
Indice dei contenuti dell'articolo:
Quando si parla di performance web, spesso l’attenzione si concentra su cache full page, CDN, compressione Brotli, immagini ottimizzate e alleggerimento del frontend. Tutti aspetti importanti, senza dubbio. Esiste però un elemento molto meno appariscente, ma estremamente utile, che può contribuire in modo concreto sia al miglioramento del TTFB sia all’ottimizzazione del crawling budget: il codice di stato HTTP 304 Not Modified.
Il 304 è uno di quei meccanismi che lavorano in silenzio. Non produce una pagina più bella, non cambia il layout, non aggiunge funzionalità visibili all’utente finale. Eppure consente di evitare trasferimenti inutili, ridurre il carico su server e rete, migliorare la rapidità percepita e rendere più efficiente il lavoro dei crawler. In un contesto in cui ogni millisecondo conta e ogni spreco di risorse può trasformarsi in un collo di bottiglia, il corretto utilizzo delle conditional requests diventa un tassello importante di una strategia di ottimizzazione seria.
Capire come funziona davvero il 304, quando viene restituito, quali header lo governano e in che modo incide su browser, proxy, CDN e bot dei motori di ricerca è fondamentale per chi gestisce siti ad alto traffico, e-commerce, portali editoriali o qualunque progetto in cui le prestazioni e la scansione abbiano un impatto diretto sul business.
Cos’è il codice HTTP 304 Not Modified
Il codice 304 Not Modified indica che la risorsa richiesta dal client non è cambiata rispetto alla versione già presente nella cache locale del richiedente. In altre parole, il browser o il crawler chiedono al server: “Questa risorsa è cambiata dall’ultima volta che l’ho scaricata?”. Se la risposta è no, il server non reinvia il contenuto completo, ma restituisce solo l’intestazione con stato 304.
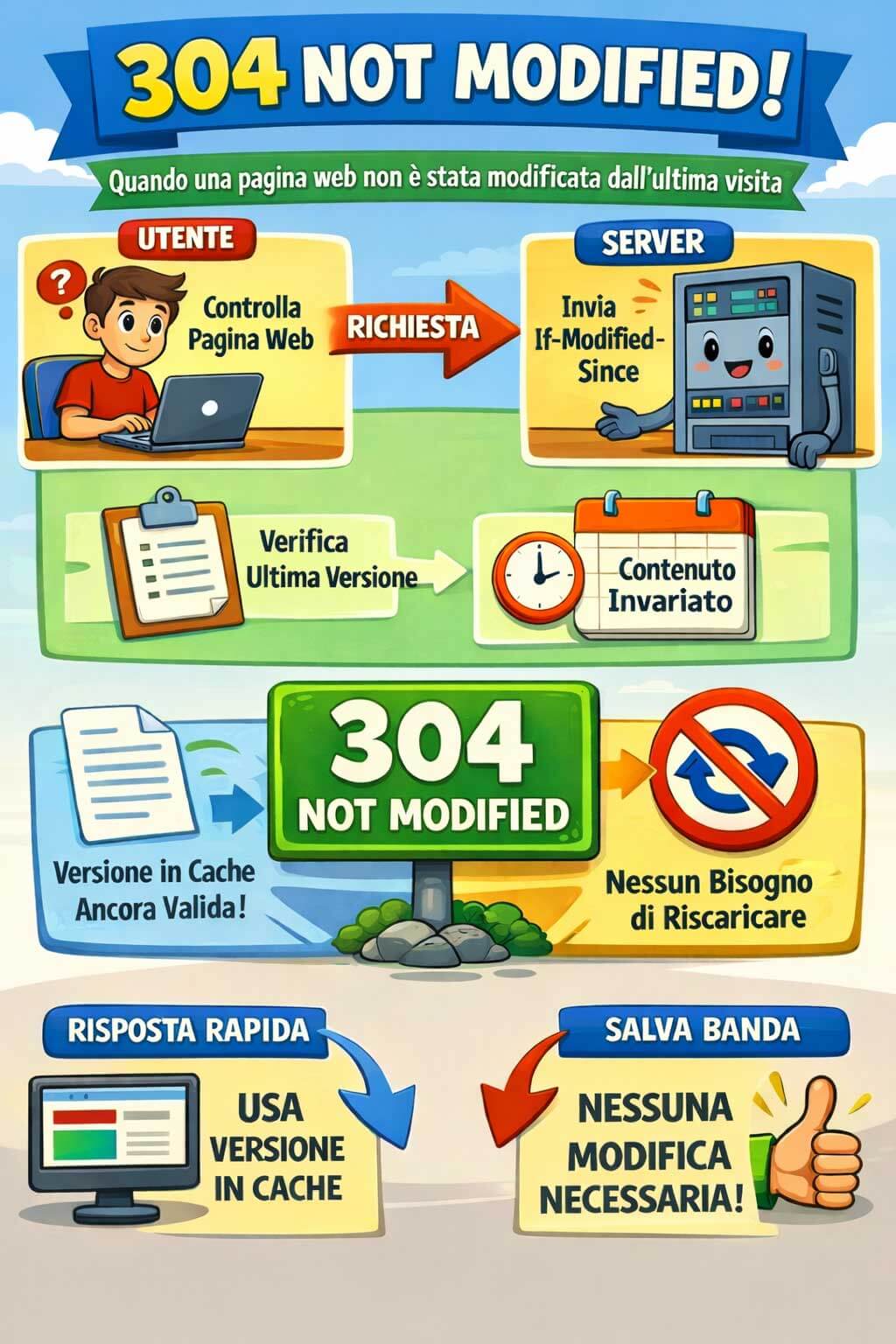
È importante chiarire un punto: il 304 non è una risposta cache arbitraria, ma il risultato di una richiesta condizionale. Il client invia una richiesta con header come If-Modified-Since oppure If-None-Match, e il server confronta questi valori con lo stato corrente della risorsa. Se la risorsa non è stata modificata, risponde con 304; se invece è cambiata, risponde normalmente con 200 OK e invia il nuovo contenuto.
Questo meccanismo è particolarmente efficiente perché evita di trasferire nuovamente HTML, CSS, JavaScript, immagini, font o altri asset che il client possiede già. Il vantaggio non è solo in termini di banda. C’è anche una riduzione del lavoro lato server e, in molti casi, un miglioramento del tempo necessario per chiudere la richiesta.
Perché il 304 può migliorare il TTFB
Il TTFB, Time To First Byte, misura il tempo che intercorre tra l’invio della richiesta e la ricezione del primo byte della risposta. È una metrica che riflette diversi fattori: latenza di rete, elaborazione lato server, accesso a database, eventuale passaggio tramite proxy o CDN e capacità del sistema di servire contenuti rapidamente.
Quando una risorsa può essere validata con una richiesta condizionale e chiusa con un 304 Not Modified, il server non deve ricostruire l’intero payload da inviare. In molti scenari non deve nemmeno eseguire tutte le stesse operazioni richieste per un 200 completo. Se la logica di validazione è implementata bene, il controllo di ETag o Last-Modified risulta molto più economico rispetto alla generazione e consegna dell’intera risorsa.
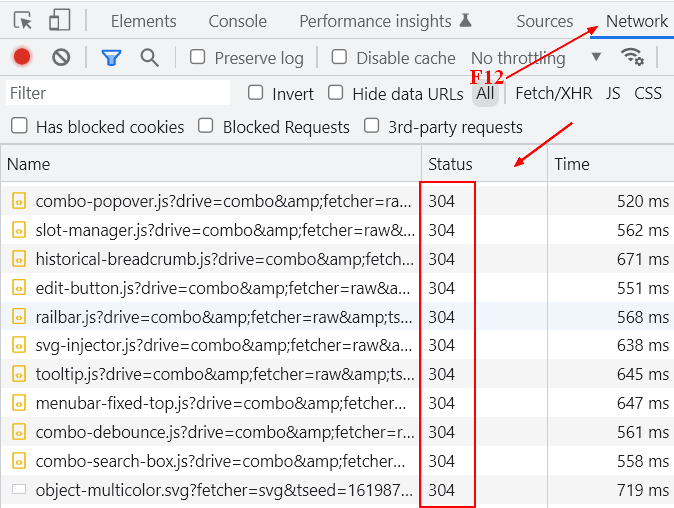
Per asset statici il vantaggio è evidente. Invece di rispedire un file CSS da centinaia di kilobyte o un’immagine, il server restituisce solo una risposta leggera, con intestazioni essenziali. Per il browser questo significa poter riutilizzare immediatamente la copia già disponibile in cache. Per l’infrastruttura significa meno traffico, meno I/O, meno uso della CPU e meno competizione per le risorse.
Occorre però essere precisi: il 304 non abbassa magicamente il TTFB in ogni scenario. Se l’applicazione è costretta comunque a caricare stack PHP, interrogare il database, eseguire plugin pesanti e solo alla fine decidere che la risorsa non è cambiata, il beneficio può ridursi parecchio. Il vero vantaggio si ottiene quando la validazione avviene in modo efficiente, il più vicino possibile al web server, alla cache reverse proxy o alla CDN.
Il rapporto tra cache validation e trasferimento dei contenuti
Per comprendere il ruolo del 304, bisogna distinguere due concetti spesso confusi: cache expiration e cache validation.
La cache expiration è governata da direttive come Cache-Control: max-age=... o Expires. Con queste intestazioni si comunica al client per quanto tempo può considerare valida una risorsa senza neppure tornare a chiedere conferma al server.
La cache validation, invece, entra in gioco quando la risorsa deve essere verificata. In questo caso il client invia una richiesta condizionale e il server risponde con 304 se nulla è cambiato, oppure 200 con il nuovo contenuto se la risorsa è stata aggiornata.
Entrambi i meccanismi sono utili, ma hanno ruoli diversi. La sola expiration non basta sempre, perché alcuni contenuti devono essere verificati con maggiore frequenza. La sola validation, senza una buona policy di caching, rischia invece di generare troppe richieste inutili. Una configurazione ben fatta combina i due aspetti: definisce tempi di caching coerenti e usa ETag o Last-Modified per validare le risorse quando serve.
Gli header che rendono possibile il 304
Il funzionamento del 304 ruota soprattutto attorno a due famiglie di header.
Il primo è Last-Modified. Il server comunica la data e l’ora dell’ultima modifica della risorsa. Alla richiesta successiva, il client può inviare If-Modified-Since con quel valore. Se il file non è cambiato dopo quel momento, il server restituisce 304.
Il secondo è ETag, ovvero un identificatore univoco della versione della risorsa. Può essere calcolato in vari modi: hash del contenuto, inode più timestamp, revisione logica del file, fingerprint applicativa. Il client memorizza questo valore e nelle richieste successive invia If-None-Match. Se l’ETag coincide con quello attuale, il server risponde con 304.
In generale, ETag è più preciso perché non dipende solo dalla data di modifica, ma dallo stato effettivo della risorsa. Tuttavia in ambienti distribuiti va gestito con attenzione. Se più nodi generano ETag differenti per la stessa risorsa, si possono ottenere invalidazioni incoerenti e perdita dei benefici di caching. È uno scenario piuttosto comune in cluster con filesystem diversi, container multipli o web server non allineati.
Per questo, in molte infrastrutture ad alte prestazioni, si preferisce usare Last-Modified per contenuti statici semplici o ETag coerenti generati a livello applicativo o CDN, evitando implementazioni automatiche poco controllabili.
304 e crawling budget: perché interessa anche alla SEO tecnica
Il concetto di crawling budget riguarda, in modo semplificato, la quantità di risorse che un motore di ricerca è disposto a dedicare alla scansione di un sito. Non tutti i siti hanno gli stessi limiti, ma in generale ogni inefficienza nella scansione può tradursi in meno URL visitate, aggiornamenti più lenti e minore tempestività nell’indicizzazione delle modifiche.
Il codice 304 è utile anche qui perché consente ai crawler di verificare rapidamente risorse già note senza dover scaricare ogni volta l’intero contenuto. Quando un bot richiede una pagina o una risorsa statica e riceve conferma che non è cambiata, il processo risulta più leggero sia per il motore di ricerca sia per il server di origine.
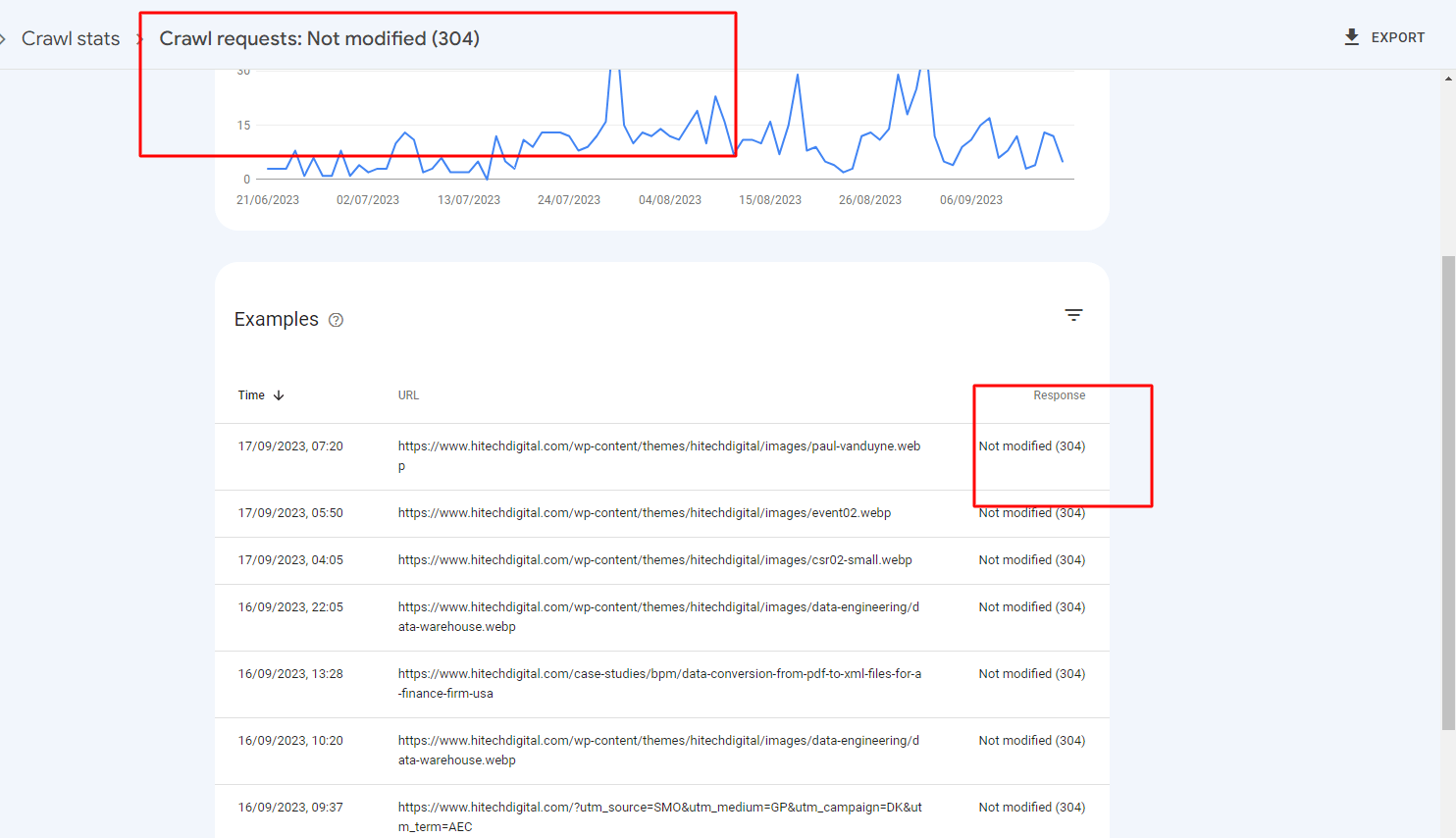
Questo è particolarmente rilevante nei siti con molte pagine, asset numerosi, template condivisi e contenuti aggiornati solo in parte. Se il crawler può validare in modo efficiente ciò che non è cambiato, il server spreca meno banda e meno tempo macchina. Questo può favorire una scansione più ordinata e sostenibile, soprattutto nei progetti molto estesi.
Naturalmente non bisogna semplificare troppo: il 304 non aumenta da solo il posizionamento SEO e non moltiplica automaticamente il budget di crawling. Tuttavia contribuisce a creare un ambiente tecnicamente più pulito, meno dispersivo e più efficiente. In contesti grandi o complessi, questa efficienza si traduce in un vantaggio concreto.
Il caso delle risorse statiche: dove il 304 dà il meglio
Se c’è un ambito in cui il 304 mostra immediatamente il suo valore, è quello degli asset statici. CSS, JavaScript, immagini, font e file multimediali sono spesso risorse che non cambiano di continuo ma vengono richieste molte volte, da utenti e bot.
Immaginiamo un sito WordPress, Magento o PrestaShop con decine di file frontend caricati in ogni pagina. Senza un sistema di caching e validazione corretto, il browser rischia di richiedere continuamente asset già posseduti, ricevendo ogni volta risposte 200 complete. Con header ben configurati, invece, può riutilizzare la cache e, quando necessario, validare velocemente le risorse ottenendo 304.
Il guadagno è doppio. Da un lato si riduce il peso della navigazione ripetuta, specialmente per utenti returning. Dall’altro si abbassa il carico complessivo sul server. Questo aspetto diventa ancora più importante nei momenti di picco, quando migliaia di richieste concorrenti per file identici possono saturare risorse che dovrebbero essere riservate ai contenuti dinamici.
Su asset versionati tramite fingerprint nel nome file, ad esempio app.8f3a21.css, si può addirittura spingere verso cache molto aggressive. In quei casi il 304 può diventare meno frequente perché il file, finché il nome resta uguale, è considerato immutabile. È spesso la strategia ideale. Ma quando l’expiration non è lunghissima o la validazione rimane necessaria, il 304 resta un alleato prezioso.
Il caso dell’HTML dinamico: attenzione a non fare confusione
Quando si passa dagli asset statici all’HTML dinamico, il discorso diventa più delicato. Non tutte le pagine HTML si prestano allo stesso modo alla validazione condizionale. Una homepage con contenuti che cambiano spesso, widget personalizzati, banner, sezioni dinamiche o frammenti utente-specifici potrebbe non essere una buona candidata per il 304, almeno non senza un sistema di caching applicativo o reverse proxy ben progettato.
In alcuni casi il rischio è di introdurre più complessità che benefici. Se l’applicazione deve comunque renderizzare completamente la pagina per determinare se è cambiata, la risposta 304 arriva troppo tardi per essere davvero efficiente. In altri casi si possono verificare errori logici, con contenuti variabili che vengono considerati erroneamente invariati.
Questo non significa che il 304 non serva per l’HTML. Significa solo che bisogna usarlo con criterio. Su pagine cacheabili, landing page relativamente stabili, documentazione, schede prodotto con aggiornamenti non continui o sezioni editoriali ben servite da reverse proxy, può funzionare molto bene. Su pagine altamente personalizzate o fortemente dinamiche, conviene ragionare prima sull’architettura della cache.
CDN, reverse proxy e web server: il 304 funziona ancora meglio
Il 304 dà il massimo quando la sua gestione è delegata agli strati più efficienti dell’infrastruttura: Nginx, Varnish, reverse proxy, CDN. In questi livelli la validazione può avvenire senza coinvolgere ogni volta l’intera applicazione.
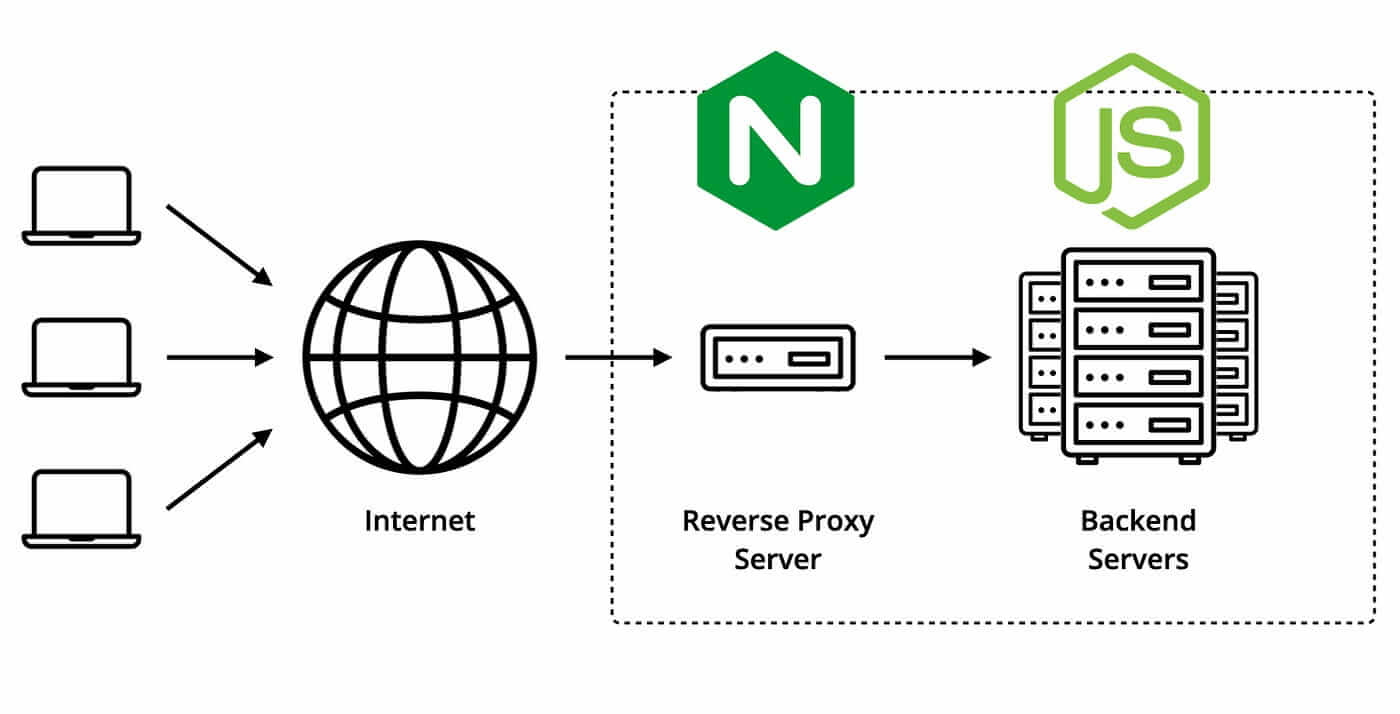
Una CDN, ad esempio, può servire direttamente asset già cacheati agli edge oppure validarne lo stato verso l’origine in modo ottimizzato. Un reverse proxy come Varnish può ridurre drasticamente il numero di richieste che raggiungono PHP o il backend applicativo. Nginx può gestire in maniera molto efficiente file statici con Last-Modified ed eventualmente ETag.
Il principio è semplice: più la logica di validazione si trova vicino al livello HTTP puro e lontano dal codice applicativo pesante, più il 304 sarà economico e utile. Al contrario, quando ogni richiesta deve attraversare CMS, plugin, ORM, sessioni e middleware prima di essere validata, si perde gran parte del vantaggio.
Errori comuni nell’implementazione del 304
Uno degli errori più diffusi è pensare che basti vedere dei 304 nei log per concludere che il sistema di caching sia ben configurato. Non è così. I 304 possono essere utili, ma non devono compensare una cattiva strategia di cache. Se una risorsa immutabile viene validata troppo spesso anziché servita direttamente dalla cache locale del browser, c’è ancora margine di miglioramento.
Un altro errore frequente riguarda gli ETag incoerenti in ambienti multi-server. Se due nodi restituiscono ETag diversi per lo stesso file, il client tenderà a scaricare nuovamente la risorsa o a invalidarla inutilmente. In cluster e infrastrutture distribuite questo problema è molto più comune di quanto si pensi.
C’è poi il tema delle risposte dinamiche servite con 304 in modo improprio. Se l’HTML contiene parti che cambiano in base all’utente, alla sessione, al carrello o alla geolocalizzazione, una validazione ingenua può generare comportamenti errati. In questi casi bisogna separare bene contenuti cacheabili e contenuti personalizzati.
Infine, attenzione ai plugin o ai layer applicativi che impostano header contrastanti, ad esempio Cache-Control: no-cache insieme a logiche che vorrebbero favorire la validazione. Quando le policy sono confuse, il risultato è spesso un flusso inefficiente di richieste e risposte.
Come verificare se il 304 sta lavorando bene
Per capire se il 304 è realmente utile nel proprio stack, serve osservare i dati nel modo corretto. I log del web server sono il primo punto di partenza: mostrano quante richieste si chiudono con 304, su quali asset e con quale frequenza. Ma vanno interpretati nel contesto.
È utile analizzare gli header con curl -I, gli strumenti di sviluppo del browser e le intestazioni restituite dalla CDN o dal reverse proxy. Bisogna verificare almeno quattro aspetti: presenza di Cache-Control, presenza di Last-Modified o ETag, coerenza delle risposte tra nodi differenti e comportamento del browser ai successivi reload.
Sul piano prestazionale, conviene confrontare il costo medio di una risposta 200 e di una 304 per lo stesso tipo di risorsa. Se il server continua a spendere troppo tempo anche per generare 304, significa che la validazione è posizionata troppo in alto nello stack o implementata in modo inefficiente.
Sul piano SEO tecnico, si può osservare il comportamento dei crawler nei log, valutando se bot come Googlebot effettuano richieste condizionali e quali tipi di risorse vengono validate più spesso. Questo consente di capire se il sito sta offrendo segnali HTTP puliti e coerenti.
Una strategia intelligente: 304 dove serve, cache aggressiva dove possibile
L’approccio migliore non è “usare il 304 ovunque”, ma usarlo bene dove ha senso. Per gli asset statici versionati, spesso la soluzione ottimale è una cache lunga e aggressiva, con file fingerprintati e scaricati solo quando cambia il nome. Per gli asset non completamente immutabili, il 304 è perfetto come strumento di validazione. Per l’HTML, invece, va valutato caso per caso in base a cache layer, stabilità dei contenuti e costo della generazione.
In sostanza, il 304 va considerato come parte di una strategia più ampia di efficienza HTTP. Non è un trucco, non è una scorciatoia e non sostituisce una buona architettura. Però, quando è configurato correttamente, contribuisce a ridurre il traffico superfluo, migliorare la reattività percepita e alleggerire il lavoro sia del browser sia dei crawler.
Conclusioni
Il codice HTTP 304 Not Modified è uno di quegli strumenti che raramente finiscono al centro delle discussioni marketing, ma che nella pratica fanno la differenza. Aiuta a migliorare il TTFB in molti scenari, riduce il trasferimento inutile di dati, alleggerisce il carico su infrastruttura e applicazione e rende più razionale la scansione delle risorse da parte dei bot.
Il suo vero valore emerge soprattutto quando è inserito in una strategia coerente: header ben impostati, validazione efficiente, ETag o Last-Modified corretti, cache browser ben governata, reverse proxy e CDN configurati con criterio. In quel contesto il 304 smette di essere un semplice codice di stato e diventa uno strumento concreto di ottimizzazione.
Chi gestisce siti moderni, specialmente ad alto traffico o con architetture complesse, farebbe bene a non sottovalutare questo aspetto. Perché spesso il miglioramento delle performance non passa solo da interventi vistosi o da hardware più potente, ma anche dalla capacità di non fare lavoro inutile. Ed è esattamente questo il principio su cui si basa il 304: non rispedire ciò che il client possiede già, non sprecare CPU, non sprecare banda, non sprecare tempo.
In un ecosistema web in cui efficienza, velocità e sostenibilità tecnica sono sempre più centrali, il 304 Not Modified resta una risposta piccola, essenziale e spesso estremamente intelligente.