
Indice dei contenuti dell'articolo:
Uno degli aspetti più frustranti nell’essere sistemisti è quello di doversi sporcare le mani in lavori che dovrebbero fare altre figure professionali.
Può succedere infatti che dopo aver consegnato un server ben dimensionato sull’hardware e ben configurato a livello software che il cliente si lamenti delle performance assolutamente inadeguate dell’applicativo che ci gira sopra.
Sia esso possa essere un CMS custom, che un CRM custom, che qualsiasi altra applicazione Web commissionata e sviluppata su misura delle esigenze del cliente, la sostanza è che il software non gira come dovrebbe girare.
Spesso dopo le iniziali e pacate lamentele, all’aggravarsi e protrarsi della situazione si arriva ad esclamare con tono seccato che “Non funziona niente” spesso con epiteti, tono e terminologie da bar del porto.
Dopo una normale e pacata risposta in cui si evidenzia come quella configurazione sia più che adeguata alle necessità del cliente, si arriva all’invito del cliente a confrontarsi con lo sviluppatore del software perchè qualcosa forse è sfuggito di mano ed essendo un’applicazione custom senza casi specifici e documentati (in quanto il software non essendo conosciuto ne tanto meno diffuso) potrebbe presentare criticità a noi ovviamente sconosciute e non imputabili.
Ovviamente per il programmatore, nel 99% dei casi di questo tipo, il problema non è mai nel suo software, ma sempre attribuibile al sistemista che non sa configurare un server.
Ed ecco qui, la più temuta delle battaglie : Sistemista contro sviluppatore.
Il sistemista di norma è una cintura nera decimo dan, di UNIX, ha molto probabilmente un passato da sviluppatore e da DBA. E’ il potenziale Bruce Lee in grado di stenderti con un colpo che preferisce SEMPRE sottrarsi alla sfida, per mancanza di tempo ma sopratutto competenze.
E sia chiaro, che per competenze, non si intendono le competenze teoriche e pratiche o accademiche di poter analizzare brillantemente il problema e conseguente di risolverlo, ma semplicemente non è di sua competenza, ovvero che quel compito è stato affidato ad un altra stimata figura di un’altra azienda che viene profumatamente pagata per progettare e sviluppare software funzionante e ben ottimizzato.
Peccato che nella triste vita dell’informatico e sopratutto del sistemista, lo scaricabarile è sempre dietro l’angolo e quindi se non accetti la sfida all’ultimo sangue sarai sempre etichettato come colui che non sa fare il proprio lavoro, nonchè perderai il cliente che andrà su qualche altra azienda venditrice di fumo fino a quando qualche sistemista cintura nera deciderà di sporcarsi le mani e dimostrare una volta per tutte che tutti i problemi sono derivati da una pessima implementazione software.
Non solo avrai salvato la vita al tuo cliente che si sarebbe trovato con un software inutilizzabile, ma anche al programmatore che grazie ai tuoi consigli e ai tuoi interventi avrà goduto di una miglioria al suo software che potrà magari rivendere anche ad altri clienti.
La verità? Non sapete usare MySQL e tantomeno SQL in generale.
Emerge un interessante fenomeno tra molti sviluppatori LAMP (acronimo che indica la combinazione di tecnologie Linux, Apache, MySQL, PHP): una scarsa o superficiale conoscenza dell’utilizzo di MySQL. Nonostante MySQL abbia raggiunto l’ottava versione, con un insieme di caratteristiche e funzionalità che potrebbe mettere in competizione con SQL Server di Microsoft, PostgreSQL o Oracle, si osserva che una significativa parte degli sviluppatori continua a utilizzarlo come se fosse ancora alla versione 3.23.
Questa versione, risalente al lontano 2001, non supportava caratteristiche avanzate come i vincoli di integrità referenziale, stored procedure, stored functions, triggers, views o transazioni, che oggi sono disponibili e costituiscono potenti strumenti per la gestione e l’analisi dei dati. Pertanto, molti sviluppatori non sfruttano pienamente il potenziale offerto da MySQL, limitandosi ad utilizzarlo in maniera antiquata e non ottimale.
È importante ricordare a questi sviluppatori che l’epoca in cui MySQL era limitato nelle sue capacità è ormai superata. Il motore MyISAM, che caratterizzava la versione 3.23, è stato sostituito da InnoDB, notevolmente più capace e adatto a un utilizzo professionale. Inoltre, sono stati sviluppati fork di MySQL, come XtraDB di Percona Server, che hanno ulteriormente potenziato le sue capacità, rendendolo un DBMS (Database Management System) relazionale estremamente potente.
È quindi fondamentale che gli sviluppatori si aggiornino e si formino in modo adeguato per sfruttare appieno le potenzialità offerte da MySQL. Questo miglioramento nelle competenze non solo permetterà di creare applicazioni più efficienti e robuste, ma anche di mantenere un passo più in linea con l’evoluzione del campo dell’ingegneria del software, che è in continua evoluzione.
Personalmente non abbiamo nulla contro MySQL o MariaDB, ma attualmente abbiamo uniformato praticamente tutti i nostri server con Percona Server che ha anche tool accessori come le Percona Utilities o Percona Xtrabackup per fare backup a caldo in maniera molto più veloce, sicura, consistente ed efficente del solito banale mysqldump.
Per fare un esempio spicciolo, un programmatore oggi è convinto che un DMBS come MySQL sia una semplice cassettiera in cui depositare e recuperare dei dati. In parole povere utilizzano un DBMS potentissimo (e dunque pesante) come se fosse quasi un DB NO-SQL e dunque leggero.

Un DBMS come MySQL oggi è invece è più paragonabile ad una evoluta linea di produzione industriale che ad una banalissima cassettiera. Per intenderci insomma quelle grosse catene di produzione di caramelle, dove messi in ingresso 3 ingredienti principali e un colorante, alla fine della giostra escono pacchetti di orsetti gommosi, tagliati, mischiati, imballati e pronti da caricare sui camion per le consegne.

Ad esempio pochi sviluppatori LAMP sanno che MySQL è potentissimo e permette di gestire gran parte delle operazioni che si fanno a livello applicativo, direttamente a livello DB visto che MySQL stesso dispone di un linguaggio di programmazione interno.
Vediamo alcune delle principali mancanze o delle bad practices di chi sviluppa applicativi Web utilizzando MySQL.
La seguente lettura potrà trasformare un qualsiasi peracottaio ex disoccupato riciclatosi sviluppatore Web in un buon sviluppatore e magari anche un buon DBA qualora si prosegua su quella strada.
1. Chiavi Esterne e integrità referenziale
Esiste un’opinione comune, soprattutto tra i programmatori che si affidano esclusivamente al linguaggio di programmazione PHP, che per eliminare dati interconnessi in un database, la sola strada sia procedere attraverso il livello dell’applicazione. Questa convinzione li spinge a implementare un processo in cui interrogano i dati che desiderano eliminare, li cancellano uno ad uno, e solo in seguito risalgono alla tabella genitore per rimuovere l’elemento originario. Essi sostengono un’opinione simile anche nel caso in cui si desideri utilizzare una formula matematica per eseguire un calcolo complesso: a loro avviso, questa operazione dovrebbe essere eseguita esclusivamente da PHP, che produrrà un risultato che sarà poi memorizzato nel database.
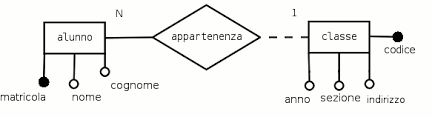
Tuttavia, ciò che spesso non viene considerato è la potenza delle chiavi esterne e delle funzionalità di integrità referenziale presenti nei Relational Database Management Systems (RDBMS). Ad esempio, se si volesse cancellare un artista e tutti i suoi album da un’ipotetica base di dati di archivio musicale, si potrebbe utilizzare l’azione ON CASCADE DELETE. Questa funzionalità permette di effettuare una cancellazione referenziata al cancellamento della foreign key corrispondente, evitando di dover rimuovere singolarmente ciascun valore collegato.
In un contesto RDBMS, l’integrità referenziale rappresenta un vincolo di integrità interrelazionale, che richiede che ogni valore di un attributo (o colonna) di una relazione (o tabella) sia presente come valore di un altro attributo in un’altra relazione. In parole più semplici, nei database relazionali, per mantenere l’integrità referenziale, ogni campo in una tabella che è stato dichiarato come chiave esterna può contenere solo valori che corrispondono alla chiave primaria o a una chiave candidata di un’altra tabella collegata.
Per illustrare questo concetto, consideriamo il caso in cui si desideri eliminare un record che contiene un valore a cui fa riferimento una chiave esterna di un’altra tabella. Questa azione violerebbe l’integrità referenziale. Tuttavia, alcuni RDBMS possono prevenire questa violazione, o eliminando le righe corrispondenti della chiave esterna, oppure interrompendo l’operazione e non procedendo con la cancellazione. Questo serve a preservare l’integrità dei dati nel database, sottolineando l’importanza delle chiavi esterne e dell’integrità referenziale.
2. Stored Procedure
Le stored procedures, o procedure memorizzate, sono una delle caratteristiche fondamentali di molti Relational Database Management Systems (RDBMS). Questa funzionalità, precedentemente mancante in versioni antecedenti alla 5.0 di MySQL, è stata infine implementata, rispondendo così alle critiche di molti utenti di questa piattaforma.
Una stored procedure può essere definita come una serie di istruzioni SQL che sono salvate direttamente nel database con un nome univoco per identificarle. Questo nome consente di richiamare ed eseguire l’intero gruppo di istruzioni, eliminando la necessità di scrivere nuovamente l’intero codice ogni volta che la stessa operazione deve essere eseguita.
Una stored procedure può avere uno o più parametri, che servono a personalizzare l’operazione che la procedura esegue. Ciascun parametro ha un nome specifico, un tipo di dato definito e può essere categorizzato come parametro di input, di output o entrambi. Se non viene specificato, il parametro viene considerato di default come parametro di input.
Le stored procedures offrono una serie di vantaggi. Prima di tutto, possono aiutare a ridurre il traffico di rete, dal momento che una singola chiamata alla procedura sostituisce la necessità di inviare molteplici query. Inoltre, poiché il codice viene eseguito direttamente nel database, la stored procedure può essere più veloce rispetto a un gruppo equivalente di istruzioni SQL eseguite individualmente. Infine, l’utilizzo delle stored procedures può contribuire a migliorare la sicurezza, dal momento che le procedure memorizzate offrono un livello di astrazione che nasconde i dettagli del database.
3. Stored Functions
Le stored functions, o funzioni memorizzate, condividono alcune similitudini con le stored procedures in un database, ma hanno uno scopo specifico più limitato. Mentre una stored procedure è un gruppo di istruzioni SQL che può eseguire operazioni complesse, una stored function è progettata per eseguire un’operazione specifica e restituire un singolo valore.
In pratica, una stored function funziona esattamente come una funzione ordinaria fornita da MySQL o da un altro RDBMS. Queste funzioni prendono uno o più parametri, eseguono un’operazione e restituiscono un risultato. Ad esempio, potrebbero calcolare la somma di una serie di numeri, restituire la lunghezza di una stringa di testo o eseguire un calcolo più complesso basato sui dati presenti nel database.
A differenza delle stored procedures, tuttavia, le stored functions non possono restituire un resultset, ovvero un insieme di righe restituite da una query SELECT. Invece, restituiscono un singolo valore di un tipo di dato specifico, come un numero intero, un float, una stringa o una data.
Nelle versioni di MySQL precedenti alla 5.0, esistevano le “user-defined functions” che venivano memorizzate esternamente al server. Queste funzioni personalizzate dell’utente permettevano agli sviluppatori di creare le proprie funzioni e di utilizzarle nelle loro query SQL. Tuttavia, a partire dalla versione 5.0, MySQL ha introdotto le stored functions, che sono memorizzate direttamente nel database.
Mentre le user-defined functions sono ancora supportate in MySQL, l’uso delle stored functions è generalmente consigliato. Questo perché le stored functions possono trarre vantaggio da alcune delle ottimizzazioni di MySQL e hanno meno restrizioni rispetto alle user-defined functions. Ad esempio, una stored function può accedere a tabelle, variabili di sessione e altre risorse del database, mentre una user-defined function ha limiti più stringenti su ciò che può fare.
In sostanza, le stored functions forniscono un modo potente ed efficiente per incapsulare la logica di business all’interno del database, permettendo agli sviluppatori di scrivere codice più pulito e più mantenibile.
4. Triggers
I triggers sono oggetti speciali presenti nei database relazionali, strettamente associati a tabelle specifiche, che si attivano o “scattano” in risposta a determinati eventi. Questa funzionalità è stata introdotta in MySQL a partire dalla versione 5.0.2.
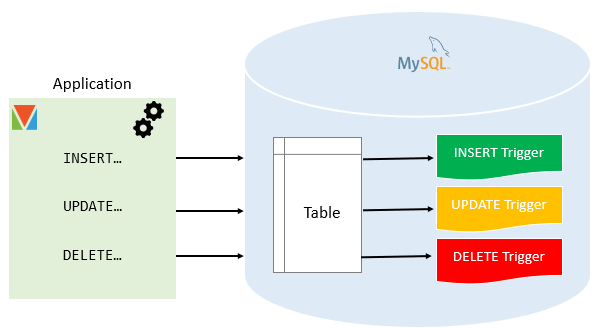
Un trigger può essere definito per rispondere a una varietà di eventi che riguardano la tabella con cui è associato, come l’inserimento di nuove righe, la modifica di righe esistenti o la cancellazione di righe. Un trigger può essere configurato per scattare prima (BEFORE) o dopo (AFTER) che l’evento si verifichi. Quindi, abbiamo sei tipi di trigger distinti:
- BEFORE INSERT
- AFTER INSERT
- BEFORE UPDATE
- AFTER UPDATE
- BEFORE DELETE
- AFTER DELETE
Ogni trigger è associato a un’istruzione SQL o a un blocco di istruzioni che vengono eseguite automaticamente per ogni riga che subisce l’evento. In altre parole, un trigger è un meccanismo che consente di definire una risposta automatica a un evento specifico. Questa risposta può consistere in una varietà di azioni, come l’aggiornamento di un valore in una colonna specifica, l’inserimento di una nuova riga in un’altra tabella o la registrazione dell’evento in un log.
Prendiamo un esempio pratico. Supponiamo di voler tenere traccia del totale venduto da un agente di vendita in un dato mese. Potremmo creare un trigger che risponde all’evento “inserimento di una nuova riga” sulla tabella “ordini”. Quando viene inserito un nuovo ordine, il trigger calcola automaticamente la somma totale degli ordini del mese corrente per l’agente specifico e aggiorna il valore nella tabella “totale_vendite_mensili”. In questo modo, non avremmo bisogno di eseguire una query SELECT ogni volta che vogliamo sapere il totale delle vendite del mese per un agente, poiché il valore sarebbe precalcolato e immediatamente disponibile.
I trigger possono notevolmente semplificare la logica delle applicazioni, poiché automatizzano le operazioni che altrimenti dovrebbero essere eseguite manualmente. Tuttavia, dovrebbero essere usati con attenzione, poiché possono complicare il debug e la manutenzione del database se non gestiti correttamente.
5. Views o Viste
Le views, o viste, in un database rappresentano una prospettiva virtualizzata su un sottoinsieme di dati contenuti in una o più tabelle. Tradotte letteralmente dal termine inglese “view”, che significa “vista”, le views non memorizzano fisicamente i dati, ma offrono una presentazione tabulare di righe e colonne derivata dall’esecuzione di una specifica query SQL. Le viste funzionano come se fossero tabelle “reali”, consentendo di eseguire operazioni come SELECT, UPDATE, INSERT o DELETE, a seconda dei permessi e delle restrizioni impostate.
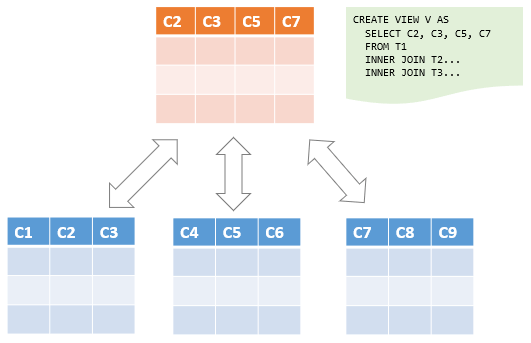
La creazione di una vista implica la definizione di una query che “seleziona” un sottoinsieme di dati da una o più tabelle. Questa query è memorizzata come parte della definizione della vista e viene eseguita ogni volta che la vista viene richiamata. In pratica, una vista funziona come una finestra su un insieme specifico di dati, filtrando o riorganizzando le informazioni in base alle esigenze specifiche dell’utente o dell’applicazione.
L’uso delle viste presenta numerosi vantaggi. In primo luogo, le viste possono semplificare le operazioni di query, nascondendo la complessità delle operazioni di join, filtro o aggregazione che possono essere coinvolte nella generazione del sottoinsieme di dati. In secondo luogo, le viste possono aiutare a migliorare la sicurezza dei dati, limitando l’accesso a un sottoinsieme di dati e nascondendo dettagli sensibili o irrilevanti. Infine, le viste possono aiutare a mantenere l’integrità dei dati, fornendo un’interfaccia coerente ai dati anche se la struttura sottostante delle tabelle cambia.
Un esempio di vista potrebbe essere una vista “OrdiniClienti” che aggrega informazioni da una tabella “Ordini” e una tabella “Clienti”, mostrando solo i dettagli dell’ordine e le informazioni di base del cliente per ogni ordine. Questa vista potrebbe essere utilizzata da un’applicazione di vendita per visualizzare una lista degli ordini senza dover eseguire manualmente join o filtraggi complessi.
Le viste sono strumenti potenti che consentono di interagire con i dati di un database in modo più semplice, sicuro e gestibile.
6. Transazioni ACID
L’uso delle transazioni nei database è una funzione critica che permette di gestire in modo sicuro e coeso un insieme di operazioni, garantendo che le modifiche ai dati vengano apportate solo in un momento ben definito. Iniziando una transazione, tutte le modifiche o gli aggiornamenti ai dati rimangono in uno stato temporaneo e non definitivo (sospeso) e non sono visibili agli altri utenti. Queste modifiche possono essere poi o confermate attraverso un’operazione nota come “commit”, che rende le modifiche permanenti, oppure annullate attraverso un’operazione nota come “rollback”, che riporta i dati al loro stato originale. Questo concetto è spesso descritto come “tutto o niente”: o tutte le modifiche previste dalla transazione vengono apportate, o nessuna lo viene.

Questo processo di gestione delle transazioni è fondamentale in situazioni in cui è essenziale mantenere la coerenza dei dati. Ad esempio, se si hanno 100 record da inserire in un ordine di un ristorante e l’inserimento si interrompe al 90° a causa di un problema di connessione Wi-Fi, il sistema eseguirà un rollback della transazione, annullando i 90 inserimenti perché non completi rispetto ai 100 totali previsti.
Questo modo di gestire le transazioni segue i principi ACID, un acronimo che sta per Atomicità, Coerenza, Isolamento e Durabilità:
- Atomicità: questo principio garantisce che una transazione sia considerata come un’unità indivisibile di lavoro. O tutte le operazioni della transazione vengono completate con successo, o nessuna lo viene. Se un’operazione all’interno di una transazione fallisce, l’intera transazione viene annullata (rollback).
- Coerenza: questo principio assicura che una transazione porti il database da uno stato coerente a un altro. Se i dati nel database erano coerenti prima della transazione, lo saranno anche dopo, indipendentemente dal successo o dal fallimento della transazione.
- Isolamento: questo principio garantisce che ogni transazione venga eseguita in modo isolato dalle altre transazioni. Questo significa che nessuna transazione può interferire con le altre, e ognuna deve essere completata senza conoscenza delle altre transazioni in corso.
- Durabilità: questo principio garantisce che una volta che una transazione è stata completata, le sue modifiche ai dati persistono nel database, anche in caso di guasto di sistema o crash.
Insieme, questi principi ACID forniscono un framework robusto per la gestione delle transazioni e la garanzia dell’integrità dei dati nei database relazionali.
E non dimentichiamoci delle performance.
Se volessimo parlare di velocità di esecuzione delle query, potremmo affermare come sempre meno sviluppatori LAMP sappiano progettare correttamente una base di dati ed implementare un uso corretto degli indici che sono assolutamente vitali se si vuol ottenere velocità nell’esecuzione delle query stesse.
In parole povere molto spesso applicativi lenti che arrivano al timeout della connessione e persino alla saturazione delle connessioni massime disponibili hanno come unica causa la mancanza di indici sulle tabelle.
Un indice database è una struttura di dati che migliora la velocità delle operazioni in una tabella.
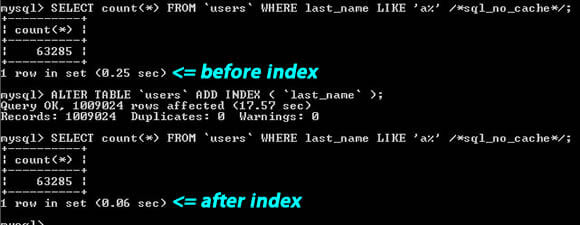
Ogni volta che un’applicazione web invia una query a un database, il database cercherà in tutte le righe della tua tabella per trovare quella che combacia con la tua richiesta. Quando le tabelle del tuo database aumentano, un numero maggiore di righe deve essere ispezionato ogni volta e questo può rallentare le prestazioni del database e quindi dell’applicazione.
Gli indici MySQL risolvono questo problema prendendo i dati da una colonna nella tua tabella e la archiviano alfabeticamente in un punto separato chiamato indice.
Basta che funzioni? No. Deve essere anche veloce.
Sembra che, nel contesto dello sviluppo LAMP (Linux, Apache, MySQL, PHP), uno dei problemi principali risieda nell’equilibrio tra la programmazione PHP e la progettazione e ottimizzazione della base di dati. Osservando le tendenze generali, si nota che gli sviluppatori spesso tendono a concentrarsi maggiormente sulla programmazione PHP, tralasciando l’importanza di una base di dati ben progettata e ottimizzata.
Uno dei motivi di questa tendenza può risiedere in una mancanza di formazione accademica riguardosa, che porta lo sviluppatore a limitarsi a testare il software su dataset molto piccoli e in contesti di scarsa concorrenza. Sotto queste condizioni, è facile concludere che il software funzioni correttamente e che le query restituiscano i risultati attesi. Tuttavia, questo genere di test non è sufficientemente rappresentativo della realtà operativa in cui il software dovrà essere effettivamente utilizzato.
Infatti, è una cosa testare un’applicazione su un dataset di 100 record dimostrativi con un solo utente connesso, ed è un’altra cosa testarla su un dataset di decine di milioni di record con 100 operatori connessi in tempo reale. Quest’ultimo scenario presenta sfide significative in termini di gestione della concorrenza e di efficienza delle operazioni sulla base di dati, sfide che non emergono in un contesto di test limitato.
La morale della storia, quindi, è che “funzionante” non è sufficiente per descrivere un buon software. Un software deve essere non solo funzionale, ma anche efficiente. Deve essere in grado di gestire grandi volumi di dati e un alto numero di utenti connessi contemporaneamente, restituendo risultati rapidamente e senza errori. In altre parole, non basta che funzioni – deve essere anche veloce.
Per raggiungere questi obiettivi, gli sviluppatori devono considerare l’ottimizzazione del database come una parte fondamentale del processo di sviluppo, e non come un aspetto secondario. Questo richiede un impegno in termini di tempo e di formazione, ma il risultato sarà un software più robusto, più efficiente e, in ultima analisi, più utile per gli utenti finali.