
Indice dei contenuti dell'articolo:
Il mondo della Search Engine Optimization (SEO) è vasto e in continua evoluzione. Una delle parti più tecniche e spesso trascurate è la gestione del crawling dei motori di ricerca. In questo post, affronteremo un aspetto specifico: l’utilizzo e l’abuso del Crawl Delay, una direttiva che può essere inserita nel file robots.txt per controllare la frequenza con cui i crawler dei motori di ricerca accedono al tuo sito web.
Cos’è un Crawler?
Un crawler, talvolta chiamato spider o bot, è un software automatizzato utilizzato dai motori di ricerca come Google, Bing, Yahoo e altri per navigare nel labirinto del World Wide Web. Il suo scopo principale è esplorare e analizzare i siti web per poterli indicizzare e renderli quindi ricercabili tramite i motori di ricerca. Ma come funziona esattamente un crawler e perché è così fondamentale?
Un crawler inizia il suo lavoro partendo da un insieme di URL noti, chiamati “seed”. Da questi URL iniziali, il crawler esamina il contenuto delle pagine, legge il codice HTML e identifica tutti i link presenti nella pagina. Una volta identificati, questi nuovi URL vengono aggiunti a una coda per essere analizzati successivamente. Questo processo si ripete in modo ricorsivo, permettendo al crawler di scoprire sempre più pagine e di aggiungerle all’indice del motore di ricerca.
Oltre a estrarre i link, i crawler sono in grado di analizzare altri elementi delle pagine web, come meta tag, titoli, immagini e persino contenuti multimediali, per ottenere una comprensione più completa del sito. Questi dati sono poi utilizzati per determinare la rilevanza di una pagina rispetto a una determinata query di ricerca, influenzando quindi il suo posizionamento nei risultati di ricerca.
L’azione dei crawler è fondamentale per la creazione e l’aggiornamento degli indici dei motori di ricerca. Senza il crawling, sarebbe praticamente impossibile per i motori di ricerca fornire risultati aggiornati e pertinenti. Le pagine web, i blog, i forum e tutte le altre forme di contenuto online dipendono dai crawler per essere “scoperti” e quindi resi accessibili agli utenti di Internet attraverso le ricerche.
Rischi di un Crawling Eccessivo
Il processo di crawling è indubbiamente cruciale per garantire che un sito web sia visibile e facilmente accessibile attraverso i motori di ricerca. Tuttavia, un elevato volume di richieste di crawling può rappresentare un problema serio, mettendo a dura prova le capacità del server, soprattutto se quest’ultimo non è ottimizzato o adeguatamente dimensionato per gestire un traffico intenso.
Dimensionamento e Performance
Un server mal dimensionato, con risorse hardware limitate come CPU, memoria e larghezza di banda, è particolarmente vulnerabile all’overload causato da un crawling intensivo. Questo è ancora più vero se l’applicazione web ospitata sul server non è stata ottimizzata per le prestazioni.
Query Lente e Uso Intenso delle Risorse
Fattori come query di database mal progettate o troppo complesse, o un uso eccessivo di risorse per generare dinamicamente una pagina web, possono aggravare ulteriormente la situazione. In un contesto come questo, un crawler che invia un gran numero di richieste in un lasso di tempo molto breve può esacerbare i colli di bottiglia, rallentando drasticamente le prestazioni del server. Questo può portare a tempi di caricamento più lunghi per gli utenti finali e, nel peggiore dei casi, rendere il sito web completamente inaccessibile.
L’Errore 500 e la Sua Importanza
Un sintomo tipico di un server sovraccarico è l’errore HTTP 500, un codice di stato che indica un errore generico e che è spesso segno di problemi interni al server. L’errore 500 può servire come un segnale di allarme, non solo per gli amministratori del sito ma anche per i motori di ricerca. Google, per esempio, è in grado di modulare la frequenza di crawling in risposta a un aumento degli errori 500. Quando il crawler di Google rileva un numero elevato di questi errori, può decidere di ridurre la velocità delle sue richieste per minimizzare l’impatto sul server.
In tal modo, l’errore 500 assume una duplice importanza: da un lato, funge da indicatore per gli amministratori del sito web che qualcosa non va nel sistema; dall’altro, serve come un segnale ai motori di ricerca che potrebbe essere necessario ridurre la frequenza di crawling per evitare ulteriori problemi.
Crawl Delay: Una Soluzione?
Il Crawl Delay è una direttiva che può essere inserita nel file robots.txt del sito. Serve per indicare ai crawler una pausa (espressa in secondi) tra una richiesta e l’altra. Ad esempio, impostando un Crawl Delay di 10 secondi, si dice al crawler di attendere 10 secondi tra una richiesta e la successiva.
User-agent: * Crawl-delay: 10
Quando il Crawl Delay Diventa un Intralcio
Se da un lato l’implementazione del Crawl Delay nel file robots.txt di un sito web può sembrare una strategia efficace per mitigare il rischio di sovraccarico del server dovuto a un’eccessiva attività di crawling, dall’altro lato, questa soluzione può anche presentare delle controindicazioni non trascurabili. Impostare un ritardo nei tempi di crawling significa, di fatto, limitare la quantità di richieste che un crawler può fare in un determinato periodo di tempo. Questo può avere come conseguenza diretta un ritardo nell’indicizzazione delle nuove pagine o nelle modifiche apportate alle pagine già esistenti. In un contesto in cui la velocità con cui un contenuto viene indicizzato può influenzare la sua visibilità e, di conseguenza, il traffico e le conversioni, un Crawl Delay troppo elevato può risultare controproducente.
Per esempio, immagina di aver appena pubblicato un articolo di notizie di attualità o un aggiornamento importante su un prodotto o servizio. In una situazione del genere, vorresti che queste informazioni venissero indicizzate il più rapidamente possibile per massimizzare la visibilità e l’engagement. Un Crawl Delay impostato troppo in alto potrebbe ritardare significativamente questo processo, rendendo le tue informazioni meno competitive o addirittura irrilevanti.
Google, uno dei motori di ricerca più avanzati, ha la capacità di modulare dinamicamente la velocità di scansione in risposta a vari fattori, compresa la stabilità del server da cui provengono le pagine. Se Google rileva un aumento nei codici di errore 500, un segnale che il server potrebbe essere instabile o sovraccarico, il motore di ricerca è programmato per ridurre automaticamente la frequenza delle sue richieste di crawling. Questo è un esempio di come un approccio intelligente e adattivo al crawling possa essere più vantaggioso rispetto a un’impostazione rigida del Crawl Delay, che non tiene conto delle dinamiche variabili che possono influenzare la performance di un sito web.
Crawl Delay Predefiniti: Una Bad Practice
Alcuni servizi di hosting, nell’ottica di ottimizzare le prestazioni e la stabilità dei server, impostano un valore di Crawl Delay predefinito nel file robots.txt dei siti che ospitano. Ad esempio, Siteground, un provider di hosting noto per essere specializzato in soluzioni WordPress orientate alle performance, applica questa limitazione come parte della sua configurazione standard. Sebbene l’intento possa essere quello di preservare le risorse del server e garantire un’esperienza utente fluida, questa pratica è spesso sconsigliata a meno che non ci siano reali e specifiche necessità di limitare le connessioni in ingresso da parte dei crawler.
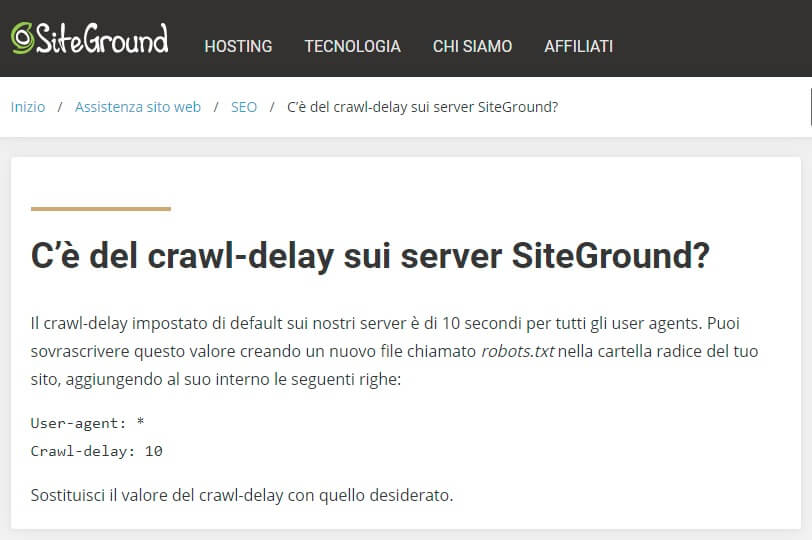
Il motivo è semplice: ogni sito web ha esigenze, dinamiche e obiettivi unici che non possono essere efficacemente indirizzati da una configurazione “taglia unica”. Impostare un Crawl Delay predefinito può, infatti, ostacolare la capacità del sito di essere indicizzato in modo tempestivo, potenzialmente influenzando il posizionamento nei risultati di ricerca e, quindi, la visibilità online. In particolare, per siti che si aggiornano frequentemente o che necessitano di un’indicizzazione rapida per motivi di attualità o stagionalità, una limitazione generica sul crawling potrebbe risultare controproducente.
Inoltre, un Crawl Delay inappropriato può interferire con la capacità dei motori di ricerca di valutare e reagire dinamicamente alle condizioni del sito e del server. Come menzionato in precedenza, Google, ad esempio, è in grado di modulare la sua frequenza di crawling in risposta a un aumento degli errori 500 o altri segnali di instabilità del server. Un Crawl Delay impostato rigidamente potrebbe, quindi, rendere meno efficaci questi meccanismi adattivi.
Quindi, anche se un hosting come Siteground potrebbe avere le migliori intenzioni nel voler preservare le performance del server attraverso un Crawl Delay predefinito, è fondamentale che i gestori dei siti web prendano in considerazione le specifiche esigenze del proprio sito e valutino se una tale impostazione è realmente nel loro interesse.
Impatto sulla SEO
Un’impostazione imprecisa del Crawl Delay può avere gravi conseguenze per la SEO di un sito web. Questo parametro può rallentare e limitare la frequenza con cui i crawler dei motori di ricerca accedono e analizzano il sito. Questa riduzione nella velocità e nella frequenza di scansione può causare ritardi nell’indicizzazione di nuovi contenuti, così come negli aggiornamenti delle pagine web esistenti nel database del motore di ricerca.
Un aspetto spesso sottovalutato è l’effetto del Crawl Delay sul cosiddetto “crawl budget”, che è il numero totale di pagine che un motore di ricerca è disposto a esplorare su un sito specifico entro un certo periodo di tempo. Un Crawl Delay eccessivo potrebbe consumare questo budget molto rapidamente, lasciando alcune pagine inesplorate e quindi non indicizzate. Questo è particolarmente dannoso per i siti con un ampio volume di contenuti che necessitano di una scansione regolare e approfondita.
Inoltre, un Crawl Delay errato potrebbe indurre i crawler a “abbandonare” la fase di recupero dei contenuti, soprattutto se si incontrano difficoltà nell’accedere alle informazioni nel tempo stabilito. Ciò significa che importanti aggiornamenti o nuovi contenuti potrebbero non essere raccolti dai motori di ricerca, compromettendo la visibilità del sito nelle SERP (Search Engine Results Pages).
Questi ritardi e problemi nella fase di crawling e indicizzazione possono portare a una visibilità ridotta nei risultati di ricerca. Questa ridotta visibilità si traduce spesso in un calo del traffico in ingresso e, infine, in un peggioramento del posizionamento nelle SERP. Tutto ciò può avere un effetto a catena negativo sulla competitività del tuo sito web, influenzando negativamente sia il traffico che la conversione e, a lungo termine, il ROI (Return On Investment) delle tue strategie online.
Pertanto, è cruciale utilizzare il Crawl Delay in modo ponderato, tenendo conto sia delle necessità del server che delle implicazioni per la SEO. Prima di fare qualsiasi modifica al tuo file robots.txt, è sempre consigliabile consultare un esperto SEO per una valutazione completa delle esigenze specifiche del tuo sito web.
Conclusioni
La gestione del Crawl Delay è un compito delicato che deve bilanciare le esigenze del server e le esigenze di SEO. È fondamentale considerare attentamente se introdurre questa direttiva, e in caso affermativo, quale valore impostare. Un approccio errato può avere conseguenze negative sia per le performance del server sia per la SEO.
Se il tuo server è già ottimizzato e l’applicazione è performante, la regolazione del Crawl Delay potrebbe non essere necessaria. In ogni caso, è sempre una buona idea monitorare costantemente le performance del server e l’attività dei crawler attraverso strumenti come Google Search Console o log del server, per prendere decisioni informate.
Ricordate, il Crawl Delay è solo un tassello nel complesso mosaico della SEO e delle performance del sito. Dovrebbe essere utilizzato con saggezza e in combinazione con altre best practice per assicurare una presenza online forte e sostenibile.