi server, mentre un database ben regolato può ridurre drasticamente latenze, I/O e carico CPU.
La cache è il terzo elemento decisivo. Full page cache, Varnish, Nginx FastCGI cache, Redis object cache, cache applicativa e CDN devono lavorare in modo coerente. L’obiettivo non è solo “mettere cache”, ma aumentare la percentuale di HIT e ridurre le richieste dinamiche inutili. Se un sito serve pagine cacheabili passando ogni volta da PHP e database, sta letteralmente bruciando soldi.
Comprare un entry level invece di un server grande
Il beneficio economico diventa evidente quando si ragiona sul dimensionamento. Se un sito non filtrato e non ottimizzato richiede un server di fascia alta per reggere bot, query lente e cache MISS, il costo mensile sale. Se lo stesso sito viene filtrato a monte, alleggerito, cacheato e ottimizzato, può spesso funzionare bene su un server entry level o su una macchina intermedia molto più economica.
Questo non significa promettere che qualunque progetto possa stare su un server piccolo. Significa però che la capacità necessaria non dipende solo dal numero di visite, ma dal costo medio di ogni richiesta. Mille richieste cache HIT possono pesare pochissimo. Mille richieste dinamiche verso PHP e database possono saturare un server. Diecimila richieste bloccate a monte possono costare meno di cento richieste lasciate arrivare a un endpoint pesante.
La scelta del server dovrebbe quindi arrivare dopo una fase di misurazione. Prima si analizzano log, cache HIT ratio, richieste per path, bot più attivi, endpoint più costosi, query lente, picchi CPU, RAM, I/O, saturazione PHP-FPM, tempi database, errori 502/503, traffico per ASN e user-agent. Poi si decide se il problema è davvero la mancanza di hardware o se è una cattiva gestione del carico.
Una checklist concreta per ridurre i costi
Il percorso ideale parte dalla visibilità. Senza log e metriche si decide a sensazione. Bisogna sapere chi consuma risorse, quali URL pesano di più, quali bot colpiscono il sito, quali richieste bypassano la cache e quali query rallentano il database. Solo dopo si possono applicare regole efficaci.
Il secondo passo è filtrare. Proteggere login, XML-RPC, REST API, aree amministrative, form, ricerca interna, carrello, checkout, endpoint AJAX e API pubbliche. Limitare i bot sospetti. Verificare i crawler realmente importanti. Bloccare scanner e richieste palesemente abusive. Ridurre il traffico che non deve arrivare al backend.
Il terzo passo è ottimizzare. Configurare correttamente web server, PHP-FPM, OPcache, database, Redis, cache di pagina, compressione, asset statici, indici SQL e plugin. Rimuovere ciò che non serve. Ridurre chiamate esterne lente. Evitare cron inefficienti. Separare, quando necessario, i workload più pesanti.
Il quarto passo è dimensionare. Solo dopo filtering e tuning ha senso decidere se restare su un server entry level, passare a una fascia intermedia o acquistare una macchina più grande. In molti casi il lavoro di ottimizzazione permette di rimandare l’upgrade, evitarlo del tutto o scegliere una configurazione più economica rispetto a quella inizialmente ipotizzata.
Conclusione
Risparmiare sui Server Dedicati non significa comprare sempre la macchina più piccola possibile. Un server sottodimensionato produce downtime, lentezza, perdita di vendite, peggioramento dei Core Web Vitals, stress operativo e costi nascosti. Il risparmio intelligente consiste nel comprare la macchina giusta, non quella più grande per paura né quella più piccola per risparmiare a tutti i costi.
In un mercato in cui l’hardware server diventa più caro, l’efficienza non è più un dettaglio tecnico: è una leva economica. Ogni richiesta inutile bloccata a monte, ogni cache HIT in più, ogni query lenta eliminata, ogni bot governato, ogni processo PHP risparmiato contribuisce a ridurre il carico complessivo e quindi il bisogno di acquistare server più grandi.
La domanda “come risparmiare sui Server Dedicati?” non dovrebbe quindi partire dal listino del provider, ma dall’analisi del carico. Quanto traffico è umano? Quanto è bot? Quanto arriva all’origine? Quanto viene servito da cache? Quanto costa ogni richiesta? Quali endpoint consumano davvero CPU, RAM e database?
Chi sa rispondere a queste domande può comprare meglio, dimensionare meglio e spesso spendere meno. Chi le ignora rischia di pagare hardware sempre più costoso per servire traffico che non genera valore. Oggi il vero risparmio non è solo trovare il server dedicato più economico. È fare in modo che ogni euro speso in infrastruttura lavori per utenti reali, conversioni reali e prestazioni realmente utili.