
Indice dei contenuti dell'articolo:
Il problema: quando gestire centinaia di server diventa un incubo
Se amministrate server Linux da qualche anno, sapete bene di cosa stiamo parlando. Negli ultimi mesi il fenomeno è diventato semplicemente insostenibile: ondate sempre più aggressive di bot provenienti dal Sud-Est asiatico, dalla Cina, dalla Russia, e più recentemente una nuova generazione di crawler legati all’intelligenza artificiale che setacciano ogni singola pagina di ogni singolo sito web, ignorando completamente robots.txt e qualsiasi forma di buona educazione digitale.
Noi di Managedserver.it gestiamo un parco macchine distribuito su scala globale. Parliamo di migliaia di server Linux sparsi tra OVH, Hetzner, Aruba, AWS, Azure, Google Cloud e infrastrutture on-premise di clienti in Italia, Europa e oltre. Da circa sei mesi ricevevamo ticket su ticket: “Il sito è lento”, “Il server è sotto carico”, “C’è qualcosa che non va”. E nella stragrande maggioranza dei casi, il colpevole era lo stesso: traffico indesiderato. Bot che martellano endpoint API, crawler AI che scaricano interi siti web, tentativi di brute force SSH, scansioni di porte a tappeto.
La risposta classica era sempre la stessa: accedere al server via SSH, analizzare i log, identificare gli IP, aggiungere regole iptables a mano, magari configurare Fail2ban, controllare che non si fossero rotte le regole di qualcun altro. Poi passare al server successivo. E a quello dopo ancora. E così via.
Era diventato un’attività a tempo pieno che non scalava.
Il momento in cui abbiamo detto “basta”
Il punto di rottura è arrivato durante una settimana particolarmente intensa in cui abbiamo dovuto gestire simultaneamente un attacco DDoS distribuito su una dozzina di server di un cliente, un’ondata di crawling aggressivo da parte di GPTBot e ClaudeBot su decine di siti WordPress, e una serie di scansioni automatizzate su range IP che ospitavano server di clienti diversi.
Il nostro workflow era frammentato in modo imbarazzante:
- Riga di comando bash su ogni singolo server per applicare regole iptables
- Netdata per monitorare le risorse, ma su un’interfaccia separata per ogni server
- UptimeRobot per gli alert di disponibilità, con notifiche che arrivavano senza contesto
- Fogli di calcolo per tenere traccia di quali regole erano state applicate dove
Non avevamo una visione d’insieme. Non sapevamo a colpo d’occhio quali server avessero le stesse regole, quali fossero protetti contro un determinato range IP e quali no. Applicare una nuova regola di blocco su tutti i server significava collegarsi uno per uno, con il rischio concreto di dimenticare qualche macchina o, peggio, di inserire una regola sbagliata che bloccasse traffico legittimo senza possibilità di rollback rapido.
Ci serviva uno strumento unico, centralizzato, che ci desse il controllo totale.
E siccome sul mercato non trovavamo nulla che facesse esattamente quello di cui avevamo bisogno — qualcosa di leggero, compatibile con qualsiasi distribuzione Linux, che non richiedesse agenti pesanti o dipendenze assurde — abbiamo deciso di costruircelo da soli.
È nato così CFM 4 Linux — Centralized Firewall Manager — o più semplicemente, CFM.
Architettura: un server, tanti agenti, zero problemi di NAT
Prima di entrare nelle funzionalità, vale la pena spendere due parole sull’architettura, perché è una delle scelte progettuali di cui siamo più soddisfatti.
CFM è composto da due componenti:
Il Server (la “cabina di regia”)
Il server è un’applicazione web realizzata in PHP 8.3 con Nginx e PostgreSQL 18 come database. La scelta di PostgreSQL non è casuale: il suo tipo nativo CIDR e gli indici GIST ci permettono di fare query sugli indirizzi IP con una velocità e una precisione che MySQL non potrebbe offrire. JSONB per i dati strutturati, funzionalità avanzate di aggregazione, e trigger per garantire l’immutabilità del log di audit.
Il server espone una console web moderna costruita con Tabler (framework Bootstrap 5 per dashboard amministrative) che offre un’interfaccia pulita, reattiva e piacevole da usare anche per ore. Supporta tema chiaro, tema scuro e — per i nostalgici — una modalità “Matrix” con estetica fosfori verdi su sfondo nero, effetto scanline CRT incluso.

L’Agent (il “soldato sul campo”)
L’agent è un singolo binario statico scritto in Go 1.22, cross-compilato per Linux amd64 e arm64. Nessuna dipendenza, nessun runtime da installare, nessuna libreria condivisa. Lo scarichi, lo rendi eseguibile, lo lanci. Fine.
L’agent adotta un modello pull: è lui che contatta periodicamente il server via HTTPS per chiedere “ci sono novità?”, scaricare la policy aggiornata e applicarla. Questo risolve elegantemente il problema del NAT e dei firewall intermedi — non serve aprire porte in ingresso sui server gestiti, non serve configurare VPN, non serve nulla. Se il server può fare una connessione HTTPS in uscita, funziona.
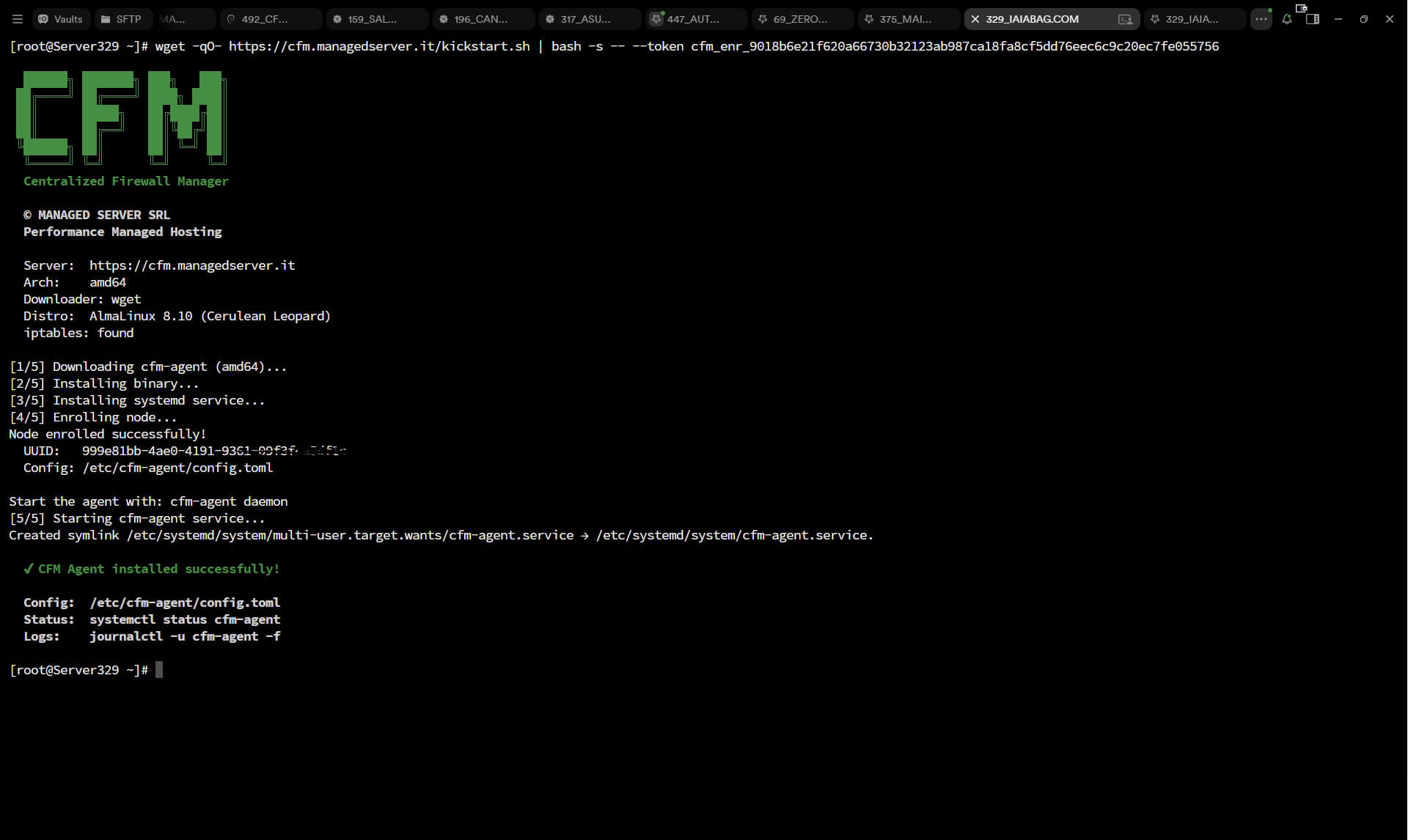
L’autenticazione avviene tramite Bearer token (hash SHA-256 memorizzato nel database) e l’enrollment iniziale utilizza token monouso. Il cambio di policy viene rilevato tramite ETag HTTP — se non c’è nulla di nuovo, l’agent riceve un 304 Not Modified e non spreca banda né risorse.
Come vengono applicate le regole
L’agent rileva automaticamente il backend firewall disponibile sul sistema:
- iptables (il classico, supportato ovunque)
- nftables (il successore moderno, con set nominati per lookup O(1))
- firewalld (RHEL/CentOS/Fedora, con fallback intelligente)
Le regole vengono applicate usando catene personalizzate (CFM_SAFETY, CFM_INPUT, CFM_FORWARD) tramite iptables-restore --noflush. Il flag --noflush è fondamentale: significa che CFM tocca solo le sue catene, senza interferire con Fail2ban, CSF, Docker, o qualsiasi altro strumento che gestisca le proprie regole iptables sullo stesso server. La coesistenza è garantita by design.
La catena CFM_SAFETY viene inserita in posizione 1 sulla catena INPUT con massima priorità e contiene:
- La regola ESTABLISHED/RELATED (il traffico delle connessioni già stabilite non viene mai bloccato)
- Il loopback (lo stesso per ovvie ragioni)
- Gli IP delle interfacce locali del server (per evitare che il nodo blocchi sé stesso)
- L’IP del server CFM (per non perdere mai la connettività di gestione)
- I nameserver DNS del sistema e i DNS pubblici più comuni (per non rompere la risoluzione DNS)
- La whitelist globale (gli IP che devono essere sempre raggiungibili, a prescindere da tutto)
Solo dopo la catena safety vengono processate le regole di blocco in CFM_INPUT e CFM_FORWARD.
In caso di errore nell’applicazione delle regole, l’agent esegue un rollback automatico alla configurazione precedente, garantendo che il server non rimanga mai in uno stato inconsistente.
La Dashboard: tutto sotto controllo in un colpo d’occhio
Quando effettuate il login su CFM, la prima cosa che vedete è la dashboard. Ed è stata progettata per rispondere alla domanda più importante: “com’è la situazione, adesso?”
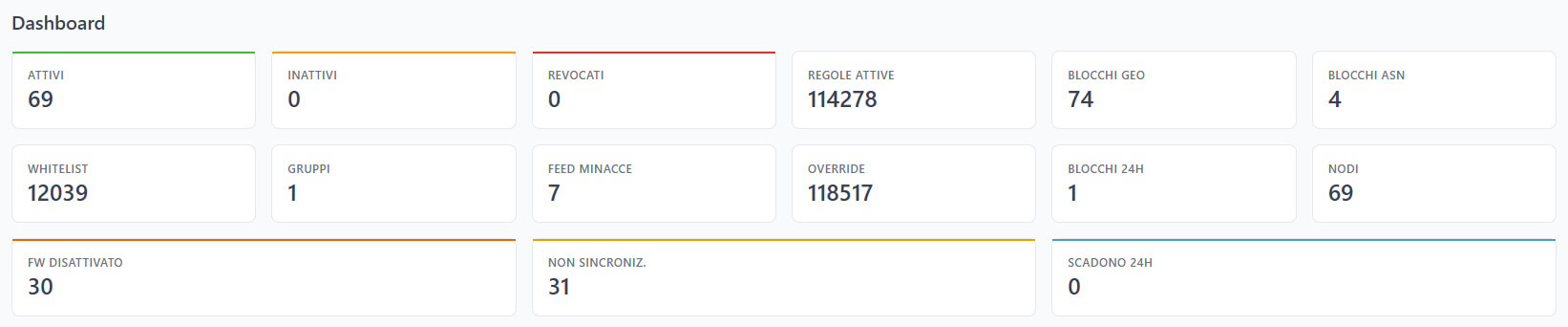
Le card KPI in alto
Una fila di card colorate vi mostra immediatamente:
- Nodi attivi / stale / revocati / totali
- Regole policy attive
- Blocchi geografici attivi
- Blocchi ASN attivi
- Whitelist entries
- Gruppi configurati
- Threat feeds attivi
- Override nodo-specifici
- Blocchi temporanei (ultimi 24h)
Se ci sono situazioni che richiedono attenzione — firewall disabilitati, nodi fuori sync, blocchi in scadenza — un pannello di warning arancione appare automaticamente con il dettaglio.
La mappa del mondo
Al centro della dashboard c’è una mappa interattiva (basata su amCharts) che mostra la distribuzione geografica dei vostri nodi. Ogni punto sulla mappa rappresenta un server gestito, con colore che indica lo stato. È incredibilmente utile per avere una percezione visiva immediata della vostra infrastruttura.
Timeline delle attività
Sulla destra, una timeline mostra le azioni recenti: chi ha aggiunto una regola, chi ha modificato un override, quando è avvenuto l’ultimo sync di un nodo. È il “feed di notizie” del vostro firewall.
Grafico di sincronizzazione
Un grafico dedicato mostra lo stato di sincronizzazione dei nodi nel tempo: quanti sono allineati con l’ultima policy, quanti sono in ritardo, quanti hanno avuto errori.

Gestione Policy: il cuore di CFM
La pagina Policy è dove succede la magia. È il punto centrale da cui controllate le regole firewall di tutti i vostri server contemporaneamente.
La Whitelist Globale
In cima alla pagina trovate la whitelist globale — gli IP e CIDR che devono essere sempre raggiungibili, su tutti i nodi, a prescindere da qualsiasi regola di blocco. Ogni voce richiede una motivazione obbligatoria (per l’audit trail) e supporta una scadenza opzionale.
La whitelist è potente: potete aggiungere singoli IP (93.184.216.34), CIDR (10.0.0.0/24), range IP (192.168.1.100-192.168.1.200 — che vengono automaticamente convertiti nel set minimo di CIDR), e persino interi ASN (AS13335 per Cloudflare, ad esempio, che risolve automaticamente tutti i prefix IPv4 e IPv6 dell’autonomous system).
Le regole di whitelist vengono inserite nella catena CFM_SAFETY con target ACCEPT e processate prima di qualsiasi regola di blocco. Se un IP è contemporaneamente bloccato e in whitelist, la whitelist vince sempre.
Le Regole di Blocco
La tabella delle regole attive mostra tutte le policy in vigore con:
- CIDR dell’IP bloccato
- Direzione (Input, Forward, o entrambe)
- Azione (Drop o Reject)
- Protocollo e Porta (opzionali — per blocchi chirurgici)
- Motivazione
- Scadenza (badge colorato che indica il tempo rimanente)
- Chi ha creato la regola

Sopra la tabella trovate una barra di ricerca in tempo reale e filtri per direzione, azione e stato (permanente, temporaneo, in scadenza). La paginazione gestisce senza problemi policy con migliaia di regole.
Il modulo di aggiunta regola accetta input flessibili. Potete inserire:
- Un singolo IP:
185.220.101.34 - Un CIDR:
185.220.101.0/24 - Un range:
185.220.101.1-185.220.101.50 - Un ASN:
AS4134(China Telecom — e CFM risolve automaticamente tutti i prefix) - Un codice paese:
CN(e CFM blocca tutti i prefix GeoIP associati)
Per ogni regola potete specificare la durata: permanente, 1 ora, 3 ore, 6 ore, 12 ore, 24 ore, 3 giorni, 7 giorni, o 30 giorni. Le regole temporanee scadono automaticamente e vengono rimosse da un cron job dedicato.
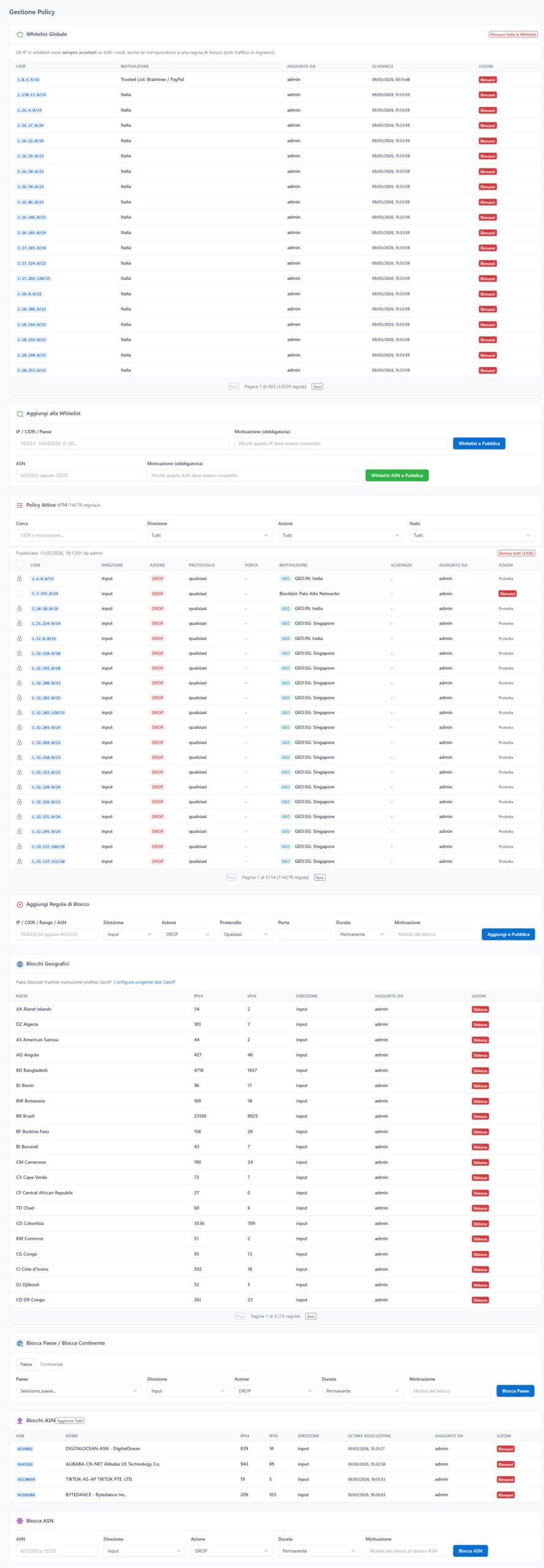
Il Geo-Blocking
Questa è una delle funzionalità che usiamo di più. La sezione Geo-Blocking permette di bloccare intere nazioni o interi continenti con un click.
Due modalità di visualizzazione:
- Per Paese: una lista di tutti i paesi con checkbox, barra di ricerca e azione rapida
- Per Continente: selezionate un continente e tutti i paesi al suo interno vengono bloccati/sbloccati
I dati GeoIP provengono da due fonti configurabili:
- DB-IP Lite (database gratuito ad alta precisione)
- Delegazioni RIR (i registri regionali Internet: RIPE, ARIN, APNIC, LACNIC, AFRINIC)

Il sistema importa i prefix CIDR associati ad ogni paese e li inserisce come regole di policy normali, con la differenza che vengono marcati come “GEO:” nella motivazione e sono protetti dalla cancellazione accidentale (non potete rimuoverli dalla tabella regole — dovete usare la sezione Geo dedicata).
Quando l’agent applica il geo-blocking su larga scala (bloccare la Cina significa ~80.000 prefix IPv4), utilizza strategie ottimizzate per evitare di creare centinaia di migliaia di regole iptables lineari:
- Su nftables: utilizza named set con flag interval — lookup O(1) indipendentemente dal numero di prefix
- Su iptables: utilizza un sistema proprietario per aumentare le performance e ridurre il recordset in memoria.
Il Blocco per ASN
L’Autonomous System Number è l’identificativo di una rete. Invece di bloccare singoli IP, potete bloccare un’intera rete per ASN. CFM risolve automaticamente l’ASN nei suoi prefix IP tramite due fonti:
- RIPEstat API (fonte primaria)
- BGPView (fallback)
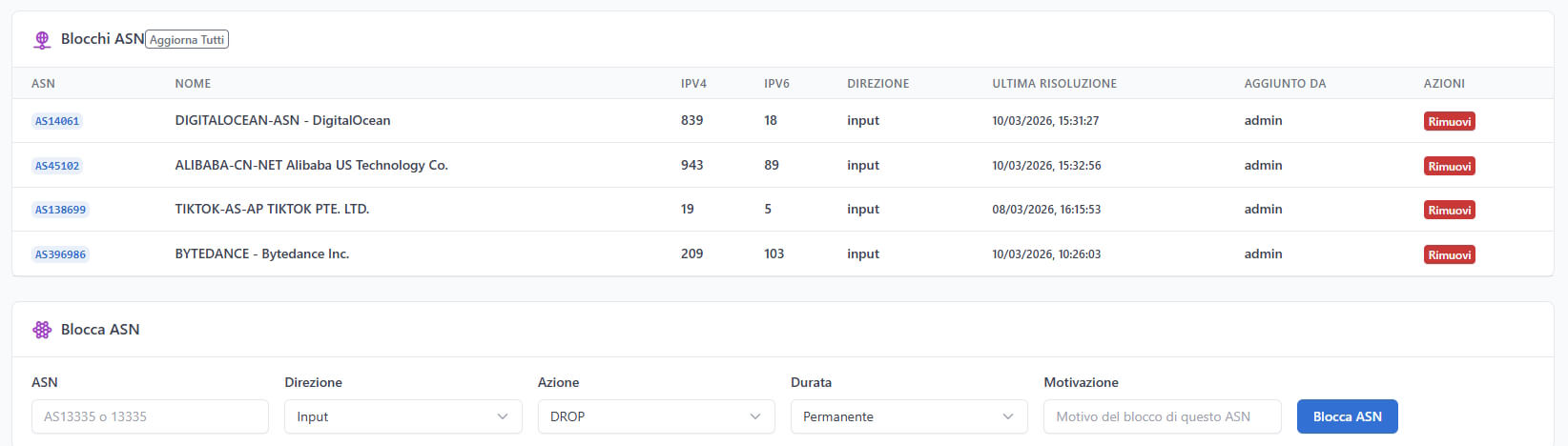
Il blocco ASN è dinamico: con il pulsante “Aggiorna Tutti” potete ri-risolvere tutti gli ASN bloccati per catturare eventuali nuovi prefix aggiunti dall’operatore di rete. Massimo 5.000 prefix per ASN per prevenire abusi.
I Threat Feeds
CFM può importare automaticamente blocklist da fonti di intelligence sulle minacce:
- FireHOL (aggregatore di blocklist)
- Spamhaus DROP (Don’t Route Or Peer)
- Abuse.ch (malware, botnet C2)
- E molti altri — con possibilità di aggiungere feed personalizzati
Ogni feed viene aggiornato automaticamente secondo la schedulazione configurata e le regole vengono taggate con “Feed: nome_feed” per facile identificazione.
Operazioni Bulk
Per le situazioni di emergenza (leggi: è venerdì sera e un botnet sta martellando 47 server), CFM offre:
- Import bulk: incollate una lista di IP (uno per riga, supporta commenti con #), scegliete direzione/azione/durata/motivazione, preview e poi esecuzione in un click
- Delete bulk: selezionate le regole con le checkbox e cancellatele in blocco
- Delete filtrate: applicate un filtro e cancellate tutte le regole visibili
- Export/Import configurazione: esportate l’intera configurazione (policy, whitelist, geo, ASN, gruppi, override) in un file JSON e reimportatela su un’altra istanza CFM
Il Versioning delle Policy
Ogni singola modifica alla policy — che sia un’aggiunta, una rimozione, un import — genera automaticamente una nuova versione immutabile. Niente “draft” da salvare manualmente: cambiate qualcosa, si crea una nuova versione, e al prossimo poll gli agent la scaricano.
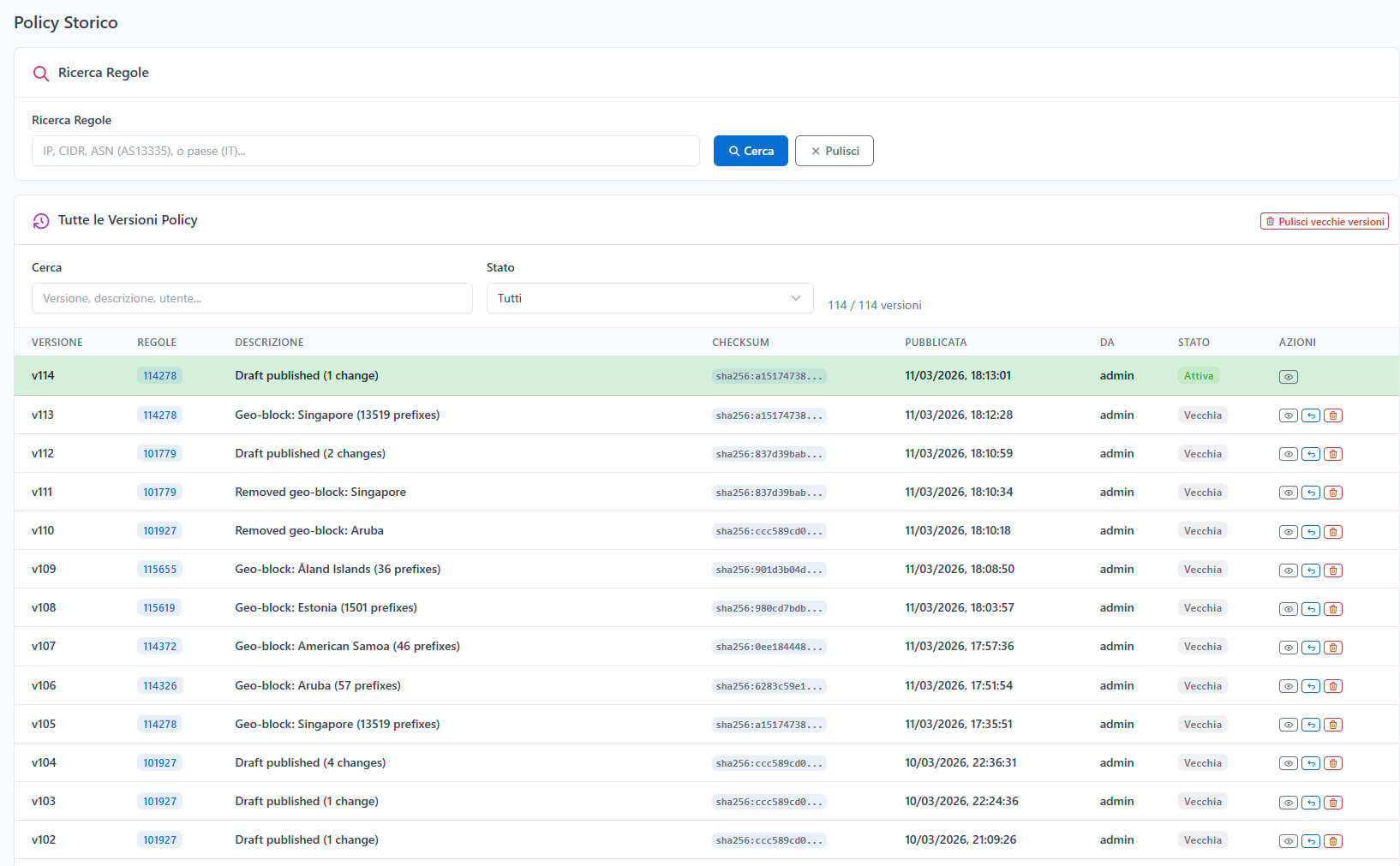
Dalla pagina Policy Storico potete:
- Vedere tutte le versioni con timestamp, autore e numero di regole
- Confrontare due versioni side-by-side (diff visivo)
- Fare rollback a qualsiasi versione precedente con un click
Il rollback non cancella la versione corrente — crea una nuova versione identica a quella target. La storia è sempre conservata, per audit trail completo.
La Draft Mode
Per le modifiche complesse che richiedono più passaggi, CFM offre una modalità bozza. Quando la attivate:
- Gli agent continuano a vedere la versione “congelata” (quella attiva al momento dell’attivazione del draft)
- Voi lavorate sulla versione live nella console web
- Un banner giallo vi mostra quante modifiche avete in sospeso
- Potete vedere l’anteprima delle differenze (regole aggiunte/rimosse)
- Quando siete soddisfatti, pubblicate il draft e tutti gli agent ricevono la nuova versione
- Se cambiate idea, scartate il draft e tutto torna come prima
Questo è particolarmente utile quando dovete fare una ristrutturazione significativa delle regole senza rischiare di esporre gli agent a policy intermedie incomplete.
I Nodi: gestione individuale e per gruppi
La pagina Nodi
La lista dei nodi è la vostra flotta. Visualizzabile in modalità lista (tabella dettagliata) o card (griglia visiva con stato), ogni nodo mostra:
- Nome, IP, sistema operativo
- Stato (attivo/stale/revocato) con badge colorato
- Ultima sincronizzazione
- Versione della policy applicata
- Versione dell’agent installato (con indicazione se è disponibile un aggiornamento)
- Stato del firewall (abilitato/disabilitato)
- Toggle per i vari monitoraggi (CPU, RAM, traffico, dischi, rete)
L’enrollment di un nuovo nodo è semplice: generate un token dalla console, eseguite il comando di enrollment sull’agent, e il nodo appare automaticamente nella lista.
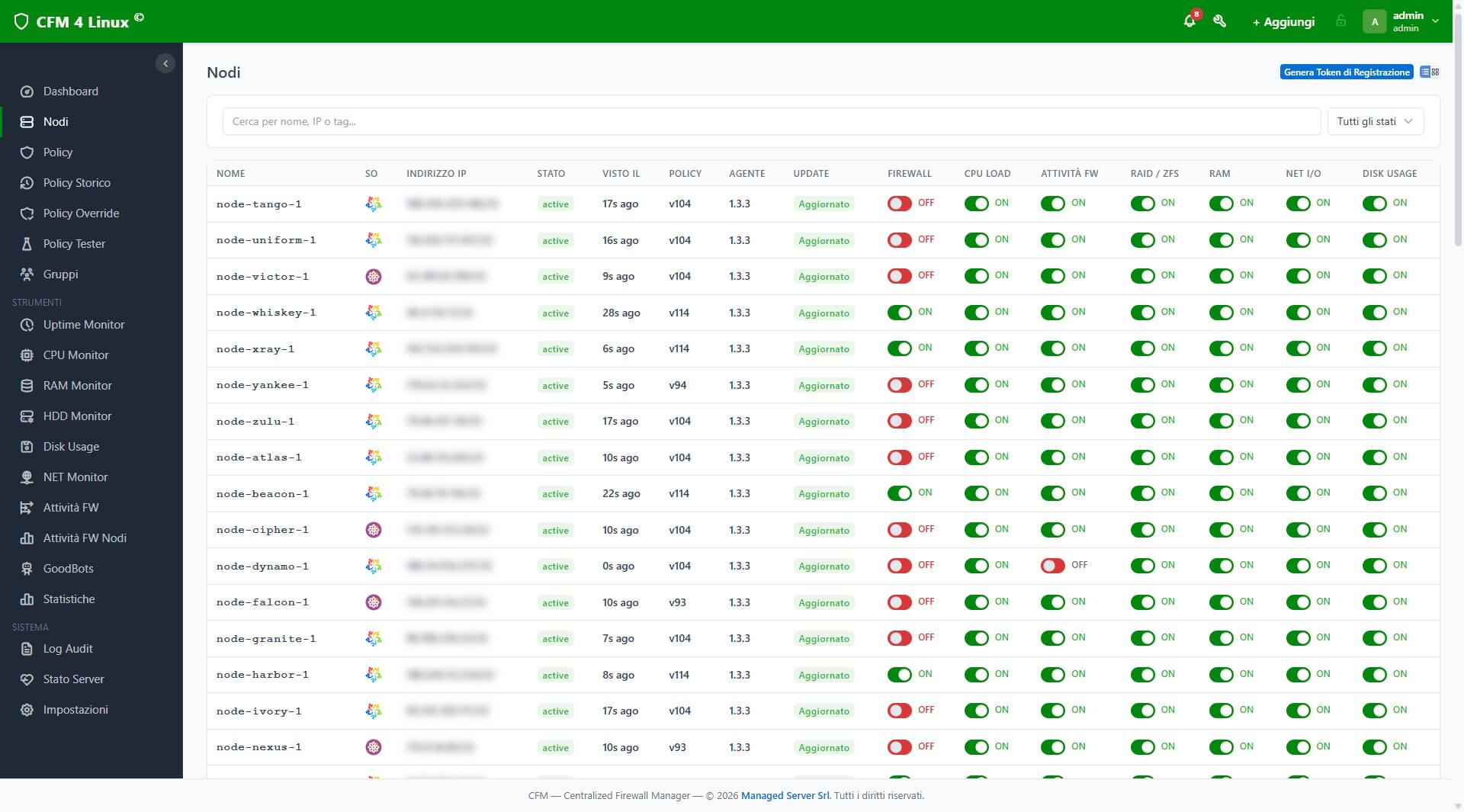
Dettaglio Nodo
Cliccando su un nodo, si apre una pagina dettaglio ricchissima:
Card informativa in alto con hostname, IP, OS, tempo dall’ultimo contatto, stato di sync, e toggle per abilitare/disabilitare il firewall su quel specifico nodo.
Override per nodo: potete aggiungere regole che valgono solo per quel nodo — sia di tipo “allow” (whitelist locale) che “deny” (blocco locale). Questo è perfetto per situazioni come “il server del cliente X deve poter essere raggiunto dall’IP del suo ufficio anche se quell’IP ricade in un range bloccato globalmente”.
Esclusioni: potete escludere regole globali specifiche per un nodo. Se avete bloccato globalmente un certo CIDR ma un nodo specifico ha bisogno di raggiungerlo, l’esclusione risolve il problema senza toccare la policy globale.
Geo-Policy per nodo: ogni nodo può avere la propria policy geografica indipendente, con tre modalità:
- Inherit: segue la policy globale
- Allow-Only: solo i paesi nella whitelist possono raggiungere il server (utile per server che servono un mercato specifico)
- Deny-Only: blocca specifici paesi (il default per la maggior parte degli scenari)
Con azioni rapide per bloccare/permettere interi continenti o cercare singoli paesi.
Storico sincronizzazione: tabella con ogni sync dell’agent — timestamp, versione policy, esito (applicata/fallita/rollback), numero di regole applicate, eventuale messaggio di errore.
Appartenenza a gruppi: lista dei gruppi di cui il nodo fa parte, con link diretto alla gestione del gruppo.
Tag: coppie chiave-valore personalizzabili (ambiente: produzione, cliente: acme, ruolo: webserver) utili per organizzare e filtrare i nodi.
I Gruppi
I gruppi permettono di organizzare i nodi per cliente, ambiente, ruolo o qualsiasi criterio. Un nodo può appartenere a più gruppi contemporaneamente.
La potenza dei gruppi sta nella possibilità di definire regole per gruppo: regole che si applicano solo ai nodi membri di quel gruppo, in aggiunta alle regole globali. Perfetto per scenari come:
- “Tutti i server del cliente ACME devono bloccare questo range IP”
- “Tutti i server di produzione devono avere questa whitelist aggiuntiva”
- “Tutti i webserver devono bloccare le porte non standard”
La policy effettiva di un nodo è sempre: regole globali + regole dei gruppi di appartenenza + override nodo-specifici.
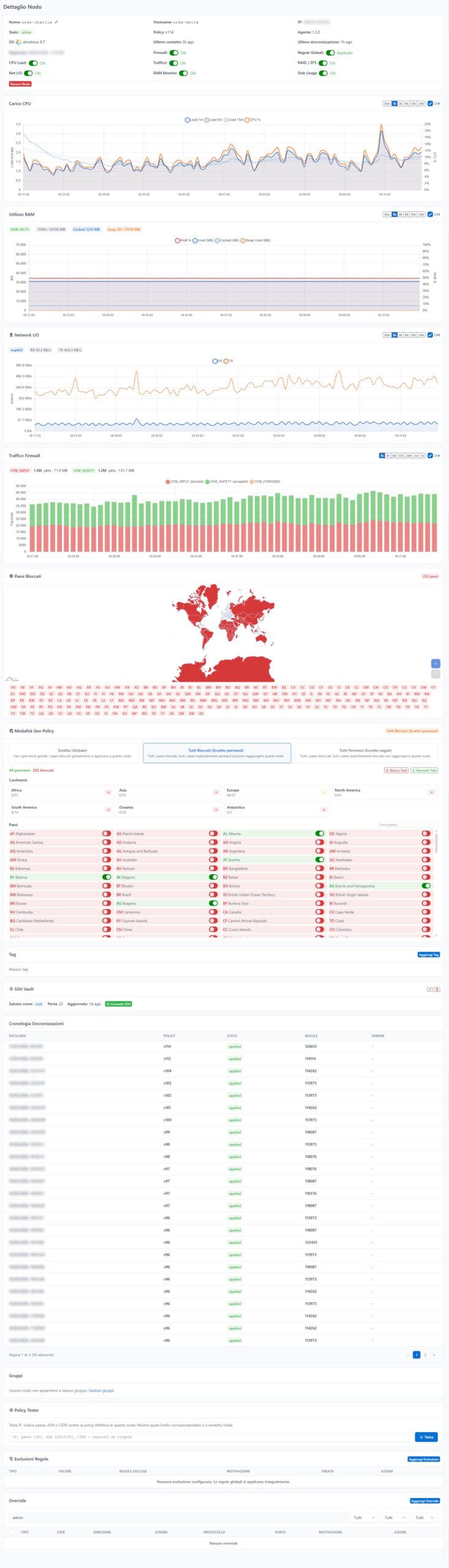
Il Policy Tester
Una delle funzionalità più utili nell’operatività quotidiana. Inserite un IP, un CIDR o un ASN, e CFM vi dice immediatamente su quali nodi quel traffico verrebbe bloccato, da quale regola, e con quale azione.
Questo è preziosissimo per il troubleshooting: “Il cliente dice che non riesce a raggiungere il suo server, il suo IP è 203.0.113.45” → lo inserite nel Policy Tester → scoprite che è bloccato dalla regola GEO:CN perché il suo ISP usa un range IP originariamente assegnato alla Cina → aggiungete un override allow per quel nodo → problema risolto in 30 secondi.
E poi abbiamo pensato: “E se ci mettessimo anche il monitoring?”
Avere il controllo centralizzato del firewall era fantastico. Ma continuavamo a dover saltare tra CFM, Netdata, CheckMK e UptimeRobot per avere il quadro completo della situazione. Ogni volta che un alert di carico arrivava, dovevamo aprire un’altra interfaccia per capire cosa stesse succedendo.
Così ci siamo detti: l’agent è già sul server, comunica già con il server centrale, perché non fargli raccogliere anche dati di monitoring?
E da quel momento CFM è diventato molto più di un firewall manager.
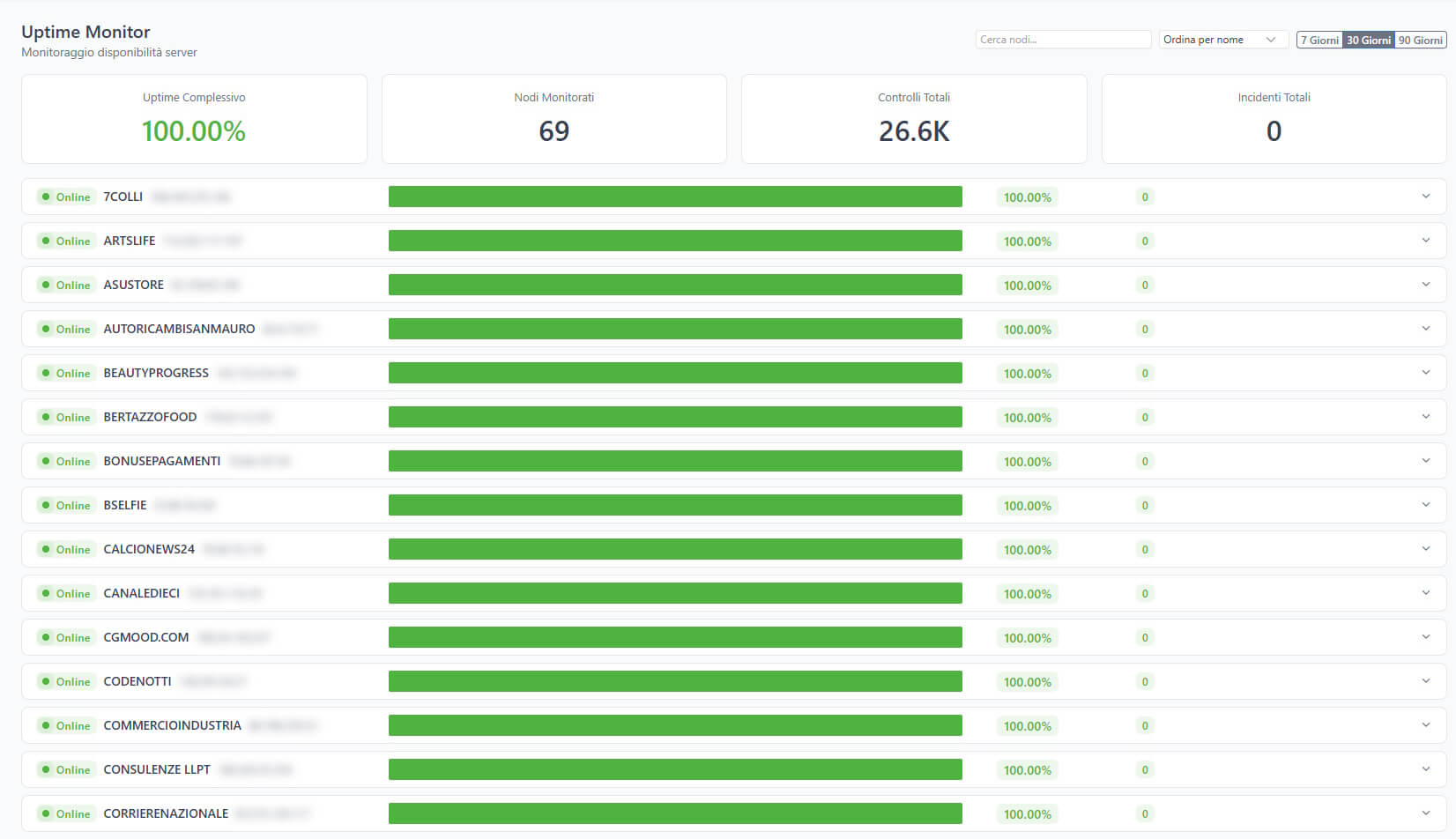
Uptime Monitoring
La pagina Uptime mostra la disponibilità storica di ogni nodo su finestre di 7, 30 e 90 giorni.
Per ogni nodo vedete:
- Percentuale di uptime (con colori: verde >99.9%, giallo >99%, rosso il resto)
- Numero di controlli effettuati
- Numero di incidenti
- Una heatmap temporale espandibile che mostra visivamente quando il nodo era su/giù
I dati di uptime vengono derivati dall’heartbeat dell’agent: se l’agent non contatta il server entro la soglia configurata (default 10 minuti), il nodo viene considerato “stale” e l’incidente registrato.
CPU Monitor
L’agent legge /proc/loadavg e invia i valori di load average a 1, 5 e 15 minuti insieme al numero di thread attivi. Il server memorizza lo storico e la pagina CPU Monitor mostra:
- Lista di tutti i nodi con monitoraggio CPU attivo
- Colonne ordinabili: Load 1m, Load 5m, Load 15m, CPU%
- Per ogni nodo, un grafico espandibile con selettore di intervallo temporale (30 minuti, 1 ora, 3 ore, 6 ore, 12 ore, 24 ore)
- Toggle Live per aggiornamento automatico ogni 10 secondi
- Visualizzazione lista o card
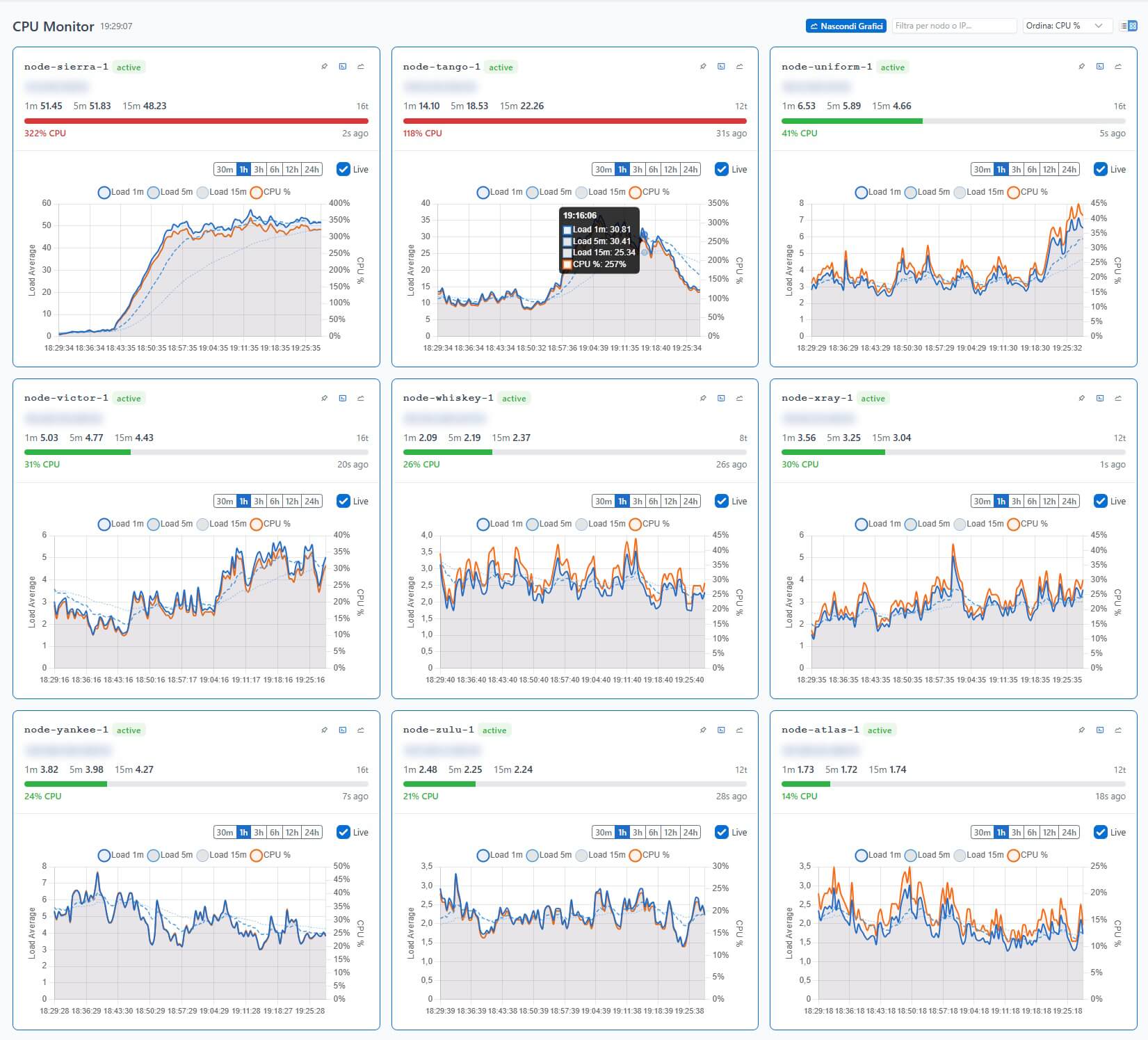
I button group per la selezione del range temporale usano uno stile coerente su tutte le pagine di monitoring: bottoni compatti con stato attivo evidenziato in blu e un checkbox Live per l’auto-refresh.
RAM Monitor
L’agent legge /proc/meminfo e raccoglie:
- Memoria totale, disponibile, usata (in MB e percentuale)
- Buffer e cache
- Swap totale e usata
La pagina RAM Monitor mostra badge sintetici per ogni nodo (RAM%, Used MB, Cached MB, Swap Used) e grafici espandibili con gli stessi controlli di range temporale e aggiornamento live della CPU.
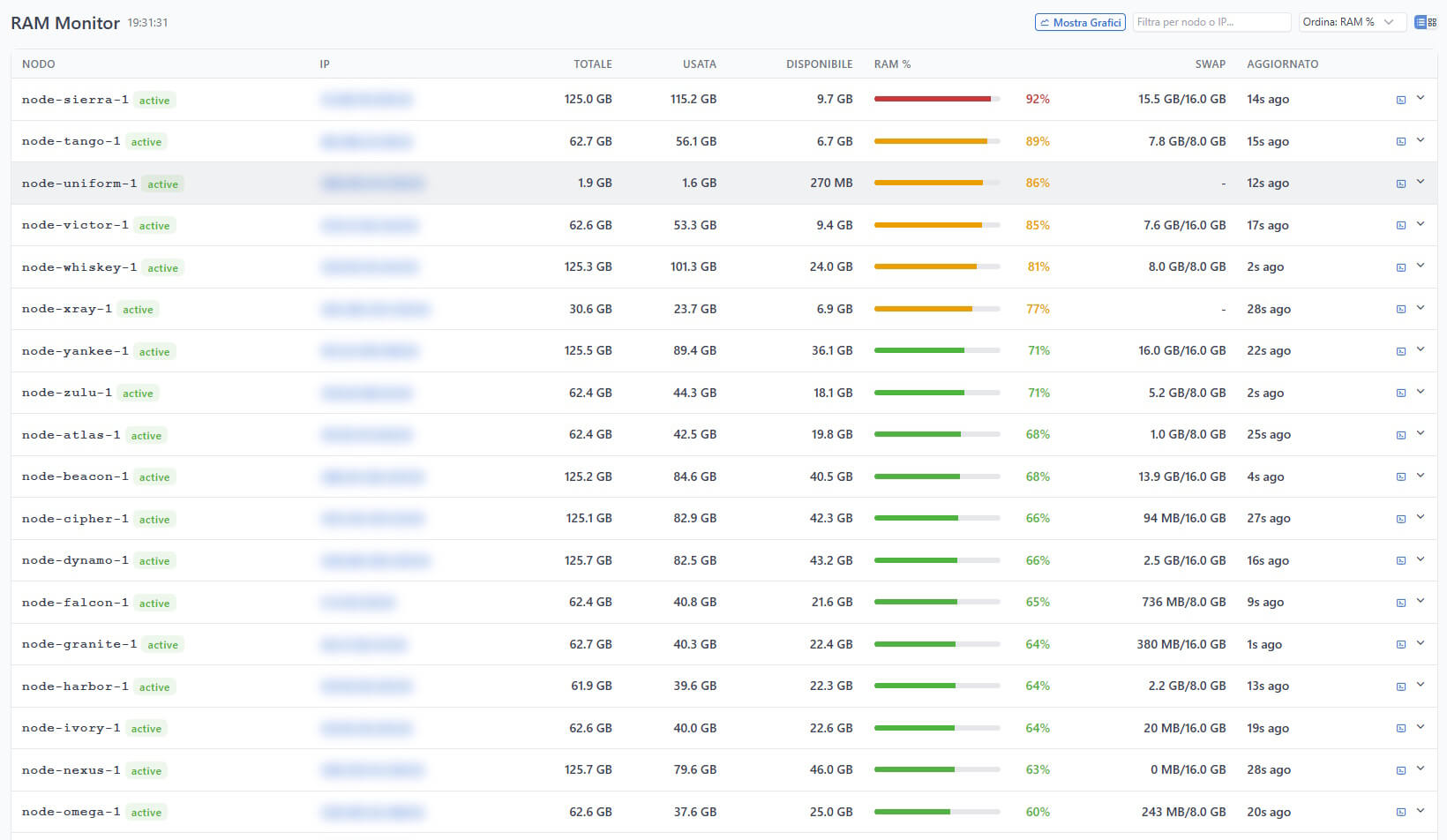
Questo ci ha permesso di identificare rapidamente server con memory leak, processi fuori controllo o configurazioni swap inadeguate — tutto da un’unica interfaccia.
HDD Monitor (Salute dei Dischi)
Qui l’agent fa qualcosa di particolarmente intelligente: rileva automaticamente il sottosistema disco in uso e ne monitora lo stato di salute:
- Array RAID (mdadm): stato dell’array, dischi attivi, dischi degradati/falliti
- Pool ZFS: stato del pool, stato dei vdev, errori di read/write/checksum
- Dischi singoli: informazioni SMART (se disponibili)
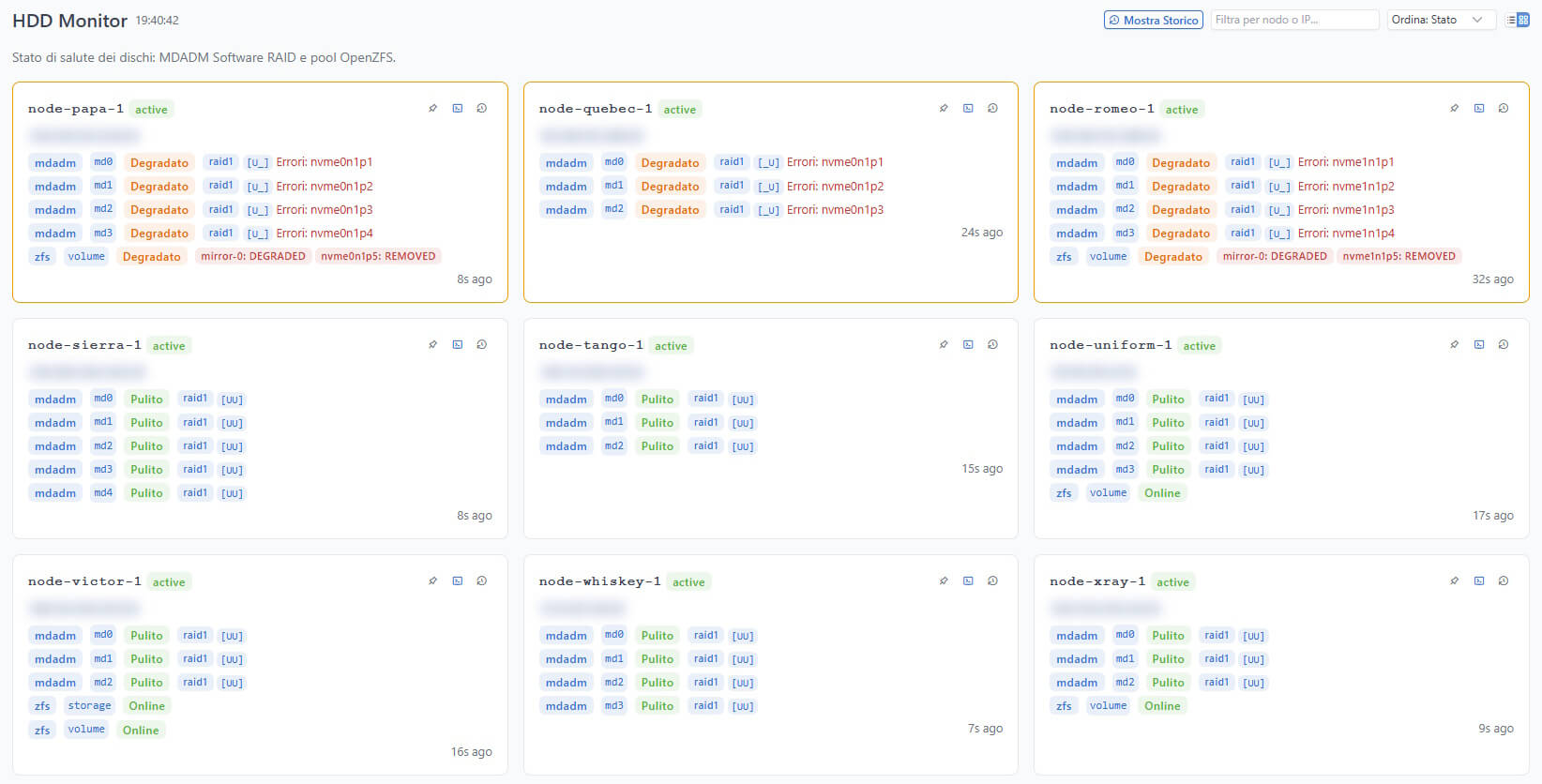
La pagina mostra lo stato con badge colorati:
- Healthy (verde): tutto ok
- Degraded (giallo): attenzione necessaria
- Failed (rosso): intervento urgente
Per ogni nodo potete espandere i dettagli per vedere esattamente quale disco o quale array ha problemi.
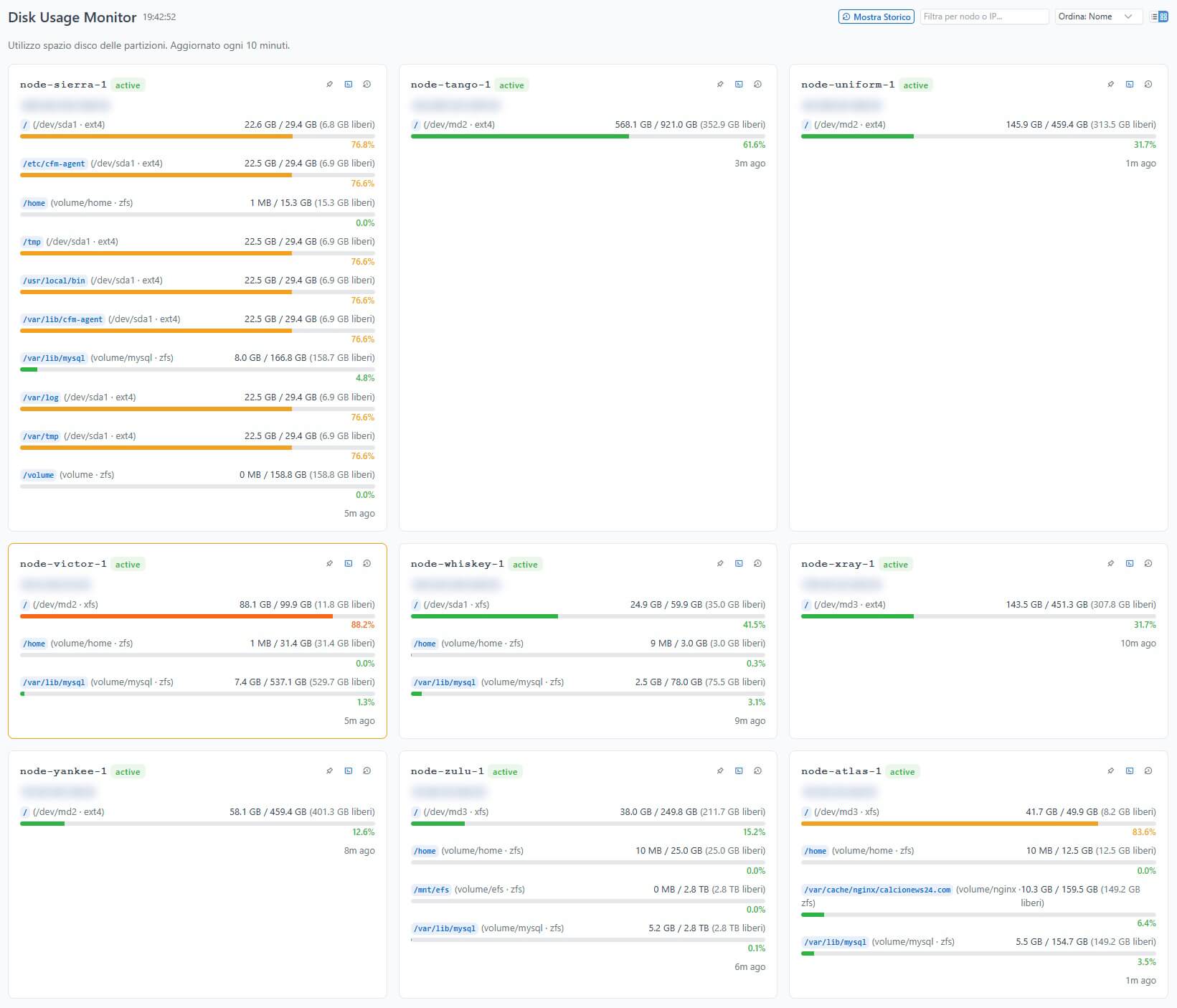
Disk Monitor (Spazio su Disco)
Complementare al HDD Monitor, il Disk Monitor mostra l’utilizzo delle partizioni:
- Device, mount point, filesystem type
- Spazio totale, usato, libero (in MB/GB)
- Percentuale di utilizzo con barre di progresso colorate
- Grafici storici per tracciare la crescita dello spazio utilizzato nel tempo
I dati vengono raccolti dall’agent ogni 10 minuti e permettono di prevedere quando uno spazio disco si esaurirà, prima che diventi un’emergenza.
Net Monitor (I/O di Rete)
L’agent raccoglie statistiche per ogni interfaccia di rete:
- Byte ricevuti (RX) e trasmessi (TX)
- Errori RX e TX
- Delta tra le letture successive
I grafici mostrano il throughput nel tempo per ogni interfaccia, permettendo di identificare rapidamente saturazioni di banda, picchi anomali o interfacce con errori.
Traffic (Statistiche Firewall)
Questa è la funzionalità che lega il monitoring al firewall. L’agent raccoglie i contatori iptables (iptables -L <chain> -v -n -x) per tutte le catene CFM e calcola i delta tra le letture.
La pagina Traffic offre:
- Card riepilogative: pacchetti e byte totali processati
- Grafico storico: linea temporale con range da 1 ora a 7 giorni
- Top nodi per traffico firewall
- Dettaglio per nodo con grafico a barre delle catene individuali
Questo vi dice non solo quanto traffico stanno bloccando le vostre regole, ma anche quali regole stanno lavorando di più e su quali nodi. La retention dei dati di traffico è di 30 giorni, sufficienti per analisi di trend.
La pagina Traffic Nodes offre la stessa informazione ma organizzata per nodo, con grafici espandibili per ognuno e gli stessi controlli di range temporale (1h, 3h, 6h, 12h, 24h, 3 giorni, 7 giorni) + toggle Live.
Il Sistema di Alerting
Monitorare è utile. Essere avvisati automaticamente quando qualcosa va storto è essenziale.
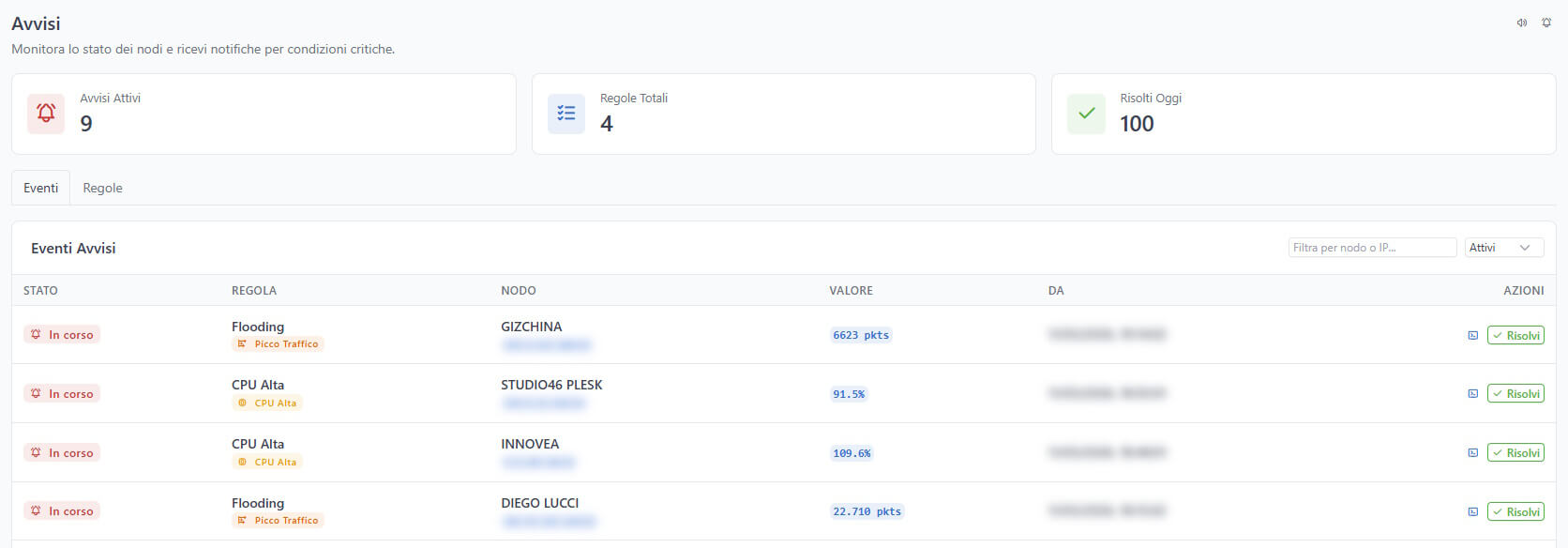
CFM include un sistema di alerting avanzato con anti-storm integrato:
Tipi di Alert
- Node Offline: un nodo non comunica da più di X minuti
- CPU High: il load average supera una soglia per un periodo prolungato
- Traffic Spike: picco anomalo di traffico firewall
- RAID Degraded: un array RAID o un pool ZFS non è in stato ottimale
Configurazione delle Regole
Per ogni tipo di alert potete configurare:
- Nome descrittivo
- Soglia (threshold) specifica per il tipo
- Durata (quanti minuti consecutivi la condizione deve essere vera prima di scatenare l’alert — anti-flapping)
- Cooldown (quanti minuti aspettare dopo un alert prima di inviarne un altro — anti-storm)
- Ambito: tutti i nodi o un nodo specifico
- Notifica di recovery: opzionale, vi avvisa quando la condizione rientra nella norma
Canali di Notifica
Le notifiche possono essere inviate tramite:
- Telegram: il canale preferito dal team — immediato, con supporto per formattazione e emoji
- Email: per notifiche formali e tracciabilità
- Webhook: per integrazioni con sistemi esterni (Slack, Discord, PagerDuty, o qualsiasi endpoint HTTP personalizzato)
Ogni canale può essere configurato per ricevere solo determinati tipi di eventi.
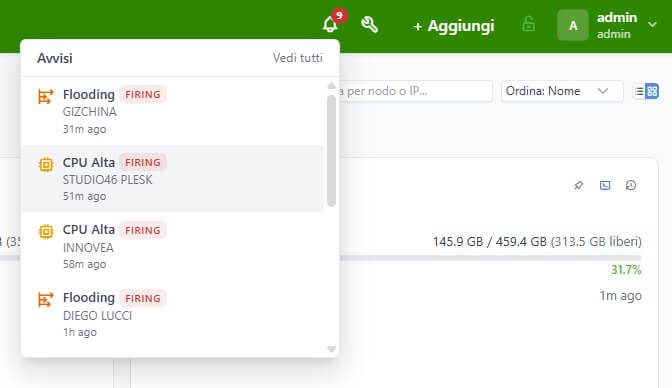
L’Icona a Campanella
Nella topbar di CFM, un’icona a campanella mostra in tempo reale il numero di alert attivi con un badge rosso. Passandoci sopra, un dropdown mostra gli ultimi alert con icone per tipo, nome del nodo coinvolto e tempo trascorso. Un click su “Vedi tutti” porta alla pagina completa degli alert con storico e timeline.
Il Toolkit: la War Room del sistemista
La pagina Toolkit è quella che apriamo per prima quando arriva una segnalazione. È un vero e proprio centro di intelligence operativa integrato direttamente in CFM.
Quick Intel
Inserite un IP e in un istante ottenete:
- Reverse DNS (rDNS)
- GeoIP: paese con bandiera, codice ISO
- ASN: numero e nome dell’organizzazione
- Prefix IP di appartenenza
- DNSBL Status: quante blacklist contengono quell’IP (con colori: verde = pulito, giallo = qualche segnalazione, rosso = ampiamente segnalato)
- Stato CFM: l’IP è in whitelist? È bloccato? Da quale regola? È bloccato per un gruppo specifico?
Strumenti di Analisi
Una serie di tab fornisce strumenti di indagine approfondita:
| Strumento | Descrizione |
|---|---|
| WHOIS | Informazioni di registrazione del dominio/IP |
| DNS | Query per record A, AAAA, MX, NS, TXT, SOA, CNAME, PTR con selettore tipo |
| Ping | Test ICMP echo con tempi di risposta |
| Traceroute | Traccia il percorso di rete verso il target |
| Port Scan | Scansione delle porte principali (22, 80, 443, 8080, 3306, ecc.) |
| DNSBL | Verifica contro 50+ blacklist |
| DNSBL Extended | Blacklist aggiuntive |
| HTTP Headers | Header di risposta HTTP del target |
| SSL/TLS Info | Dettagli del certificato e della catena |
| AbuseIPDB | Report di abuso e punteggio di affidabilità |
| CIDR Info | Espansione di un range IP in set CIDR minimale |
| Reverse IP | Domini ospitati sullo stesso IP |
| BGP Info | Informazioni di routing BGP |
| ASN Lookup | Risoluzione ASN in nome e prefix |
| Log Search | Ricerca nei log di traffico dei nodi per quell’IP |
Azioni Rapide
Dalla stessa pagina, senza navigare altrove, potete:
- Quick Block: aggiungere l’IP alla policy globale con motivazione e durata
- Quick Whitelist: aggiungere l’IP alla whitelist globale
- Quick Block ASN: bloccare l’intero ASN dell’IP
- Quick Whitelist ASN: whitelistare l’intero ASN
Il Toolkit supporta anche il deep linking: https://cfm.example.com/toolkit#192.168.1.1 apre direttamente il toolkit con quell’IP pre-compilato e l’analisi già avviata. Perfetto per integrazioni con altri strumenti o per condividere link nel team.
Il Client SSH Web: accesso in un click
E qui arriviamo a una delle funzionalità che ci ha cambiato la vita quotidiana.
Il problema
Quando un alert arriva, la prima cosa che volete fare è entrare sul server per indagare. Ma questo significava: aprire un terminale, cercare l’hostname, ricordare (o cercare) le credenziali, digitare il comando SSH, inserire la password, e finalmente essere operativi. Moltiplicate per i 10-15 server che potreste dover controllare durante un incidente, e avete un workflow che rallenta enormemente la risposta.
La soluzione
CFM integra un client SSH web completo basato su xterm.js. Dalla pagina di dettaglio di qualsiasi nodo, un click sull’icona terminale apre una finestra popup con un vero terminale SSH nel browser.
Ma la parte migliore è il Vault. Ogni nodo può avere delle credenziali SSH salvate in un vault protetto da una master key. Una volta sbloccato il vault (inserite la master key una volta per sessione), potete connettervi a qualsiasi server con un singolo click — le credenziali vengono iniettate automaticamente e la connessione parte immediatamente.
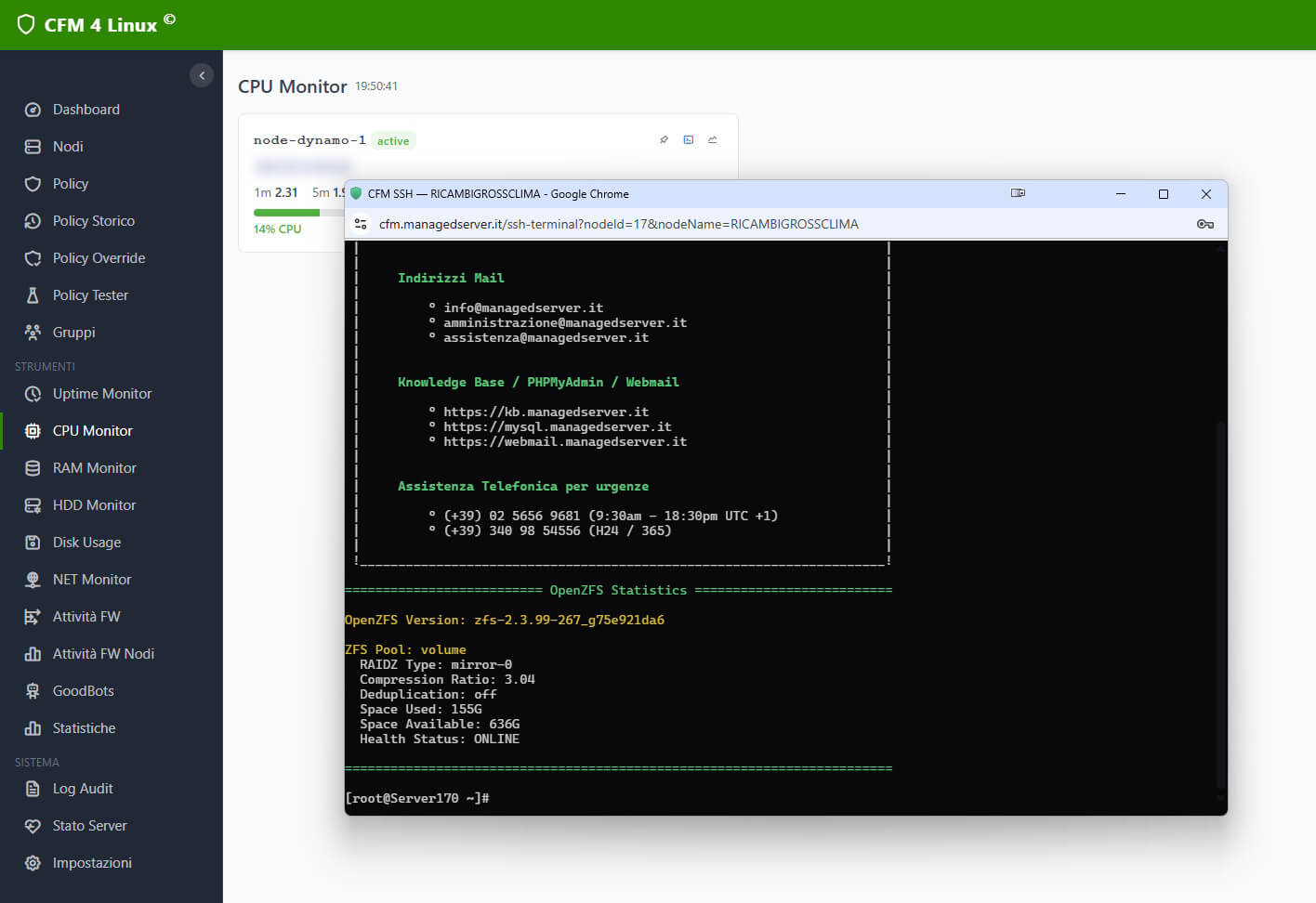
Le credenziali non transitano mai in chiaro nel localStorage del browser: vengono decifrate lato server e passate via URL alla finestra popup, dove vengono immediatamente rimosse dalla barra degli indirizzi per sicurezza.
Sessioni Multiple
Potete avere più terminali SSH aperti contemporaneamente. Ogni sessione è rappresentata da una floating bar nella parte bassa della pagina, con il nome del nodo. Le bar si allineano side-by-side e permettono di:
- Cliccare per portare in foreground la finestra corrispondente
- Chiudere la sessione con il pulsante X
- Mantenere la sessione attiva mentre navigate tra le pagine di CFM
Il sistema utilizza heartbeat via localStorage con una logica a due livelli: riferimento alla finestra come segnale primario (immune al throttling dei timer del browser) e timeout heartbeat a 30 secondi come rete di sicurezza. Questo garantisce che le floating bar rimangano visibili anche quando i popup sono in background.
Good Bots: il problema dei bot “buoni”
Non tutti i bot sono cattivi. Google, Bing, Cloudflare, UptimeRobot e molti altri servizi legittimi utilizzano bot per indicizzare, monitorare e servire il web. Bloccarli significherebbe sparire dai motori di ricerca o interrompere servizi di monitoraggio essenziali.
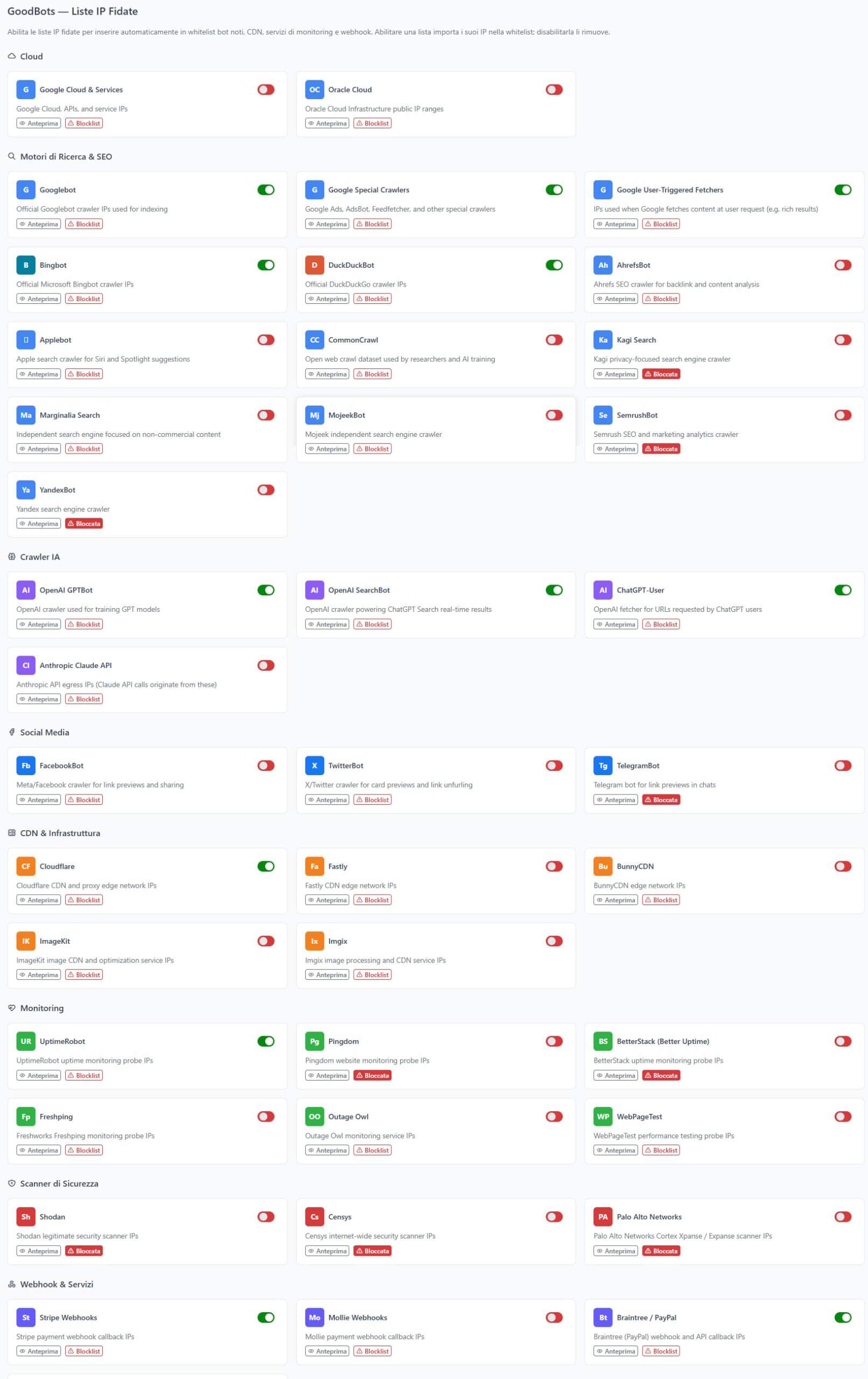
CFM include una sezione Good Bots con una lista pre-curata di bot legittimi organizzati per categoria:
- Motori di ricerca: Google, Bing, Yandex, DuckDuckGo, Baidu
- Social media: Facebook, Twitter, LinkedIn, Pinterest
- CDN: Cloudflare, Fastly, Akamai
- Monitoring: UptimeRobot, Pingdom, StatusCake
- Webhook: Stripe, PayPal, GitHub
- AI (i “buoni”): OpenAI (per le integrazioni API, non il crawler), Anthropic
- Cloud: AWS, Azure, Google Cloud (health checks, load balancer)
- Security: Let’s Encrypt, CertBot
Questa funzionalità vi permette di implementare una strategia “block all except known good” con la garanzia di non bloccare traffico legittimo essenziale.
Sicurezza: non un pensiero afterthought
La sicurezza di CFM stesso è stata progettata fin dal primo giorno, non aggiunta dopo.
Cloudflare Turnstile
La pagina di login è protetta da Cloudflare Turnstile, il successore di reCAPTCHA. A differenza di reCAPTCHA, Turnstile è orientato alla privacy e non richiede agli utenti di selezionare semafori e autobus. La verifica avviene in modo trasparente.
La configurazione richiede solo Site Key e Secret Key (ottenibili gratuitamente dal pannello Cloudflare). Il sistema è fail-open: se Cloudflare non è raggiungibile, il login funziona comunque (meglio un login senza CAPTCHA che un login impossibile durante un’emergenza).
Autenticazione a Due Fattori (2FA/TOTP)
Ogni utente può (e dovrebbe) attivare l’autenticazione a due fattori basata su TOTP (Time-based One-Time Password). Il setup è guidato:
- Scansionate il QR code con la vostra app preferita (Google Authenticator, Authy, Microsoft Authenticator, 1Password, Bitwarden)
- Inserite il codice di verifica per confermare
- Scaricate i codici di recovery (8 codici monouso, da conservare al sicuro)
Da quel momento, ogni login richiede username + password + codice TOTP.
I codici di recovery possono essere rigenerati in qualsiasi momento e la 2FA può essere disabilitata (richiede il codice TOTP corrente + la password, per prevenire disabilitazioni non autorizzate).
Ruoli e Permessi
CFM implementa un sistema RBAC con tre ruoli:
- Admin: accesso completo, gestione utenti, impostazioni di sistema
- Operator: gestione policy, nodi, monitoring (tutto tranne le impostazioni di sistema)
- Viewer: sola lettura su tutto (perfetto per il team di monitoring o per i clienti)
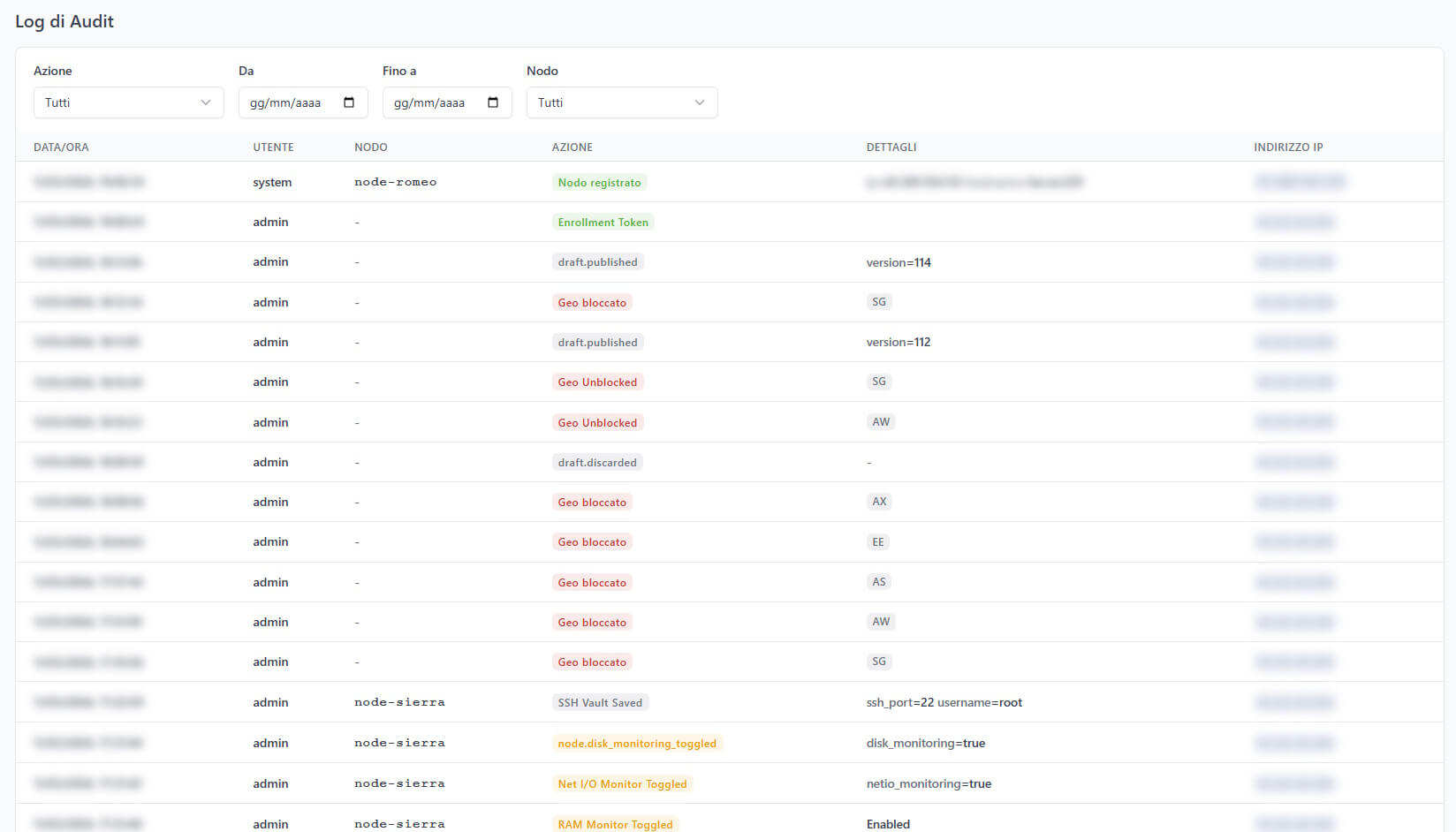
Audit Log Immutabile
Ogni singola azione viene registrata in un log di audit immutabile (protetto da trigger PostgreSQL che impediscono UPDATE e DELETE):
- Chi ha fatto cosa
- Quando
- Da quale IP
- Con quali parametri
Il log è filtrabile per tipo di azione, per data, per nodo e per utente. Supporta paginazione e può gestire milioni di record senza problemi.
Comunicazione Sicura
- Tutta la comunicazione agent-server avviene su HTTPS
- I token di autenticazione sono memorizzati come hash SHA-256 nel database (il token in chiaro non è mai memorizzato)
- Le password degli utenti usano Argon2id (il vincitore della Password Hashing Competition)
- I token di enrollment sono monouso (una volta usati, vengono invalidati)
- L’agent verifica il certificato SSL del server (no MITM)
Protezioni dell’Agent
L’agent stesso implementa diverse protezioni:
- Rifiuto di 0.0.0.0/0: non può mai bloccare tutto il traffico, neanche per errore
- Auto-whitelist server CFM: l’agent non può mai bloccare il proprio server di gestione
- Auto-whitelist interfacce locali: il nodo non può bloccare sé stesso
- Auto-whitelist DNS: i nameserver di sistema e i DNS pubblici (8.8.8.8, 1.1.1.1, 9.9.9.9, ecc.) sono sempre raggiungibili sulla porta 53
- Rollback automatico: se l’applicazione delle regole fallisce, le regole precedenti vengono ripristinate
- Sanitizzazione input: protocolli validati, porte limitate a 0-65535, commenti sanitizzati contro injection
Auto-Update degli Agent
Quando rilasciamo una nuova versione dell’agent, non dobbiamo collegarci a centinaia di server per aggiornarli. L’agent controlla automaticamente ogni ora se è disponibile un aggiornamento, scarica il nuovo binario, verifica l’hash SHA-256 per integrità, e si riavvia con la nuova versione.
Dalla console potete:
- Vedere la versione installata su ogni nodo
- Vedere se è disponibile un aggiornamento
- Forzare l’aggiornamento di tutti i nodi con un click
- Monitorare i log di aggiornamento per ogni nodo
Internazionalizzazione
CFM è completamente localizzato in 5 lingue:
- Italiano
- Inglese
- Spagnolo
- Francese
- Tedesco
La lingua si cambia al volo dal selettore nella topbar e viene salvata in un cookie + localStorage per persistenza.
Statistiche e Analytics
La pagina Statistiche offre grafici Chart.js interattivi:
- Nodi per stato nel tempo: linea temporale di quanti nodi erano attivi, stale, revocati
- Crescita delle regole: come la vostra policy è cresciuta nel tempo
- Distribuzione stato sync: quanti nodi sono sincronizzati vs out-of-sync
- Top CIDR bloccati: classifica dei CIDR più presenti nella policy
Le pagine che usiamo di più (uso reale quotidiano)
Dopo mesi di utilizzo quotidiano, ecco il nostro workflow tipico:
La mattina
- Apriamo la Dashboard per un overview della situazione
- Controlliamo gli Alert (campanella nella topbar) per eventuali problemi notturni
- Una scorsa alla CPU Monitor e RAM Monitor per anomalie
Quando arriva una segnalazione
- Toolkit: inseriamo l’IP segnalato, in 2 secondi sappiamo tutto: da dove viene, a chi appartiene, se è in blacklist, se è già bloccato da noi
- Se va bloccato: Quick Block dal Toolkit → regola applicata su tutti i server in 30 secondi
- Se serve indagare: SSH con un click dal dettaglio nodo
Quando serve un intervento su scala
- Policy: aggiungiamo il range IP o l’ASN
- Oppure: Geo-blocking per bloccare un intero paese
- Oppure: Threat Feeds per abilitare una blocklist automatica
- La policy si propaga automaticamente a tutti i nodi
Per il monitoring proattivo
- Uptime per controllare la disponibilità storica
- Traffic per vedere se c’è qualcosa di anomalo nel traffico firewall
- HDD Monitor per prevenire problemi disco prima che diventino emergenze
- Net Monitor per verificare la banda utilizzata
Stack tecnologico completo
Per chi vuole i dettagli tecnici:
| Componente | Tecnologia |
|---|---|
| Server web | PHP 8.3-FPM + Nginx |
| Database | PostgreSQL 18 |
| UI Framework | Tabler (Bootstrap 5) |
| Grafici | Chart.js |
| Mappe | amCharts 5 |
| Terminale SSH | xterm.js |
| Agent | Go 1.23 (binario statico) |
| Password hashing | Argon2id |
| CAPTCHA | Cloudflare Turnstile |
| 2FA | TOTP (RFC 6238) |
| Firewall backends | iptables, nftables, firewalld |
| Geo database | DB-IP Lite + RIR delegations |
| ASN resolution | RIPEstat API + BGPView |
| IP intelligence | AbuseIPDB |
Il risultato: da ore di lavoro a secondi
Prima di CFM, applicare una regola firewall su tutto il parco macchine significava ore di lavoro manuale con il rischio concreto di errori e dimenticanze.
Oggi, la stessa operazione richiede 30 secondi: inseriamo l’IP nel form, scegliamo l’azione, premiamo Invio. La regola viene automaticamente distribuita a tutti i nodi, applicata con iptables-restore --noflush (senza disturbare nient’altro), e verificata dall’agent che riporta il successo al server.
Se qualcosa va storto, il rollback è automatico. Se abbiamo sbagliato, il versioning ci permette di tornare indietro con un click. Se il cliente chiede “perché il mio IP è bloccato?”, il Policy Tester e l’Audit Log ci danno la risposta in 5 secondi.
CFM ha trasformato la gestione del firewall da un’operazione manuale, rischiosa e che non scala, a un processo centralizzato, automatizzato e con rete di sicurezza integrata.
E il monitoring integrato ha eliminato la necessità di saltare tra 4-5 strumenti diversi: tutto è in un unico posto, con un’unica interfaccia, un unico login.
Cosa ci aspetta
CFM è in continua evoluzione. Nella roadmap abbiamo:
- Rate Limiting: protezione SYN flood e limiti di connessione direttamente dalla console
- Diff visuale delle policy: confronto side-by-side tra versioni con evidenziazione delle differenze
- Implementazione della GeoIP commerciale Max Mind
- IP Reputation Score: punteggio aggregato da multiple fonti di intelligence
- Regole schedulabili: attivazione e disattivazione automatica basata su orario
- API REST pubblica documentata: per integrazioni con sistemi di terze parti
- Multi-tenancy e RBAC granulare: per gestire team e clienti con permessi fine-grained
- Dashboard personalizzabile: widget drag & drop per adattare la vista alle proprie esigenze
- Integrazione Fail2ban: sincronizzazione bidirezionale con le jail Fail2ban esistenti
Conclusione
CFM 4 Linux è nato da un’esigenza reale, dalla frustrazione quotidiana di un team di sistemisti che gestisce centinaia di server sparsi per il mondo. Non è un progetto accademico né un proof of concept: è uno strumento che usiamo ogni giorno, su server di produzione, con clienti reali.
Se anche voi vi trovate a gestire più di una manciata di server Linux e passate troppo tempo a copiare regole iptables da una macchina all’altra, o se siete stanchi di saltare tra cinque strumenti diversi per avere il quadro della situazione, CFM potrebbe essere la risposta che cercavate.
Lo abbiamo costruito per noi stessi. E scopriamo ogni giorno che è esattamente quello di cui avevamo bisogno.
Questo post è stato scritto dal team tecnico di Managedserver.it. CFM 4 Linux è un progetto interno sviluppato per le esigenze operative del nostro team di system administration.
Per domande, curiosità o per sapere se CFM può fare al caso vostro, contattateci a info@managedserver.it.