
Indice dei contenuti dell'articolo:
Introduzione
Quando si parla di backup dei database, l’errore più comune è pensare che il problema sia semplicemente “avere una copia”. In realtà, in un ambiente di produzione, il vero punto non è soltanto fare backup, ma essere in grado di ripristinare i dati nel momento esatto in cui servono. Una copia notturna può essere sufficiente per scenari banali, ma diventa insufficiente quando l’incidente avviene nel mezzo della giornata: una tabella cancellata per errore, una migrazione applicativa sbagliata, un aggiornamento massivo eseguito senza clausola WHERE, una cancellazione accidentale da parte di un gestionale o un bug applicativo che corrompe dati già presenti.
In questi casi entra in gioco il PITR, acronimo di Point In Time Recovery. Con PostgreSQL il PITR è una funzionalità estremamente solida, nativa e matura, basata su un concetto molto preciso: ripristinare un base backup fisico del cluster e poi riapplicare i file WAL, Write-Ahead Log, fino al punto temporale desiderato. Il risultato è un database riportato allo stato coerente che aveva in un determinato istante, per esempio pochi secondi prima di un errore umano.
Rispetto a un semplice pg_dump, il PITR lavora a un livello diverso. Non riguarda l’esportazione logica di una singola tabella o di un singolo database, ma il ripristino fisico dell’intero cluster PostgreSQL. Questo è un aspetto importante: il PITR non è pensato per recuperare selettivamente una tabella dentro un database lasciando tutto il resto invariato. È invece una procedura di disaster recovery che permette di ricostruire l’intero ambiente PostgreSQL fino a un determinato momento.
Il principio di funzionamento del PITR in PostgreSQL
PostgreSQL, come molti database relazionali moderni, utilizza un sistema di logging chiamato Write-Ahead Logging. Prima che una modifica venga considerata definitivamente persistente nei file dati, PostgreSQL scrive le informazioni necessarie nei WAL. Questo meccanismo serve per garantire consistenza, crash recovery, replica fisica e, appunto, Point In Time Recovery.
I WAL sono una sequenza ordinata di segmenti che descrivono le modifiche avvenute nel cluster: transazioni, insert, update, delete, modifiche agli indici e altre operazioni interne. Se abbiamo un backup fisico preso a un certo momento e disponiamo di tutti i WAL prodotti da quel momento in avanti, PostgreSQL può riprodurre quelle modifiche fino a raggiungere lo stato desiderato.
Lo schema logico è semplice:
Base backup fisico + WAL archiviati = possibilità di recovery fino a un punto nel tempo
Il base backup rappresenta il punto di partenza. I WAL rappresentano la storia successiva. Il recovery target indica a PostgreSQL dove fermarsi: una data e ora precisa, un transaction ID, un LSN oppure un restore point nominato.
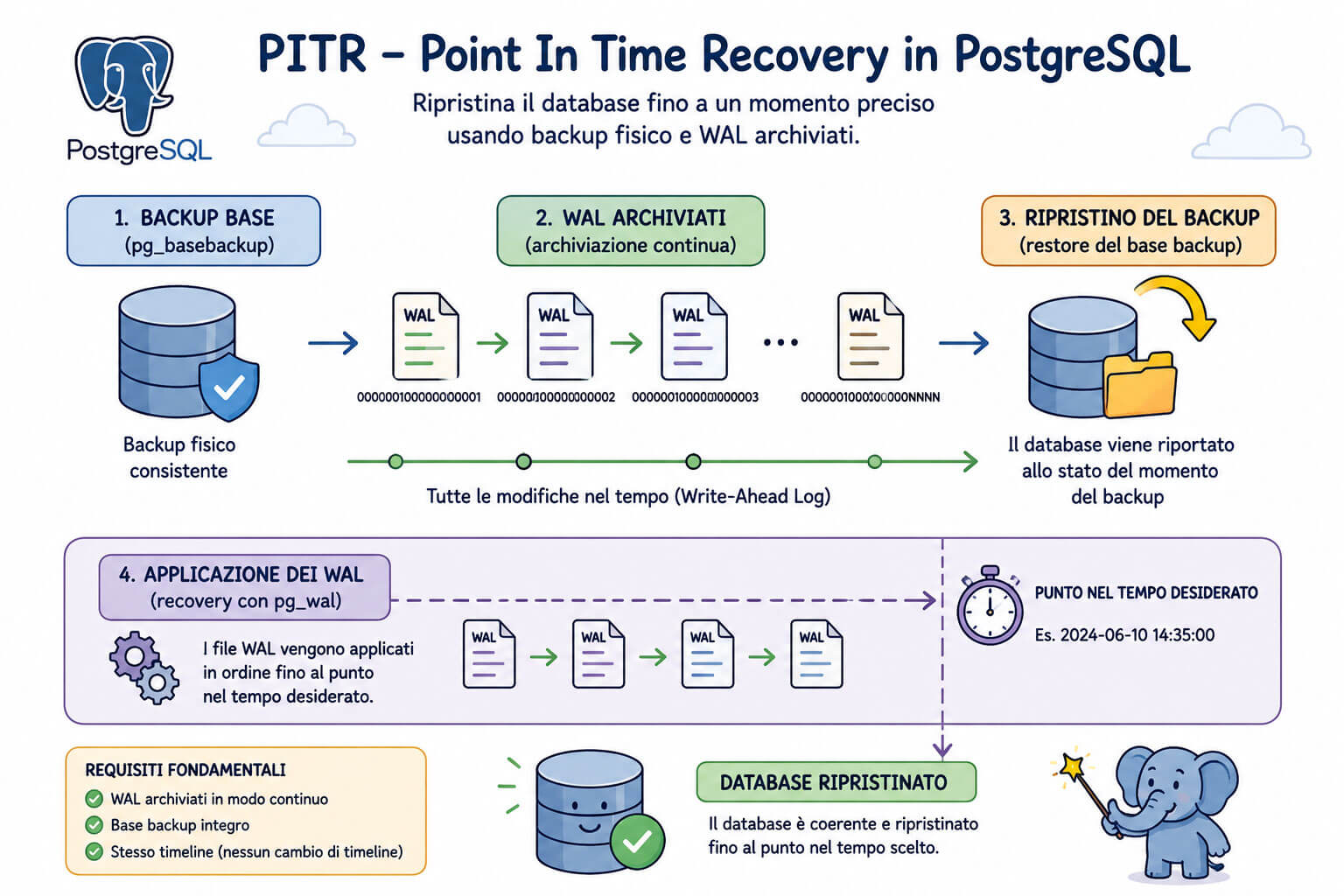
Questa architettura rende PostgreSQL particolarmente adatto ad ambienti in cui l’RPO, Recovery Point Objective, deve essere basso. Se i WAL vengono archiviati correttamente e con continuità, la perdita dati può essere ridotta a pochi secondi o, in alcuni casi, quasi azzerata rispetto al momento dell’ultimo WAL disponibile.
Backup logico e PITR: perché pg_dump non basta
pg_dump e pg_dumpall sono strumenti fondamentali, ma non sono lo strumento giusto per implementare un PITR. Producono backup logici, cioè una rappresentazione SQL degli oggetti e dei dati. Sono utilissimi per migrazioni, esportazioni selettive, ripristini di singoli database o compatibilità tra versioni differenti, ma non contengono le informazioni fisiche necessarie per riapplicare una sequenza di WAL.
Il PITR richiede invece un backup fisico del cluster. Questo può essere ottenuto con pg_basebackup, con strumenti specializzati come pgBackRest o Barman, oppure con procedure di filesystem snapshot correttamente integrate con PostgreSQL. In questo articolo useremo un approccio nativo basato su pg_basebackup e archiviazione WAL, perché permette di comprendere con chiarezza il funzionamento reale del meccanismo.
Componenti necessari
Per eseguire un PITR funzionante servono quattro elementi:
1. Un base backup valido, preso prima del momento al quale vogliamo tornare.
2. L’archiviazione continua dei WAL, configurata prima dell’incidente. Se i WAL non sono stati salvati, non si possono ricostruire le modifiche successive al backup.
3. Un comando di restore dei WAL, cioè il parametro restore_command, che indica a PostgreSQL dove recuperare i segmenti archiviati durante la recovery.
4. Un recovery target, per esempio recovery_target_time, che definisce il punto esatto in cui fermare il replay.
È bene ribadirlo: il PITR non si improvvisa dopo il danno. Deve essere progettato prima, verificato periodicamente e integrato in una strategia di backup coerente. Avere un backup senza WAL archiviati significa poter tornare solo al momento del backup. Avere WAL senza base backup valido significa non avere un punto di partenza consistente.
Abilitare l’archiviazione dei WAL
Il primo passo è configurare PostgreSQL affinché copi ogni segmento WAL completato in una directory di archivio sicura. In un ambiente reale questa directory dovrebbe trovarsi su storage separato, preferibilmente remoto o replicato. Per un esempio didattico useremo una directory locale.
sudo mkdir -p /backup/postgresql/wal_archive sudo chown postgres:postgres /backup/postgresql/wal_archive sudo chmod 700 /backup/postgresql/wal_archive
Nel file postgresql.conf configuriamo i parametri essenziali:
wal_level = replica archive_mode = on archive_command = 'test ! -f /backup/postgresql/wal_archive/%f && cp %p /backup/postgresql/wal_archive/%f' archive_timeout = 300 max_wal_senders = 10
Il parametro archive_mode = on abilita l’archiviazione dei WAL. Il parametro archive_command viene eseguito da PostgreSQL quando un segmento WAL è pronto per essere archiviato. Le variabili %p e %f rappresentano rispettivamente il path del file WAL originale e il nome del file da salvare nell’archivio.
Il comando dell’esempio usa test ! -f per evitare di sovrascrivere un file già presente. Questo è importante: un sistema di archiviazione WAL deve essere conservativo. Se il comando fallisce, PostgreSQL continuerà a ritentare, evitando di perdere il segmento. In produzione si possono usare comandi più sofisticati, come rsync, scp, rclone, aws cli, oppure strumenti dedicati come pgBackRest e Barman.
Dopo la modifica bisogna riavviare PostgreSQL, perché archive_mode richiede restart:
sudo systemctl restart postgresql
È possibile forzare uno switch WAL e verificare che l’archiviazione funzioni:
SELECT pg_switch_wal();
ls -lh /backup/postgresql/wal_archive/
Se nella directory compaiono file con nomi simili a 00000001000000000000000A, l’archiviazione sta funzionando.
Creare un utente per pg_basebackup
pg_basebackup si collega a PostgreSQL tramite il protocollo di replica. Per questo è buona pratica creare un utente dedicato con privilegio REPLICATION:
CREATE ROLE backup_user WITH LOGIN REPLICATION PASSWORD 'PASSWORD_FORTE';
Nel file pg_hba.conf va permessa la connessione di replica, adattando indirizzi e policy di sicurezza al proprio ambiente:
host replication backup_user 127.0.0.1/32 scram-sha-256
Dopo la modifica:
sudo systemctl reload postgresql
Eseguire un base backup fisico
Ora possiamo eseguire un base backup. Supponiamo di voler salvare il backup in /backup/postgresql/base_2026-06-10:
sudo mkdir -p /backup/postgresql/base_2026-06-10 sudo chown postgres:postgres /backup/postgresql/base_2026-06-10 sudo -u postgres pg_basebackup \ -h 127.0.0.1 \ -U backup_user \ -D /backup/postgresql/base_2026-06-10 \ -Fp \ -Xs \ -P
L’opzione -D indica la directory di destinazione. -Fp produce un backup in formato plain, cioè una copia fisica della directory dati. -Xs include lo streaming dei WAL necessari durante il backup. -P mostra l’avanzamento dell’operazione.
Questo backup non è un dump SQL: è una copia fisica del cluster PostgreSQL. Comprende database, cataloghi di sistema, indici, tabelle, configurazioni presenti nella data directory e i file necessari per ripartire. Per questo motivo il restore avviene a livello di cluster, non di singolo database.
Scenario di esempio: cancellazione accidentale
Immaginiamo questo scenario. Alle 02:00 viene eseguito un base backup. Durante la mattina il database lavora normalmente e i WAL vengono archiviati. Alle 14:36:12 un operatore esegue per errore una query dannosa:
DELETE FROM ordini;
L’obiettivo è ripristinare PostgreSQL allo stato immediatamente precedente, per esempio alle 2026-06-10 14:36:00+02. Se abbiamo il base backup delle 02:00 e tutti i WAL generati fino a quell’ora, possiamo effettuare un PITR.
La procedura più sicura è eseguire il restore su un server separato, validare i dati recuperati e solo dopo decidere se sostituire il primario, esportare le tabelle corrette o procedere con una strategia di rientro. Fare PITR direttamente sul server di produzione è possibile, ma aumenta il rischio operativo se non si ha un piano preciso.
Procedura di restore PITR
Prima di tutto fermiamo PostgreSQL sul server di restore o sul server interessato:
sudo systemctl stop postgresql
Il percorso della data directory cambia in base alla distribuzione. Su sistemi Debian e Ubuntu è spesso simile a /var/lib/postgresql/16/main; su sistemi RHEL, AlmaLinux e Rocky Linux è spesso simile a /var/lib/pgsql/16/data. In questo esempio useremo una variabile per rendere i comandi più leggibili:
export PGDATA=/var/lib/pgsql/16/data
Mettiamo al sicuro la directory dati corrente:
sudo mv $PGDATA ${PGDATA}.broken.$(date +%F-%H%M%S)
sudo mkdir -p $PGDATA
sudo chown postgres:postgres $PGDATA
sudo chmod 700 $PGDATA
Ripristiniamo il base backup:
sudo -u postgres rsync -aH --numeric-ids \ /backup/postgresql/base_2026-06-10/ \ $PGDATA/
Ora dobbiamo dire a PostgreSQL di avviarsi in modalità recovery. Dalla versione 12 in poi non si usa più recovery.conf; si crea invece un file vuoto chiamato recovery.signal nella data directory e si configurano i parametri di recovery in postgresql.conf o postgresql.auto.conf.
sudo -u postgres touch $PGDATA/recovery.signal
Aggiungiamo o modifichiamo questi parametri:
restore_command = 'cp /backup/postgresql/wal_archive/%f %p' recovery_target_time = '2026-06-10 14:36:00+02' recovery_target_inclusive = false recovery_target_action = 'pause'
restore_command indica come recuperare ogni WAL archiviato. recovery_target_time è il momento fino al quale vogliamo arrivare. recovery_target_inclusive = false chiede a PostgreSQL di fermarsi prima del target quando applicabile. recovery_target_action = 'pause' è una scelta prudente: quando il target viene raggiunto, PostgreSQL si ferma in recovery e consente di ispezionare i dati prima della promozione definitiva.
Avviamo il servizio:
sudo systemctl start postgresql
Durante l’avvio, PostgreSQL leggerà il backup, userà il backup_label per individuare il punto di partenza del replay, richiamerà il restore_command per recuperare i WAL archiviati e applicherà le modifiche fino al target temporale indicato.
Verificare il risultato
Se abbiamo scelto recovery_target_action = 'pause', il database potrebbe essere disponibile in sola lettura mentre si trova ancora nello stato di recovery. Possiamo controllare lo stato con:
SELECT pg_is_in_recovery();
Possiamo quindi verificare se i dati sono tornati allo stato desiderato:
SELECT count(*) FROM ordini; SELECT max(updated_at) FROM ordini;
Se il contenuto è corretto, possiamo completare la recovery e promuovere l’istanza:
SELECT pg_wal_replay_resume();
In alternativa, se si preferisce far promuovere automaticamente il server al raggiungimento del target, si può usare:
recovery_target_action = 'promote'
In ambienti critici, tuttavia, la pausa è spesso preferibile perché permette una verifica manuale prima di rendere scrivibile il cluster recuperato.
Restore point nominati
PostgreSQL consente anche di creare restore point nominati. Questo è molto utile prima di operazioni rischiose, come aggiornamenti applicativi, migrazioni massive, deploy complessi o interventi manuali sui dati.
SELECT pg_create_restore_point('prima_migrazione_ordini');
In fase di recovery si può poi usare:
restore_command = 'cp /backup/postgresql/wal_archive/%f %p' recovery_target_name = 'prima_migrazione_ordini' recovery_target_action = 'pause'
Questo approccio è più elegante rispetto al solo timestamp quando si conosce in anticipo il momento critico. Il restore point viene registrato nei WAL, quindi richiede comunque che l’archiviazione WAL sia correttamente attiva.
Attenzioni operative
Il PITR di PostgreSQL è potente, ma richiede disciplina. La prima regola è testare periodicamente il restore. Un backup non testato è soltanto una speranza. Bisogna verificare che i base backup siano leggibili, che i WAL siano completi, che il restore_command funzioni e che i tempi di recovery siano compatibili con gli obiettivi aziendali.
La seconda regola è proteggere l’archivio WAL. Se i WAL sono salvati nello stesso disco del database, un guasto storage può compromettere sia i dati primari sia la possibilità di recovery. In produzione è preferibile archiviare su storage remoto, repository dedicato, object storage o server di backup separato.
La terza regola è gestire correttamente le timeline. Dopo un PITR e una promozione, PostgreSQL crea una nuova timeline. Questo significa che la storia del cluster si biforca: da quel momento esiste una nuova sequenza WAL derivata dal punto di recovery. È un comportamento normale, ma va compreso quando si gestiscono repliche, ulteriori recovery o archivi WAL condivisi.
La quarta regola è rimuovere o commentare i parametri di recovery dopo il ripristino, quando non servono più. Dalla versione 12 in avanti il file recovery.signal viene gestito dal processo di recovery, ma i parametri inseriti nei file di configurazione possono rimanere. Lasciarli attivi o dimenticati può generare confusione in successive operazioni di replica o restore.
Strumenti avanzati: pgBackRest e Barman
La procedura descritta in questo articolo usa strumenti nativi per mostrare il funzionamento reale del PITR. In produzione, tuttavia, è spesso consigliabile usare strumenti specializzati. pgBackRest e Barman permettono di gestire backup full, differenziali, incrementali, retention, compressione, verifica, archiviazione WAL, repository remoti e restore point-in-time con un livello di automazione molto superiore.
Questi strumenti non cambiano il principio di base: il PITR resta sempre fondato su base backup e WAL replay. Rendono però più robusta e ripetibile l’operatività quotidiana, riducendo il rischio di errore umano. Per aziende che gestiscono PostgreSQL in produzione, e-commerce, gestionali, CRM o piattaforme mission critical, affidarsi a una soluzione strutturata è quasi sempre preferibile rispetto a script artigianali non monitorati.
Conclusione
Il Point In Time Recovery in PostgreSQL è una delle funzionalità più importanti per garantire continuità operativa e protezione reale del dato. A differenza di un semplice dump logico, permette di ricostruire l’intero cluster fino a un momento preciso, sfruttando la combinazione tra base backup fisico e archiviazione continua dei WAL.
La procedura può essere riassunta in pochi passaggi: abilitare l’archiviazione WAL, eseguire periodicamente base backup consistenti, conservare i WAL in modo sicuro, ripristinare il backup quando necessario, creare recovery.signal, configurare restore_command e impostare il recovery target desiderato. Da quel momento PostgreSQL rilegge la propria storia transazionale e si ferma nel punto stabilito.
Il valore del PITR non si misura solo nel momento del disastro, ma nella preparazione precedente. Senza WAL archiviati, senza test di restore e senza procedure documentate, il PITR rimane una teoria. Con una corretta implementazione, invece, diventa uno degli strumenti più efficaci per ridurre la perdita dati e affrontare con metodo cancellazioni accidentali, bug applicativi, migrazioni sbagliate e incidenti operativi.
Per chi gestisce PostgreSQL in produzione, il messaggio è semplice: non basta chiedersi se esiste un backup. Bisogna chiedersi fino a quale momento si è davvero in grado di tornare, in quanto tempo e con quale livello di certezza. Il PITR serve esattamente a questo: trasformare il backup da semplice copia passiva a vera strategia di recovery controllata.