
Indice dei contenuti dell'articolo:
Il comunicato stampa e il provvedimento pubblicati ad aprile 2026 non lasciano spazio a interpretazioni particolarmente elastiche. Il principio è netto: il tracciamento non può più avvenire in modo silenzioso, implicito o predefinito. Anche strumenti apparentemente innocui, come i pixel di tracciamento inseriti nelle email, rientrano pienamente nel perimetro delle tecnologie che richiedono un consenso preventivo, libero, specifico e informato.
Per chi lavora nel digitale, non è una sorpresa. Ma è l’ennesima conferma che il margine di manovra per il marketing data-driven si sta restringendo in modo progressivo, costante e, soprattutto, irreversibile.
Il pixel invisibile che non è più così innocuo
Per anni, i tracking pixel sono stati una componente standard dell’email marketing. Invisibili all’utente, semplici da implementare, estremamente efficaci. Permettevano di sapere se un’email veniva aperta, quando, da quale dispositivo e spesso anche da quale area geografica. Informazioni fondamentali per ottimizzare campagne, segmentare il pubblico, migliorare conversioni.
Ma il loro utilizzo non si fermava alla semplice misurazione delle aperture. In molti casi, quei dati venivano incrociati con altri segnali: cronologia degli acquisti, comportamento sul sito, interazioni precedenti con altre comunicazioni. Il pixel diventava così un tassello all’interno di un sistema più ampio, capace di costruire profili sempre più dettagliati nel tempo. Anche una singola apertura di email, apparentemente innocua, contribuiva ad alimentare un modello predittivo: chi è attivo, chi è inattivo, chi è vicino all’acquisto, chi sta per abbandonare.
Dal punto di vista tecnico, il meccanismo è banale quanto efficace: il caricamento di un’immagine remota genera una richiesta HTTP verso un server, e quella richiesta porta con sé una serie di metadati — indirizzo IP, user agent, timestamp — che possono essere raccolti, archiviati e analizzati. Non serve codice eseguito lato utente, non serve interazione esplicita. Basta aprire l’email.
![]()
Ed è proprio questa asimmetria, secondo il Garante per la protezione dei dati personali, a rappresentare il nodo centrale del problema. L’utente medio non ha strumenti concreti per accorgersi di questo tipo di tracciamento, né per comprenderne la portata. Non esiste un indicatore visivo chiaro, non esiste un’interfaccia che renda evidente cosa sta accadendo nel momento in cui l’email viene aperta. Tutto avviene in background, senza frizione, senza consapevolezza.
In questo contesto, parlare di consenso implicito o di legittimo interesse diventa estremamente fragile. Se manca la percezione stessa del trattamento, manca anche la possibilità di esercitare un controllo reale. Ed è qui che il Garante interviene, ribaltando un’impostazione che per anni è stata considerata prassi consolidata.
Questo implica, nella pratica, un cambio anche nel modo in cui le aziende progettano le proprie comunicazioni. Il tracciamento non può più essere un layer nascosto, integrato automaticamente in ogni invio. Deve diventare una scelta opzionale, separata, documentata. L’informativa non può limitarsi a formule generiche: deve descrivere in modo comprensibile il tipo di dati raccolti, le finalità, le eventuali conseguenze.
Dal punto di vista giuridico, la posizione è coerente con l’impianto del GDPR, che pone al centro trasparenza e autodeterminazione informativa. Dal punto di vista operativo, rappresenta un ulteriore elemento di frizione in un sistema già sotto pressione, perché introduce complessità dove prima c’era automatismo, e richiede esplicitazione dove prima bastava l’implicito.
Una direzione già tracciata da tempo
Questo intervento non arriva in un vuoto normativo. È l’ultimo tassello di un percorso iniziato ben prima, costruito attraverso una stratificazione progressiva di provvedimenti che, nel tempo, hanno ridefinito in modo sostanziale il perimetro della profilazione digitale.
Negli anni, il Garante per la protezione dei dati personali ha agito con una certa coerenza, intervenendo su più livelli. In una prima fase, l’attenzione si è concentrata su strumenti evidenti come i cookie, imponendo obblighi di informativa e consenso che hanno trasformato radicalmente l’esperienza di navigazione. Le linee guida del 2021, in particolare, hanno segnato uno spartiacque: via i banner ambigui o preconfigurati, dentro meccanismi più granulari, con la possibilità per l’utente di accettare, rifiutare o selezionare in modo puntuale le diverse categorie di trattamento.
Ma il punto non era il banner in sé. Il banner è sempre stato solo la manifestazione visibile di un problema più profondo: la raccolta sistematica e spesso indiscriminata di dati a fini di profilazione.

Già nei provvedimenti precedenti, il Garante aveva chiarito che la profilazione non può essere considerata un’attività accessoria o implicitamente accettata. Al contrario, richiede una base giuridica solida, fondata su un consenso che deve essere libero, specifico e soprattutto revocabile senza ostacoli. Non solo: deve essere anche separato da altre finalità, evitando quella commistione tipica tra erogazione del servizio e utilizzo dei dati per scopi ulteriori.
Nel tempo, questa impostazione ha portato a restringere progressivamente gli spazi operativi per chi basa il proprio modello su una raccolta estensiva di informazioni comportamentali. Non con interventi improvvisi o isolati, ma attraverso una sequenza di aggiustamenti che hanno via via eliminato le zone grigie.
Il filo conduttore è sempre stato lo stesso: ridurre l’asimmetria informativa tra chi raccoglie dati e chi li genera. In altri termini, riequilibrare un rapporto che, per sua natura, tende a essere sbilanciato. Da una parte, soggetti con capacità tecnologiche avanzate e piena visibilità sui processi di raccolta e analisi; dall’altra, utenti che spesso non dispongono né degli strumenti né delle competenze per comprendere realmente cosa accade ai propri dati.
L’intervento sui tracking pixel si inserisce perfettamente in questa logica. Non introduce un principio nuovo, ma estende principi già consolidati a un ambito che, fino a oggi, era rimasto relativamente meno regolato rispetto ad altri.
Il ruolo di Apple e la fine dell’era del tracking facile
L’introduzione delle funzionalità di App Tracking Transparency da parte di Apple, resa effettiva su larga scala con il rilascio di iOS 14.5 nell’aprile 2021, ha avuto un impatto che, per certi versi, è stato ancora più immediato e tangibile di qualsiasi provvedimento normativo.
Con una semplice richiesta di autorizzazione mostrata all’utente — un pop-up chiaro, diretto, difficilmente aggirabile — Apple ha trasformato il tracciamento da un meccanismo implicito e silenzioso a una scelta esplicita. Un passaggio apparentemente banale, ma con conseguenze profonde: nel momento in cui agli utenti viene data la possibilità reale di scegliere, la maggioranza sceglie di non essere tracciata.
Questo ha prodotto un effetto immediato sulla disponibilità di dati. L’accesso all’IDFA, che per anni ha rappresentato uno degli strumenti principali per il tracciamento cross-app nel mondo mobile, è diventato drasticamente limitato. Di colpo, intere strategie di targeting basate sulla ricostruzione del comportamento dell’utente tra diverse applicazioni hanno perso affidabilità.
Ma l’impatto non si è fermato al mondo delle app. Con l’introduzione di Mail Privacy Protection — arrivata poco dopo, con iOS 15 nel settembre 2021 — Apple ha esteso questa logica anche all’email, andando a colpire uno dei canali più consolidati del marketing digitale. Il meccanismo è tanto semplice quanto efficace: il caricamento preventivo e anonimo delle immagini remote impedisce di determinare con certezza se, quando e da chi un’email sia stata effettivamente aperta.
Il risultato è che metriche storicamente centrali, come l’open rate, hanno perso gran parte del loro significato operativo. Non perché siano sparite, ma perché non sono più affidabili. Un’email può risultare “aperta” anche senza che l’utente l’abbia mai visualizzata, oppure può non generare segnali utili per una segmentazione precisa.
Per chi costruiva campagne basandosi su queste informazioni, si è trattato di un cambiamento sostanziale. Non tanto per la perdita di un singolo dato, ma per la riduzione complessiva della visibilità sul comportamento dell’utente.
In questo senso, Apple ha agito come un acceleratore. Ha reso concreta, su larga scala, una trasformazione che a livello normativo era già in atto ma procedeva con tempi più graduali. Ha dimostrato, soprattutto, che è possibile modificare in modo drastico le regole del gioco semplicemente intervenendo sul punto di accesso principale tra utente e servizio.
Meno dati, meno precisione
A questo punto, il passaggio logico è inevitabile. Se si riduce la quantità e la qualità dei dati disponibili, si riduce anche la capacità di fare targeting preciso.
La profilazione, al netto delle implicazioni normative, ha sempre avuto una funzione molto concreta: identificare con maggiore accuratezza la buyer persona, ovvero quel sottoinsieme di utenti che ha una reale probabilità di interesse, interazione e acquisto. Non si tratta solo di “sapere qualcosa in più”, ma di costruire un contesto decisionale basato su segnali comportamentali: aperture email, click, tempo di permanenza, storico acquisti, frequenza di interazione.
Questi dati permettono di affinare progressivamente il pubblico, escludendo chi non è rilevante e concentrando il budget su chi lo è. In altre parole, consentono di evitare di sparare nel mucchio.
Quando questo meccanismo funziona, il beneficio è duplice. Da un lato, l’utente riceve comunicazioni più pertinenti, meno invasive, teoricamente più utili. Dall’altro, l’azienda ottimizza i costi: meno dispersione, meno impression inutili, più probabilità di conversione per ogni euro speso.
È qui che entra in gioco il concetto di efficienza. Un sistema di profilazione efficace non aumenta solo le vendite, ma riduce il costo per lead e il costo per acquisizione, perché ogni azione è guidata da una probabilità più alta di successo.
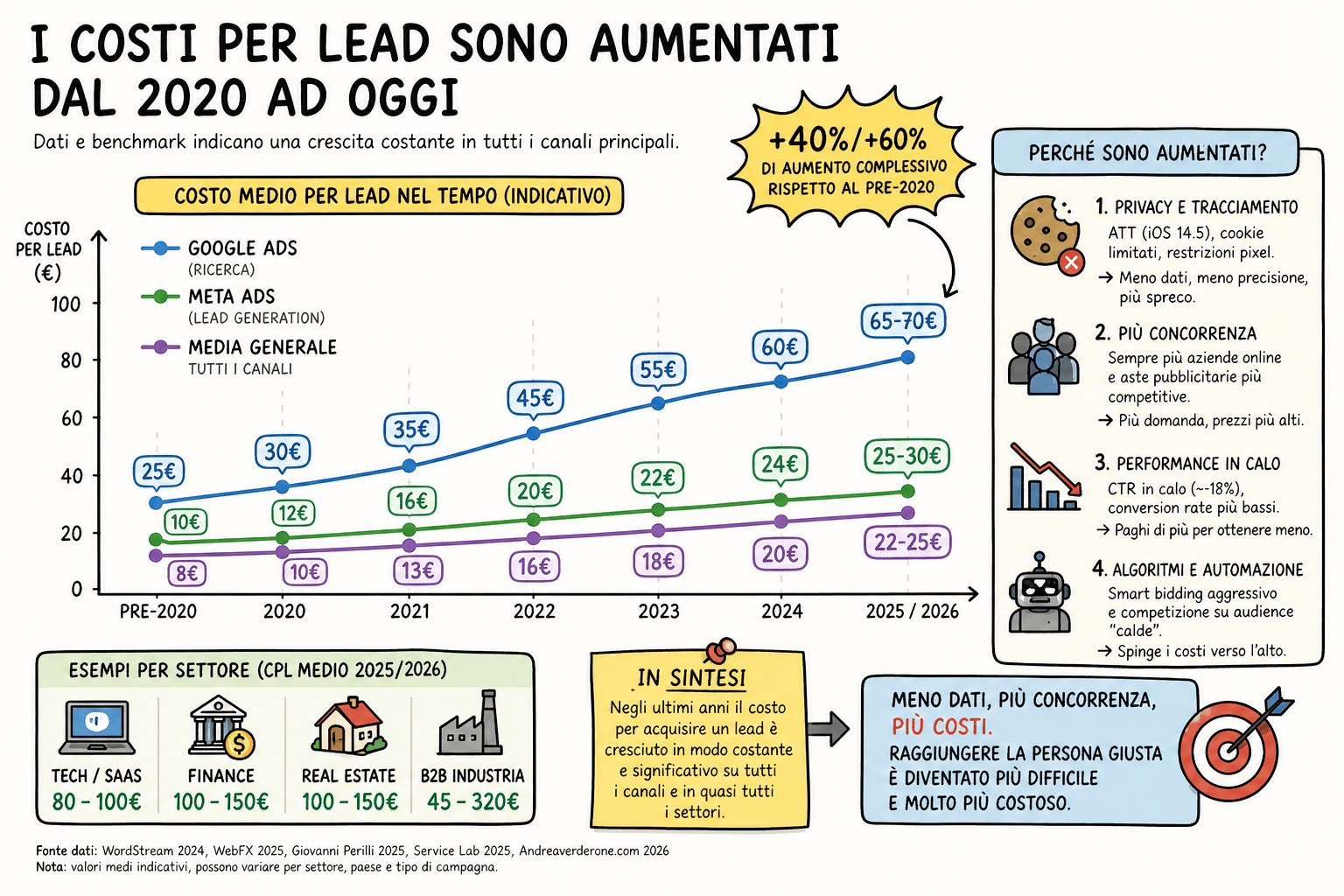
Quando però i dati vengono meno — o diventano incompleti, ritardati, inaffidabili — questo livello di precisione si deteriora rapidamente.
E quando il targeting diventa meno preciso, il marketing diventa meno efficiente.
Non è una valutazione ideologica. È una relazione quasi meccanica.
Se non posso più identificare con sufficiente affidabilità chi è interessato a un prodotto, sono costretto ad ampliare il pubblico di riferimento. Ampliare il pubblico significa includere una quota crescente di utenti non interessati. E includere utenti non interessati significa aumentare il numero di impression necessarie per ottenere lo stesso risultato.
In termini pratici, si traduce in questo: più traffico per generare lo stesso numero di lead, più lead per ottenere lo stesso numero di clienti.
Il risultato è un aumento diretto del costo per lead e, a cascata, del costo di acquisizione cliente. Non perché il mercato sia cambiato improvvisamente, ma perché è cambiata la capacità di selezionarlo.
Il punto critico: l’aumento dei costi per lead non è proporzionale
Qui si inserisce un aspetto spesso sottovalutato nel dibattito pubblico. L’aumento dei costi pubblicitari non si distribuisce in modo proporzionale rispetto al valore del prodotto.
È un aumento in larga parte assoluto, non percentuale.
Questo significa che l’incremento del costo per acquisire un cliente tende ad essere simile in termini nominali, indipendentemente dal prezzo del prodotto venduto. Ma l’impatto di quell’aumento è completamente diverso a seconda del contesto.
Su un prodotto da 2.000 euro, un incremento di 10 euro nel costo di acquisizione è quasi irrilevante. Rientra nelle normali oscillazioni di mercato, può essere compensato con piccole ottimizzazioni o semplicemente assorbito nel margine. In molti casi, non modifica in modo significativo la sostenibilità complessiva del modello.
Su un prodotto da 20 euro, lo stesso incremento cambia completamente l’equazione.
Perché lì il margine è strutturalmente più basso, spesso già compresso da costi logistici, commissioni, resi, gestione operativa. In quel contesto, il costo pubblicitario non è una variabile accessoria: è una componente critica.
Dieci anni fa, per vendere online un prodotto a basso prezzo, potevano bastare 2 euro di advertising. Il modello funzionava proprio perché il costo di acquisizione era allineato al valore del carrello medio. C’era spazio per margine, per reinvestimento, per scalabilità.
Oggi, in molti casi, ne servono 8 o 10. Non perché il prodotto sia peggiorato o meno competitivo, ma perché raggiungere la persona giusta è diventato più difficile, più dispersivo, meno prevedibile. La perdita di precisione nel targeting si traduce direttamente in più tentativi necessari per ottenere lo stesso risultato.
A quel punto, il margine semplicemente scompare.
Non si tratta di guadagnare meno. Non è una questione di riduzione della redditività. È un passaggio più radicale: il modello smette di stare in piedi.
Quando il costo per acquisire un cliente si avvicina o supera il margine generato dalla vendita, non c’è ottimizzazione che tenga. Non è un problema di efficienza operativa o di strategia creativa. È un problema strutturale.
E quando il problema è strutturale, la conseguenza è una sola: quel prodotto, a quelle condizioni, non è più vendibile online.
Quando un prodotto smette di essere vendibile
Quando il costo di acquisizione supera una certa soglia, il problema non è più l’ottimizzazione. È la sostenibilità.
Finché il costo resta entro margini gestibili, si può intervenire: migliorare le creatività, ottimizzare le landing page, lavorare sul funnel, testare nuovi segmenti. Ma quando il costo per acquisire un cliente si allinea o supera il margine generato da quella vendita, ogni tentativo di ottimizzazione diventa marginale. Non è più un problema di performance, è un problema di modello.
In quel momento il prodotto esce dal mercato. Non in modo graduale, non con un lento ridimensionamento, ma spesso con uno stop netto. Le campagne vengono spente, gli investimenti interrotti, la distribuzione online semplicemente non è più giustificabile.
E quando esce dal mercato un prodotto, non si ferma solo il venditore.
Si ferma la filiera.
Il primo impatto è visibile sull’e-commerce che smette di vendere, ma a cascata si propagano effetti su tutti gli attori coinvolti. I fornitori vedono ridursi gli ordini. I distributori perdono volumi. Le piattaforme e-commerce registrano un calo di transazioni. Gli operatori logistici movimentano meno merce. Le agenzie marketing perdono budget e clienti. Gli sviluppatori vedono ridursi la domanda di nuove funzionalità e ottimizzazioni.
È un sistema interconnesso, costruito negli anni proprio sulla base di un presupposto: la possibilità di raggiungere in modo relativamente efficiente una domanda latente attraverso il digitale. Quando quel presupposto viene meno, non si rompe un singolo ingranaggio, ma si riduce la velocità dell’intero meccanismo.
Ridurre l’efficienza di quel sistema non significa semplicemente spendere di più per ottenere lo stesso risultato. Significa, in molti casi, ridurre il numero stesso di operazioni economicamente sostenibili. E quando questo accade su larga scala, le conseguenze vanno ben oltre il singolo annuncio pubblicitario o la singola campagna: incidono sulla struttura complessiva del mercato.
Il rischio di una concentrazione ulteriore
Un altro effetto collaterale, meno visibile ma potenzialmente più rilevante, riguarda la struttura del mercato.
Le grandi piattaforme dispongono di enormi quantità di dati di prima parte. Non si tratta solo di volume, ma di qualità e continuità: dati raccolti lungo tutto il ciclo di vita dell’utente, all’interno di ambienti controllati, dove ogni interazione — ricerca, acquisto, visualizzazione, permanenza — contribuisce ad arricchire un profilo già esistente. In questi contesti, il tracciamento non è percepito come qualcosa di esterno o aggiuntivo, ma come parte integrante del servizio.
Questo significa che la dipendenza da tecnologie di tracciamento di terze parti è molto più bassa. Anche in presenza di restrizioni normative o tecniche, queste piattaforme mantengono una capacità di profilazione elevata, perché il dato nasce e resta all’interno del loro ecosistema.
Per un piccolo o medio operatore, la situazione è radicalmente diversa.
Chi non possiede una base utenti ampia e consolidata, chi non gestisce direttamente piattaforme con elevato traffico o frequenza di interazione, ha storicamente fatto affidamento su strumenti esterni per colmare questo gap: pixel, cookie, sistemi di tracciamento che permettevano di costruire nel tempo una conoscenza progressiva del proprio pubblico.
Quando questi strumenti vengono limitati o resi meno efficaci, quel divario si amplia.
Non perché i piccoli operatori facciano qualcosa di diverso, ma perché partono da una posizione strutturalmente più debole. Hanno meno dati, meno touchpoint, meno possibilità di osservare il comportamento dell’utente nel tempo. E senza dati, la capacità di competere sul piano del marketing si riduce drasticamente.
Il risultato è una progressiva concentrazione.
Non immediata, non dichiarata, ma graduale. Meno attori in grado di sostenere campagne efficaci, meno operatori capaci di ottimizzare i costi di acquisizione, meno realtà che riescono a scalare.
Nel frattempo, chi controlla piattaforme e dati rafforza la propria posizione. Non necessariamente perché aumenti la qualità del servizio, ma perché dispone degli strumenti per continuare a operare in un contesto dove altri li stanno perdendo.
È un effetto noto, in parte previsto, ma raramente discusso con la stessa enfasi riservata alla tutela della privacy. Perché si manifesta in modo meno evidente, più lento, ma incide in profondità sugli equilibri competitivi del mercato digitale.
Il paradosso del tracciamento che non scompare
C’è poi un’ultima considerazione, più tecnica ma non meno rilevante.
Limitare il tracciamento esplicito non significa necessariamente eliminarlo. In molti casi significa spingerlo verso forme meno visibili, meno trasparenti, più difficili da controllare e, soprattutto, più difficili da spiegare all’utente medio.
Quando strumenti dichiarati e relativamente semplici come cookie e pixel vengono limitati, il sistema non si ferma. Si adatta. E l’adattamento, spesso, passa attraverso tecniche che operano a un livello più basso dello stack tecnologico, meno accessibile e meno intuitivo.
Il fingerprinting, ad esempio, non si basa su un identificatore salvato lato utente, ma sulla combinazione di caratteristiche del dispositivo e del browser: risoluzione dello schermo, font installati, configurazioni di sistema, comportamento di rendering. Presi singolarmente, questi elementi non identificano nessuno. Combinati, possono generare un’impronta sufficientemente unica da riconoscere un utente nel tempo.
Il tracking probabilistico segue una logica diversa, ma con lo stesso obiettivo. Non cerca una corrispondenza certa, ma una correlazione statistica: più segnali deboli messi insieme per stimare con una certa probabilità che due sessioni appartengano allo stesso soggetto. Non è deterministico, ma spesso è “abbastanza preciso” da risultare utile.
Anche l’analisi comportamentale aggregata si inserisce in questo contesto. In assenza di identificatori diretti, si osservano pattern di comportamento: sequenze di azioni, tempi di interazione, percorsi di navigazione. Non si identifica formalmente l’utente, ma si costruiscono modelli che permettono comunque di segmentare e prevedere.
Il punto è che queste tecniche non nascono nel vuoto. Emergono proprio come risposta alle restrizioni normative e tecnologiche sui metodi più espliciti di tracciamento. Dove un approccio viene limitato, un altro tende a prenderne il posto.
Il rischio, quindi, è quello di sostituire un sistema imperfetto ma relativamente trasparente — perché almeno dichiarato, documentato, in qualche misura controllabile — con uno più complesso e opaco, dove il confine tra ciò che è lecito e ciò che non lo è diventa meno immediato da comprendere.
E a quel punto, la domanda diventa inevitabile: il livello di controllo dell’utente aumenta davvero, oppure si sposta semplicemente su un piano meno visibile, dove la comprensione richiede competenze tecniche che la maggior parte degli utenti non possiede?
Più privacy, meno efficienza: un equilibrio difficile
Il ruolo del Garante per la protezione dei dati personali è chiaro e, sul piano dei principi, difficilmente contestabile. Proteggere i diritti fondamentali dei cittadini, tra cui la riservatezza dei dati personali, è parte integrante dell’architettura giuridica europea.
Le nuove limitazioni sul tracciamento via pixel si inseriscono perfettamente in questo quadro. Non rappresentano un’anomalia, ma una naturale estensione di principi già consolidati: trasparenza, consenso, minimizzazione del dato, controllo da parte dell’interessato. Da questo punto di vista, la direzione è lineare.
Il problema è che il sistema su cui queste regole si innestano non è neutro.
Il web commerciale degli ultimi vent’anni si è sviluppato su un presupposto implicito: la possibilità di raccogliere, analizzare e utilizzare dati comportamentali per migliorare l’efficacia delle attività di marketing. Non come elemento accessorio, ma come componente strutturale. Interi modelli di business sono stati costruiti su questa base, ottimizzando progressivamente ogni passaggio del funnel grazie alla disponibilità di informazioni sempre più granulari.
Intervenire su questo meccanismo non significa semplicemente “correggere” alcune pratiche. Significa modificare uno degli ingranaggi centrali del sistema.
Ed è qui che emergono gli effetti collaterali. Non teorici, ma economici, concreti, misurabili nel breve periodo.
Aumentano i costi, perché per ottenere lo stesso risultato servono più risorse. Diminuisce l’efficienza, perché si perde precisione nella selezione del pubblico. Cambiano gli equilibri di mercato, perché non tutti gli operatori sono colpiti allo stesso modo da queste trasformazioni.
Il punto non è negare la necessità di maggiore tutela, né mettere in discussione il diritto alla privacy. Il punto è riconoscere che esiste una tensione reale tra questi principi e il funzionamento attuale dell’economia digitale.
Una tensione che, almeno per ora, non sembra avere una sintesi semplice.
Interrogarsi su quanto il sistema economico digitale sia compatibile con un modello di privacy sempre più restrittivo non significa prendere posizione contro la tutela dei dati. Significa, piuttosto, chiedersi se il modello attuale sia destinato ad adattarsi, a trasformarsi o, in alcuni casi, a non reggere più sotto il peso di queste nuove condizioni.
Come essere conformi alle nuove direttive ?
Alla luce del recente intervento del Garante per la protezione dei dati personali sui sistemi di tracciamento nelle email, la conformità non può più essere trattata come un adempimento formale o documentale. Richiede, al contrario, un ripensamento tecnico e operativo di come vengono progettate, inviate e monitorate le comunicazioni.
Il primo punto è eliminare ogni forma di tracciamento implicito. L’inserimento automatico di pixel all’interno delle email, senza una base giuridica solida, non è più sostenibile. Se si intende continuare a utilizzare strumenti di monitoraggio delle aperture o delle interazioni, è necessario raccogliere un consenso preventivo, libero e specifico. Questo implica separare chiaramente la finalità di invio della comunicazione dalla finalità di analisi comportamentale.
Dal punto di vista tecnico, significa implementare un sistema di gestione del consenso che operi a monte dell’invio. Non è sufficiente inserire una clausola generica nell’informativa: occorre poter dimostrare che l’utente ha espresso una volontà esplicita rispetto al tracciamento. In assenza di tale consenso, le email devono essere inviate in modalità “no tracking”, evitando il caricamento di risorse remote utilizzate per finalità di monitoraggio.
Un secondo aspetto riguarda la trasparenza. L’informativa deve descrivere in modo chiaro e comprensibile quali dati vengono raccolti attraverso il pixel, con quali finalità e per quanto tempo vengono conservati. È necessario evitare formulazioni vaghe o eccessivamente tecniche, che non consentano all’utente di comprendere realmente l’impatto del trattamento.
Va poi garantita la possibilità di revoca. L’utente deve poter modificare in qualsiasi momento le proprie preferenze, con la stessa semplicità con cui le ha espresse. Questo implica mantenere un sistema aggiornato di gestione delle preferenze e assicurarsi che le modifiche vengano propagate in modo coerente su tutti i sistemi di invio e tracciamento.
Dal punto di vista infrastrutturale, è opportuno distinguere tra componenti necessarie all’erogazione del servizio e componenti utilizzate per finalità di analisi o profilazione. Questo principio di separazione, coerente con il concetto di “privacy by design”, aiuta a ridurre il rischio di trattamenti eccedenti rispetto alle finalità dichiarate.
Infine, è fondamentale documentare le scelte effettuate. Registro dei trattamenti, valutazioni d’impatto (DPIA, se necessarie), configurazioni tecniche e logiche di funzionamento devono essere tracciabili e verificabili. Non solo per finalità di audit, ma per dimostrare concretamente l’adozione di un approccio conforme.
In sintesi, la conformità alle nuove direttive non si ottiene semplicemente “disattivando un pixel”, ma ripensando l’intero flusso di raccolta e utilizzo dei dati. Il tracciamento, da elemento standard e invisibile, diventa una funzionalità opzionale, subordinata a una scelta consapevole dell’utente e gestita con strumenti tecnici adeguati.
La domanda che resta aperta
Alla fine, la questione non è se sia giusto o sbagliato limitare il tracciamento.
La questione è se siamo pronti ad accettarne le conseguenze.
Perché la privacy ha un costo. E quel costo non si dissolve, non viene assorbito da un’entità astratta. Si redistribuisce lungo tutta la catena del valore, in modo spesso silenzioso ma inevitabile.
Una parte ricade sulle aziende, sotto forma di margini compressi, minore prevedibilità, maggiore difficoltà nel pianificare investimenti. Una parte si trasferisce sui consumatori, attraverso prezzi più alti o una riduzione dell’offerta disponibile. Un’altra parte, meno visibile ma forse più significativa, si traduce in attività che semplicemente smettono di esistere perché non più sostenibili.
Non è un processo immediato, né uniforme. È graduale, frammentato, ma cumulativo.
Il provvedimento del Garante per la protezione dei dati personali rappresenta un ulteriore passo in una direzione precisa: più controllo per l’utente, meno libertà per il tracciamento. Una direzione che, nel contesto normativo europeo, appare ormai consolidata.
La domanda, però, resta aperta sul piano economico.
Questo equilibrio è sostenibile nel lungo periodo? Il sistema riuscirà ad adattarsi trovando nuove forme di efficienza, oppure assisteremo a una progressiva contrazione di alcune dinamiche che hanno caratterizzato la crescita del digitale negli ultimi vent’anni?
E ancora: il valore generato da una maggiore tutela della privacy sarà percepito come sufficiente a compensare i costi indiretti che si manifestano altrove?
Nel tentativo di costruire un ecosistema più rispettoso dei diritti individuali, si rischia — almeno in parte — di erodere quella base economica che ha reso possibile la diffusione capillare di servizi, prodotti e modelli accessibili.
È una domanda scomoda, perché non offre risposte semplici e mette in tensione due esigenze entrambe legittime.
Ma è una domanda che diventa sempre più difficile ignorare, man mano che gli effetti di queste trasformazioni si rendono visibili nel funzionamento quotidiano del mercato digitale.