
Indice dei contenuti dell'articolo:
Ogni webmaster sa che ci sono alcuni aspetti di un sito web di cui non vuoi eseguire la scansione o l’indicizzazione. Il file robots.txt ti dà l’opportunità di specificare queste sezioni e trasmetterle ai crawler dei motori di ricerca. In questo articolo, mostreremo gli errori comuni che possono verificarsi durante la creazione di un file robots.txt, come evitarli e come monitorare il tuo file robots.txt.
Ci sono molte ragioni per cui gli operatori di siti Web potrebbero voler escludere determinate parti di un sito Web dall’indice dei motori di ricerca, ad esempio se le pagine sono nascoste dietro un accesso, sono archiviate o se si desidera testare le pagine di un sito Web prima che vengano pubblicate. “A Standard for Robot Exclusion” è stato pubblicato nel 1994 per renderlo possibile. Questo protocollo stabilisce le linee guida che prima di iniziare la scansione, il crawler del motore di ricerca dovrebbe prima cercare il file robots.txt nella directory principale e leggere le istruzioni nel file.
Durante la creazione del file robots.txt possono verificarsi molti possibili errori, ad esempio errori di sintassi se un’istruzione non è scritta correttamente o errori derivanti dal blocco involontario di una directory.
Ecco alcuni degli errori robots.txt più comuni:
Errore n. 1: utilizzo di sintassi errata
robots.txt è un semplice file di testo e può essere facilmente creato utilizzando un editor di testo. Una voce nel file robots.txt è sempre composta da due parti: la prima parte specifica l’interprete a cui applicare l’istruzione (es. Googlebot), e la seconda parte contiene comandi, come “Disallow”, e contiene un elenco di tutte le sottopagine di cui non è necessario eseguire la scansione. Affinché le istruzioni nel file robots.txt abbiano effetto, è necessario utilizzare la sintassi corretta come mostrato di seguito.
User-agent: Googlebot Disallow: /example_directory/
Nell’esempio precedente, al crawler di Google è vietato eseguire la scansione della /example_directory/. Se vuoi che questo si applichi a tutti i crawler, dovresti utilizzare il seguente codice nel tuo file robots.txt:
User-agent: * Disallow: /directory_esempio/
L’asterisco (noto anche come jolly) funge da variabile per tutti i crawler. Allo stesso modo, puoi utilizzare una barra (/) per impedire l’indicizzazione dell’intero sito Web (ad esempio per una versione di prova prima di metterlo online in produzione ).
User-agent: * Disallow: /
Errore n. 2: blocco dei componenti del percorso anziché di una directory (dimenticando “/”)
Quando si esclude una directory dalle ricerche per indicizzazione, ricordarsi sempre di aggiungere la barra alla fine del nome della directory. Per esempio,
Disallow: /directory non solo blocca /directory/, ma anche /directory-one.html
Se si desidera escludere più pagine dall’indicizzazione, è necessario aggiungere ciascuna directory in una riga diversa. L’aggiunta di più percorsi nella stessa riga di solito porta a errori indesiderati.
User-agent: googlebot Disallow: /example-directory/ Disallow: /example-directory-2/ Disallow: /example-file.html
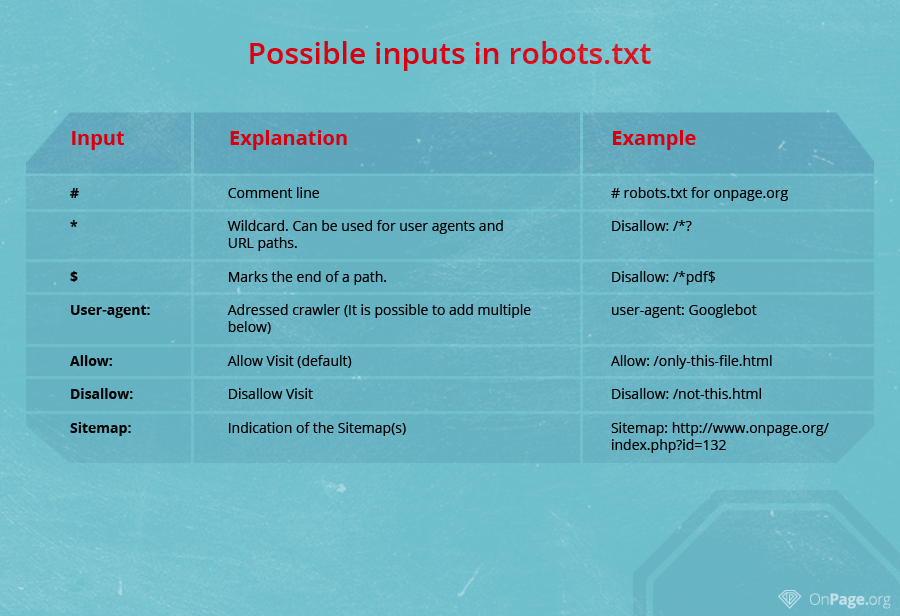
Errore n. 3: blocco involontario delle directory
Prima che il file robots.txt venga caricato nella directory principale del sito web, dovresti sempre controllare se la sua sintassi è corretta. Anche il più piccolo errore potrebbe comportare che il crawler ignori le istruzioni nel file e porti alla scansione di pagine che non dovrebbero essere indicizzate. Assicurati sempre che le directory che non devono essere indicizzate siano elencate dopo il comando Disallow:.
Anche nei casi in cui la struttura della pagina del tuo sito web cambia, ad esempio a causa di un restyle, dovresti sempre controllare se nel file robots.txt sono presenti errori.
Errore n. 4 – Non si salva il file robots.txt nella directory principale
L’errore più comune associato al file robots.txt non riesce a salvare il file nella directory principale del sito web. Le sottodirectory vengono generalmente ignorate poiché gli interpreti cercano solo il file robots.txt nella directory principale.
L’URL corretto per il file robots.txt di un sito web deve avere il seguente formato:
http://www.your-website.com/robots.txt
Errore n. 5: non consentire le pagine con un reindirizzamento
Se le pagine bloccate nel tuo file robots.txt hanno reindirizzamenti ad altre pagine, il crawler potrebbe non riconoscere i reindirizzamenti. Nella peggiore delle ipotesi, ciò potrebbe far sì che la pagina venga ancora visualizzata nei risultati di ricerca ma con un URL errato. Inoltre, anche i dati di Google Analytics per il tuo progetto potrebbero essere errati.
Suggerimento: robots.txt rispetto a noindex
È importante notare che l’esclusione delle pagine nel file robots.txt non implica necessariamente che le pagine non vengano indicizzate. Ad esempio, se un URL escluso dalla scansione nel file robots.txt è collegato a una pagina esterna. Il file robots.txt ti dà semplicemente il controllo sull’agente utente. Tuttavia, al posto della Meta description appare spesso quanto segue poiché al bot è vietato eseguire la scansione:
“Una descrizione per questo risultato non è disponibile a causa del file robots.txt di questo sito.”

Figura 4: Esempio di snippet di una pagina bloccata utilizzando il file robots.txt ma ancora indicizzata
Come puoi vedere, è sufficiente un solo link nella rispettiva pagina per far sì che la pagina venga indicizzata, anche se l’URL è impostato su “Disallow” nel file robots.txt. Allo stesso modo, l’utilizzo del tag <noindex> può, in questo caso, non impedire l’indicizzazione poiché il crawler non è mai riuscito a leggere questa parte del codice a causa del comando disallow nel file robots.txt.
Per impedire la visualizzazione di determinati URL nell’indice di Google, dovresti utilizzare il tag <noindex>, ma consentire comunque al crawler di accedere a questa directory.
Conclusioni
Abbiamo visto ed esaminato molto velocemente quelli che sono i principali errori del file robots.txt che in alcuni casi può compromettere in modo molto significativo la visibilità ed il posizionamento del tuo sito web, arrivando nei casi più gravi fino alla totale eliminazione della SERP.
Se stai pensando di non avere problemi di questo tipo con il file robots.txt perchè conosci bene il suo funzionamento e non faresti mai azioni improvvisate, devi sapere che a volte gli errori nel file robots.txt sono frutto di sviste nella configurazione di CMS come WordPress o anche attacchi malware o azioni di sabotaggio mirate a far perdere indicizzazione e posizionamento al tuo sito.
Il miglior consiglio che possiamo darti è quello di tenere monitorato costantemente il file robots.txt almeno con cadenza settimanale e verificarne la corretta sintassi ed il corretto funzionamento quando avverti dei segnali di allarme come un calo improvviso del traffico o la presenza sulla SERP dei motori di ricerca.