
Indice dei contenuti dell'articolo:
Un piano di disaster recovery rappresenta un componente essenziale nel portfolio di strumenti di gestione di qualsiasi azienda. Il suo ruolo fondamentale è quello di garantire la continuità delle attività commerciali e operative, salvaguardando le organizzazioni da eventi imprevisti e potenzialmente catastrofici che potrebbero interrompere o danneggiare le loro operazioni. Questi eventi possono variare da interruzioni di corrente, incendi, e inondazioni, a attacchi informatici e altri disastri, sia naturali che artificiali.
L’importanza di un piano di disaster recovery si radica nella capacità di prevenire la perdita di dati critici, il fallimento delle operazioni e la conseguente interruzione del servizio, tutti elementi che possono avere un impatto significativo sulla reputazione e sulla stabilità finanziaria dell’azienda. In questo contesto, l’utilizzo di strumenti affidabili per la gestione e la sicurezza dei dati diventa una priorità.
Borg è un’opzione ideale in questo panorama, rappresentando una soluzione Open Source, completamente gratuita e altamente performante per il backup dei dati. Questo strumento consente di creare copie di sicurezza dei dati aziendali in modo efficiente, offrendo un meccanismo di backup semplice ma potente e affidabile.
Una delle caratteristiche distintive di Borg è la sua elevata compressione dei dati e la funzione di deduplicazione. Queste funzionalità consentono di utilizzare al meglio lo spazio di archiviazione disponibile, riducendo significativamente i costi di archiviazione. In un’epoca in cui la gestione efficiente dei dati è sempre più fondamentale, la capacità di Borg di ottimizzare lo spazio di archiviazione rappresenta un enorme vantaggio competitivo.
Inoltre, Borg si distingue per la sua facilità di integrazione con altri sistemi e strumenti. Questa flessibilità lo rende un’ottima scelta per le aziende di qualsiasi dimensione, permettendo una coesione senza soluzione di continuità con le infrastrutture tecnologiche esistenti.
Cos’è Borg
BorgBackup (abbreviazione: Borg) è un programma di backup per la deduplicazione. Facoltativamente, supporta la compressione e la crittografia autenticata.
L’obiettivo principale di Borg è fornire un modo efficiente e sicuro per eseguire il backup dei dati. La tecnica di deduplicazione dei dati utilizzata rende Borg adatto ai backup giornalieri poiché vengono archiviate solo le modifiche. La tecnica di crittografia autenticata lo rende adatto per backup su destinazioni non completamente attendibili.
Consulta il manuale di installazione o, se hai già scaricato Borg, docs/installation.rstper iniziare con Borg. È disponibile anche una documentazione offline , in più formati.
Sui sistemi Linux, hai molte opzioni per creare e mantenere i backup dei tuoi file. Oggi parliamo di un altro strumento che potresti trovare utile: BorgBackup.
BorgBackup, o “Borg” in breve, è un programma di backup che supporta la deduplicazione, la compressione e la crittografia. Borg fornisce un modo efficiente e sicuro per eseguire il backup dei dati.
Caratteristiche principali di Borg Backup
- Archiviazione efficiente in termini di spazio
- Borg Backup è dotato di un’efficace funzione di archiviazione che rende il processo di backup dei dati estremamente efficiente in termini di spazio. Uno dei principali fattori che contribuiscono a questa efficienza è la deduplicazione basata sul chunking definito dal contenuto, una tecnica che aiuta a ridurre significativamente la quantità di dati archiviati.
In termini pratici, questo significa che ogni file, invece di essere archiviato nella sua interezza, viene suddiviso in una serie di blocchi di lunghezza variabile. Solo quei blocchi che non sono mai stati registrati prima nel repository vengono aggiunti, contribuendo così a minimizzare l’uso dello spazio di archiviazione.
Il processo di deduplicazione funziona identificando ciascun blocco con un valore unico, conosciuto come id_hash. Se un blocco con lo stesso id_hash è già stato registrato, Borg non lo aggiunge di nuovo al repository. L’id_hash viene generato utilizzando un hash crittograficamente forte o una funzione MAC, come (hmac-)sha256, garantendo così l’unicità e l’identificabilità di ogni blocco.
Una caratteristica particolarmente distintiva della deduplicazione di Borg è la sua portata universale all’interno di un singolo repository. Borg considera tutti i blocchi nello stesso repository per la deduplicazione, indipendentemente dalla loro origine – che siano da macchine diverse, da backup precedenti, dallo stesso backup, o addirittura dallo stesso singolo file.
Questa tecnologia di deduplicazione non dipende da fattori come la persistenza dei nomi di file o delle directory, o la consistenza dei file completi o dei timestamp. Di conseguenza, puoi spostare o rinominare i tuoi file senza influire sulla deduplicazione, e se un file di grandi dimensioni subisce solo piccole modifiche, Borg dovrà archiviare solo i nuovi blocchi, offrendo un enorme vantaggio per le macchine virtuali o i dischi non elaborati.
Inoltre, Borg non è limitato dalla posizione assoluta di un blocco di dati all’interno di un file. Questo significa che se i dati vengono spostati all’interno di un file, l’algoritmo di deduplicazione di Borg sarà ancora in grado di identificarli. Questa capacità garantisce un’efficienza di deduplicazione superiore, indipendentemente dalla dinamicità dei tuoi dati.
Rispetto ad altri approcci di deduplicazione, questo metodo NON dipende da:
- i nomi di file/directory rimangono gli stessi: così puoi spostare le tue cose senza interrompere la deduplicazione, anche tra macchine che condividono un repository.
- file completi o timestamp rimangono gli stessi: se un file di grandi dimensioni cambia leggermente, è necessario archiviare solo alcuni nuovi blocchi: questo è ottimo per macchine virtuali o dischi non elaborati.
- La posizione assoluta di un blocco di dati all’interno di un file: le cose potrebbero essere spostate e verranno comunque trovate dall’algoritmo di deduplicazione.
- Velocità
-
- il codice critico per le prestazioni (chunking, compressione, crittografia) è implementato in C/Cython
- memorizzazione nella cache locale di file/blocchi di dati dell’indice
- rilevamento rapido di file non modificati
- Crittografia dei dati
- Tutti i dati possono essere protetti utilizzando la crittografia AES a 256 bit, l’integrità e l’autenticità dei dati vengono verificate utilizzando HMAC-SHA256. I dati sono crittografati lato client.
- Offuscazione
- Facoltativamente, borg può offuscare attivamente, ad esempio, la dimensione di file / blocchi per rendere più difficili gli attacchi di fingerprinting.
- Compressione
-
Tutti i dati possono essere opzionalmente compressi:
- lz4 (super veloce, bassa compressione)
- zstd (vasta gamma da alta velocità e bassa compressione a alta compressione e bassa velocità)
- zlib (velocità media e compressione)
- lzma (bassa velocità, alta compressione)
- Backup fuori sede
- Borg può archiviare dati su qualsiasi host remoto accessibile tramite SSH. Se Borg è installato sull’host remoto, è possibile ottenere grandi guadagni in termini di prestazioni rispetto all’utilizzo di un filesystem di rete (sshfs, nfs, …).
- Backup montabili come filesystem
- Gli archivi di backup possono essere montati come filesystem di spazio utente per un facile esame interattivo di backup e ripristini (ad esempio utilizzando un normale file manager).
- Facile installazione su più piattaforme
-
Offriamo binari a file singolo che non richiedono l’installazione di nulla: puoi semplicemente eseguirli su queste piattaforme:
- Linux
- Mac OS X
- FreeBSD
- OpenBSD e NetBSD (nessun supporto per xattr/ACL o binari ancora)
- Cygwin (sperimentale, non ancora binari)
- Sottosistema Linux di Windows 10 (sperimentale)
- Software gratuito e open source
-
- sicurezza e funzionalità possono essere verificate in modo indipendente
- concesso in licenza con la licenza BSD (3 clausole), vedere Licenza per la licenza completa
Perché usare Borg?
Un aspetto cruciale che rende Borg una scelta eccellente per il backup dei dati è la sua funzione di deduplicazione. Questa funzione unica consente a Borg di identificare e memorizzare solo le modifiche apportate alle directory, invece di salvare interamente ogni file o directory modificato. Di conseguenza, Borg può ridurre significativamente la quantità di dati memorizzati, rendendo il processo di backup molto più rapido rispetto ad altre soluzioni di backup.
Per spiegare ulteriormente, immagina di avere due versioni di un file o una directory, con solo una piccola parte di loro che ha subito una modifica. Invece di fare una copia completa del file o della directory, Borg identifica la parte modificata e salva solo quella. Questo risparmia notevolmente lo spazio di archiviazione e accelera il processo di backup.
Oltre alla deduplicazione, Borg offre anche un’opzione per comprimere file e directory. Questo significa che Borg può ridurre ulteriormente la dimensione dei dati prima di memorizzarli. Ancora una volta, questo contribuisce a rendere i backup con Borg estremamente efficienti in termini di spazio, il che è essenziale per la gestione economica e strategica dei dati di un’azienda.
Infine, Borg va oltre la semplice gestione del backup, offrendo anche robuste misure di sicurezza per proteggere i tuoi dati. In particolare, Borg supporta la crittografia dei file lato client. Questo significa che prima che i tuoi dati vengano trasferiti per il backup, Borg li crittografa, rendendoli inaccessibili senza la chiave di crittografia appropriata. Questa funzione è particolarmente utile se prevedi di eseguire il backup su spazi di archiviazione in cloud o su server di cui non ti fidi completamente. Con la crittografia lato client di Borg, puoi essere sicuro che i tuoi dati saranno al sicuro, indipendentemente dalle potenziali vulnerabilità del tuo provider di storage.
Installare BorgBackup
BorgBackup non è installato sui sistemi Linux per impostazione predefinita. Quindi, per iniziare a usare Borg, dovrai prima installarlo. Puoi installare Borg con un solo comando.
sudo apt-get install borgbackup Creare un archivio di backup
Ora che hai installato Borg, iniziamo a eseguire il backup dei tuoi file! Prima che i backup possano essere archiviati, dovrai avviare un repository di backup Borg. Per creare un repository di backup crittografato, è necessario utilizzare il --encryptionflag.
borg init --encryption = repokey /percorso/a/backup_repo Borg ti chiederà di inserire la passphrase che dovrebbe essere utilizzata per crittografare il repository.
Creare un backup
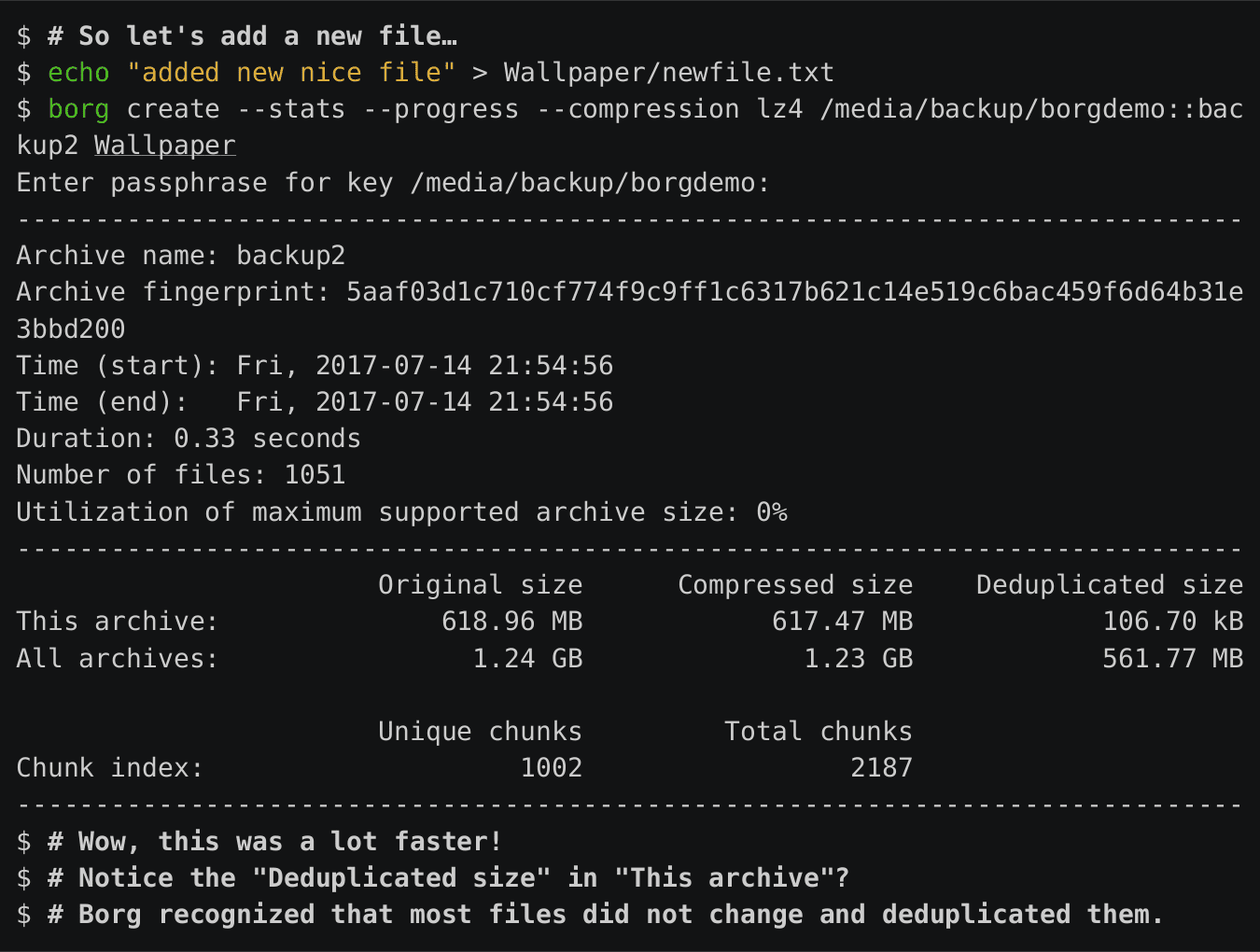
E ora è il momento di creare il nostro primo backup! Puoi creare un backup della directory_origine in un archivio di backup chiamato “archivio1” nel backup_repo:
borg create /percorso/a/backup_repo::archive1 /percorso/a/directory_origine Puoi anche usare il --compressionflag per creare un archivio di backup compresso.
borg create --compression COMPRESSION_ALGORITHM.COMPRESSION_LEVEL /path/to/backup_repo::archive1 /path/to/source_directory Borg ti offre quattro COMPRESSION_ALGORITHM tra cui scegliere lz4, zstd, zlibe lzma. La compressione è lz4di default. COMPRESSION_LEVELpuò variare da 0a 9, 9essendo il più alto. Ad esempio, per utilizzare zlibcon il livello di compressione più alto, puoi eseguire:
borg create --compression zlib,9 /path/to/backup_repo::archive1 /path/to/source_directory Recuperare un backup
Probabilmente vorrai ripristinare un backup ad un certo punto. Per fortuna, recuperare un backup con Borg è altrettanto semplice!
Innanzitutto, puoi elencare tutti gli archivi di backup nel tuo repository di backup.
borg list /percorso/di/backup_repo Borg elencherà tutti gli archivi di backup archiviati nel repository:
archivio1 gio, 23-04-2020 01:20:30
archivio2 ven, 24-04-2020 01:20:30 Puoi anche elencare i contenuti all’interno di un archivio.
borg list /percorso/di/backup_repo::archivio1 Per estrarre un backup e scaricarne i file nella directory corrente, puoi utilizzare:
borg extract /percorso/di/backup_repo::archive1 Prima di estrarre un particolare file di archivio, potresti voler confrontare diversi archivi per trovare la versione giusta che desideri utilizzare. Puoi confrontare gli archivi senza estrarli usando:
borg diff /percorso/di/backup_repo::archivio1 archivio2 Puoi usare Borg anche per operare su una directory di backup remota. Tutta la sintassi sarebbe la stessa, ma dovrai specificare il nome utente e il server nel percorso del repository di backup.
borg extract username@server:/path/to/backup_repo::archive1 Montare un repository di backup
Infine, se non sai quali file vuoi ripristinare e devi esaminare i file, puoi montare un archivio o l’intera directory di backup. Ciò ti consentirà di sfogliare l’archivio e ripristinare i singoli file.
Per montare una directory remota, devi prima creare una directory locale scrivibile. Quindi, puoi andare avanti e montare il repository.
mkdir /tmp/mountborg mount nomeutente@server:/percorso/a/backup_repo /tmp/mount
Dopo aver finito di operare sul repository di backup, puoi smontarlo:
borg smonta /tmp/monta Conclusione
In conclusione, Borg Backup rappresenta una soluzione avanzata e altamente efficiente per il backup dei dati. Grazie alle sue funzionalità uniche, tra cui la deduplicazione basata sul chunking definito dal contenuto, la compressione dei dati e la crittografia lato client, Borg può fornire un backup rapido, sicuro e risparmioso in termini di spazio.
Nel corso di questo post, abbiamo esplorato in profondità molte delle funzioni principali di Borg, offrendo un’analisi dettagliata del suo funzionamento e del suo valore. Tuttavia, questo non esaurisce tutto ciò che Borg può offrire. Con una serie di altre funzionalità e opzioni personalizzabili, Borg può essere adattato per rispondere a una vasta gamma di esigenze di backup.
Se mai dovessi avere bisogno di assistenza con Borg, ricorda che esistono molte risorse disponibili per aiutarti. Puoi ottenere aiuto direttamente dal terminale usando il comando ‘borg help’, che fornirà una guida sulle funzioni e i comandi disponibili. In alternativa, puoi visitare la pagina della documentazione di Borg per ottenere informazioni più dettagliate e approfondite.
In definitiva, Borg è un modo efficace, flessibile e sicuro per eseguire il backup dei tuoi dati. Che tu stia cercando di proteggere i dati critici della tua azienda o di garantire la sicurezza dei tuoi file personali, Borg offre una soluzione che vale la pena considerare.